Zwei Bücher reichen, um Sprachmodelle auf den Stil eines Autors zu trainieren

Forschende haben herausgefunden, dass KI-Systeme, die gezielt auf einzelne Schriftsteller trainiert werden, Texte produzieren, die Leser besser finden als die Imitationen professioneller Autor:innen. Das könnte Folgen für laufende Rechtsstreitigkeiten haben.
Wissenschaftler:innen der Stony Brook University und Columbia Law School ließen professionelle Schreiber:innen und drei KI-Systeme Texte im Stil von 50 berühmten Autor:innen verfassen, darunter Nobelpreisträger:innen wie Han Kang und Booker-Prize-Gewinner:innen wie Salman Rushdie. 159 Testpersonen bewerteten die Texte, ohne zu wissen, wer sie geschrieben hatte.

Die Forscher:innen teilten die Testpersonen in zwei Gruppen auf: 28 Expert:innen aus Schreibprogrammen sowie 131 Laienleser:innen von der Crowdsourcing-Plattform Prolific.
Beim In-Context-Prompting verwendeten die Wissenschaftler:innen alle drei KI-Modelle (GPT-4o, Claude 3.5 Sonnet und Gemini 1.5 Pro) mit identischen Anweisungen und Beispieltexten. Für das spezielle Fine-Tuning konnten sie nur GPT-4o nutzen, da nur dieses Modell die nötige API-Funktionalität unterstützte. Dafür kauften sie digitale Versionen aller verfügbaren Bücher von 30 der 50 Autor:innen und trainierten darauf separate Modelle.
Die Bewertung erfolgte in verblindeten Paarvergleichen, bei denen die Leser:innen jeweils zwei Texte vorgelegt bekamen und sich für den besseren entscheiden mussten. Für die Stilbewertung erhielten sie zusätzlich einen Originaltext des jeweiligen Autors als Referenz. Jeder Text wurde von mehreren Leser:innen bewertet, um die Ergebnisse statistisch abzusichern.
