X-Decoder kann eine Vielzahl von Bildverarbeitungs- und Bildsprachaufgaben übernehmen. Die Technik könnte spezialisierte KI-Modelle ablösen.
Im Feld des visuellen Verstehens gibt es zahlreiche spezialisierte KI-Modelle, die Bilder auf unterschiedlichen Granularitätsebenen analysieren und ganz unterschiedliche Aufgaben wie die Bildklassifizierung, Bildbeschriftung oder Objekterkennung erfüllen.
In den vergangenen Jahren, angetrieben durch den Erfolg der 2017 vorgestellten Transformer-Architektur, geht der Trend hin zur Entwicklung von Allzweckmodellen, die auf zahlreiche Bildverarbeitungs- und Bildsprachaufgaben angewandt werden.
Laut Forschenden der University of Wisconsin-Madison, der UCLA und von Microsoft konzentriert sich ein Großteil der Methoden dabei jedoch auf das Verarbeiten auf Bild- oder Bildregionsebene und nicht auf das Verstehen auf Pixelebene. Ansätze, die sich auf die Pixelebene konzentrieren, seien dagegen auf spezifische Aufgaben zugeschnitten und konnten bislang nicht generalisiert werden.
X-Decoder bringt nahtlose Segmentierung auf Pixelebene
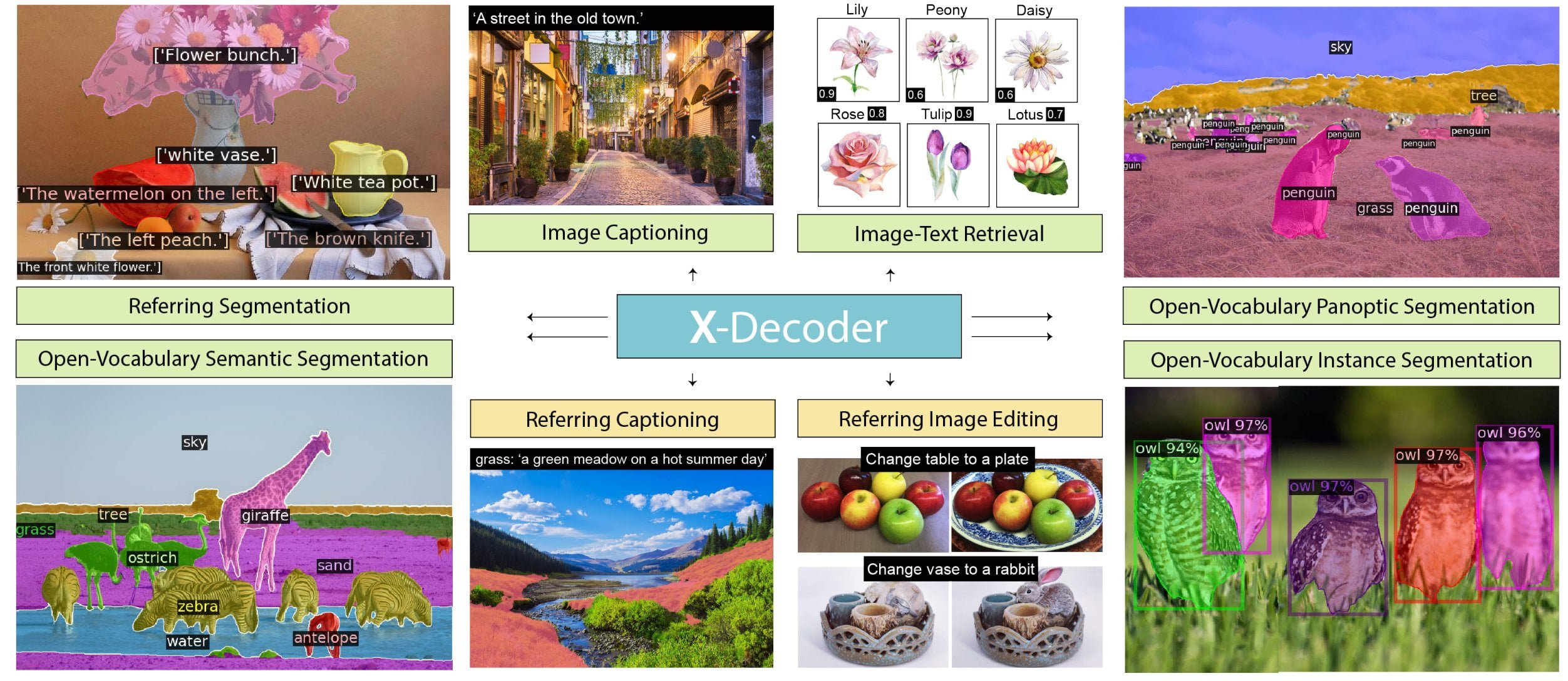
Das Team stellt X-Decoder vor, einen generalistischen Decoder, der Bilder auf allen Granularitätsebenen verarbeiten kann und zahlreiche Bildverarbeitungs- und Bildsprachaufgaben leistet, darunter etwa die Bildsegmentierung auf Pixelebene oder Bildbeschreibungen. X-Decoder kann zudem mit generativen KI-Modellen wie Stable Diffusion kombiniert werden. In diesem Szenario ermöglicht es eine pixelgenaue Bildbearbeitung.
X-Decoder ist im Kern ein Bild-Modell mit Transformer-Encoder, das mit einem Datensatz von mehreren Millionen Bild-Text-Paaren sowie einer begrenzten Anzahl von Segmentierungsdaten trainiert wurde. Als Input können ein Bild-Encoder und ein Text-Encoder dienen. Das Modell kann zwei Arten von Output ausgeben: Masken auf Pixelebene und Semantik auf Token-Level, also etwa Text-Beschreibungen.

Mit der Kombination aus verschiedenen Input- und Output-Möglichkeiten kann X-Decoder die unterschiedlichen Aufgaben übernehmen. Die Verwendung eines einzigen Text-Encoders erleichtere zudem die Synergie zwischen Aufgaben, so das Team.
X-Decoder zeigt beeindruckende Leistung
X-Decoder zeige eine starke Transferleistung bei zahlreichen Aufgaben, sowohl in Zero-Shot-, als auch in Szenarien mit Nachtraining. So erreiche X-Decoder Bestleistungen in einigen besonders schweren Segmentierungsaufgaben, etwa der referenzierenden Segmentierung.
Zudem biete das KI-Modell bessere oder konkurrenzfähige Leistung zu anderen generalistischen und spezialisierten Modellen im Nachtraining. X-Decoder sei zudem so flexibel, dass es auch neuartige Aufgaben wie die referenzierende Beschriftung, also die referenzierende Segmentierung plus Beschriftung, erfüllen könne.
Wir stellen X-Decoder vor, ein Modell, das nahtlos das Verstehen von Bildsprache auf Pixel- und Bildebene unterstützt. Mit einem einfachen und verallgemeinerten Design kann X-Decoder mühelos allgemeine Segmentierungs-, Referenzsegmentierungs- und VL-Aufgaben vereinen und unterstützen, wobei eine starke Verallgemeinerbarkeit und eine konkurrenzfähige oder sogar SoTA-Leistung erreicht wird. Wir hoffen, dass diese Arbeit ein Licht auf das Design der nächsten Generation von Allzweck-Vision-Systemen werfen kann.
Aus dem Paper.
Mehr Informationen gibt es auf der GitHub-Seite von X-Decoder. Den Code gibt es ebenfalls auf GitHub.