Detektoren schlagen nicht an
Das Ergebnis hing entscheidend von der KI-Methode ab. Bei dem simpleren In-Context-Prompting bevorzugten insbesondere die professionellen Leser:innen klar die menschlichen Texte, während die Laien gemischte Ergebnisse zeigten.
Nach dem gezielten Training bevorzugten die Expert:innen die KI-Texte achtmal häufiger bei der Stilnachahmung und doppelt so häufig bei der Schreibqualität. Moderne KI-Erkennungssoftware identifizierte 97 Prozent der Standard-generierten Texte als maschinell, aber nur drei Prozent der speziell trainierten.
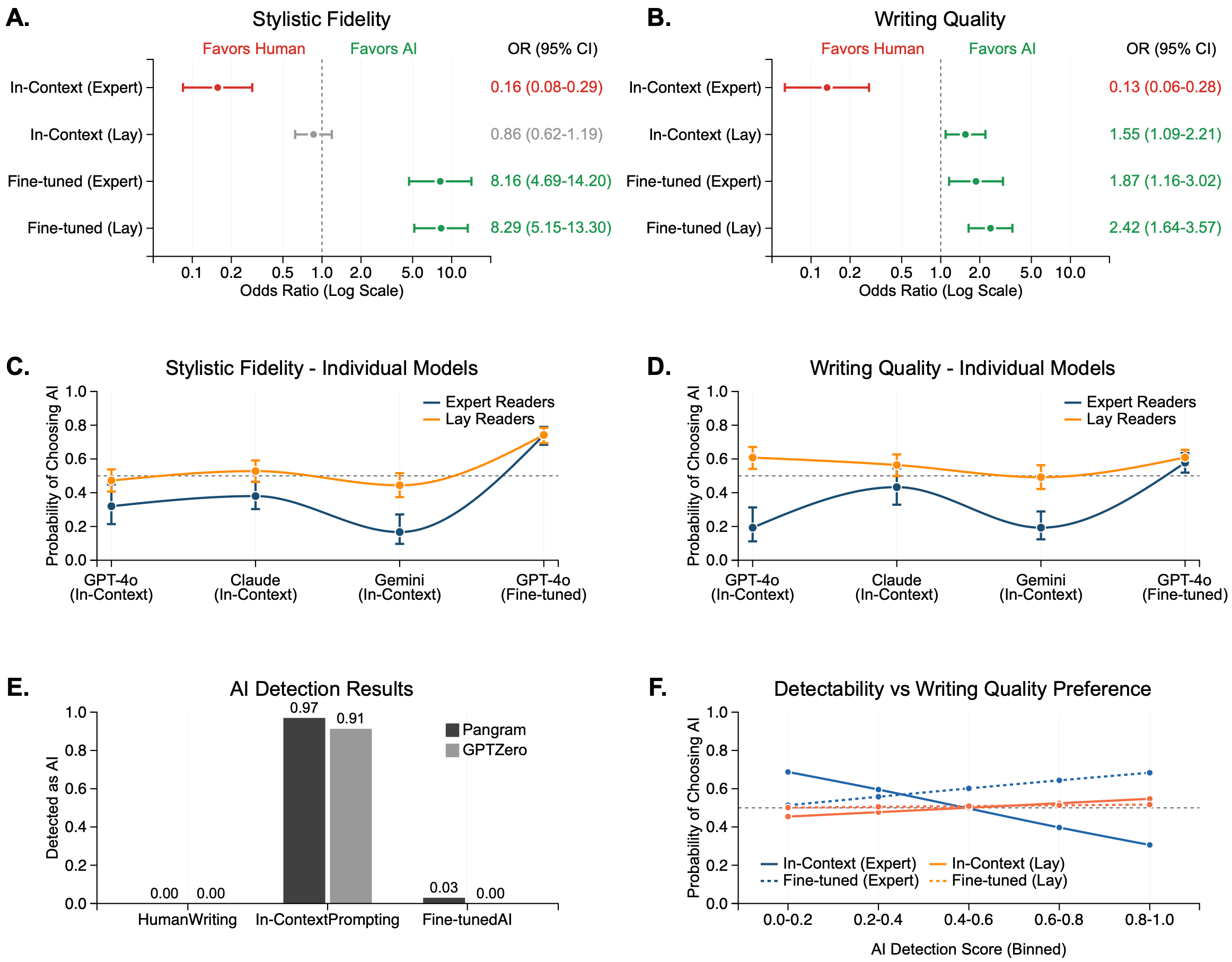
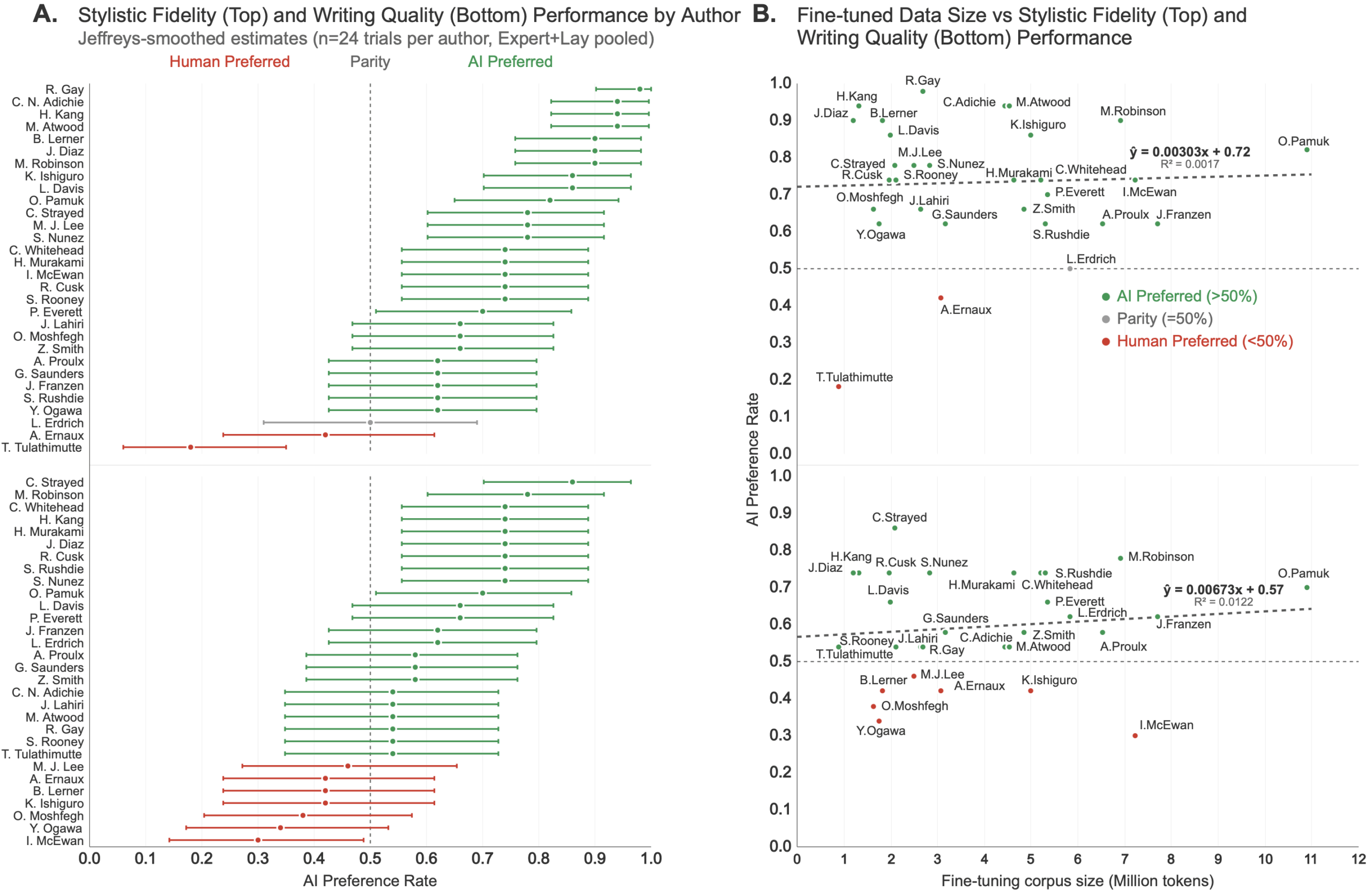
Besonders bemerkenswert war, dass die Leistung der KI-Modelle nicht von der Menge des verfügbaren Trainingsmaterials abhing. Autor:innen wie Tony Tulathimutte mit nur zwei veröffentlichten Büchern konnten genauso erfolgreich nachgeahmt werden wie Haruki Murakami mit mehr als 20 Werken.
Die Studie deckte auch auf, dass Expert:innen und Laienleser:innen unterschiedlich auf KI-Texte reagieren. Während Expert:innen bei Standard-generierten Texten eine hohe Übereinstimmung in ihren negativen Bewertungen zeigten, waren Laienleser:innen bereits bei dieser einfacheren KI-Methode weniger kritisch. Nach dem speziellen Training näherten sich die Bewertungen beider Gruppen stark an, was darauf hindeutet, dass die verbesserte KI-Qualität auch für Fachleute überzeugend war.
Der Grund ist laut den Forschenden, dass standardmäßige KI-Texte Klischees enthalten und künstlich höflich wirken. Das spezielle Training beseitige diese Merkmale weitgehend.
Die wirtschaftlichen Auswirkungen könnten dramatisch sein. Das Training kostete etwa 81 Dollar pro Autor:in, während Professionelle für die gleiche Textmenge 25.000 Dollar verlangen würden. Das entspricht einer Kostenreduktion von 99,7 Prozent, auch wenn die KI-Texte noch menschliche Überarbeitung benötigen.
Illegale Buchbeschaffung als Trainings-Grundlage
Die Studie hat direkten Bezug zu laufenden Rechtsstreitigkeiten zwischen Autoren und KI-Unternehmen. Im Verfahren gegen Anthropic stellte sich heraus, dass das Unternehmen mindestens sieben Millionen Bücher von illegalen Plattformen wie LibGen und Pirate Library Mirror beschafft hatte. Die Bücher wurden eingescannt und die Originale weggeworfen.
Die Forschungsergebnisse könnten dem Paper zufolge rechtlich entscheidend werden. Ein zentraler Punkt im US-Urheberrecht hinsichtlich der "Fair-Use-"Debatte ist, ob KI-Nutzung den Markt für ursprüngliche Werke schädigt. Wenn Leser:innen KI-Nachahmungen den menschlich geschriebenen Imitationen vorziehen, spreche das klar für Marktschädigung.
Die US-Urheberrechtsbehörde hat bereits das Konzept der "Marktverdrängung" anerkannt. KI-Systeme könnten Märkte mit konkurrierenden Werken überfluten, auch ohne die Originale wörtlich zu kopieren.
Die Forschenden schlagen vor, zwischen allgemeinen KI-Systemen und autorenspezifischen Modellen zu unterscheiden. Für gezielte Nachahmungen von Autor:innen sehen sie kaum rechtliche Rechtfertigungen. Als Lösungen schlagen sie vor, KI-Systemen das Nachahmen einzelner Autor:innen generell zu verbieten oder KI-Texte verpflichtend zu kennzeichnen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.