1.000 KI-Agenten simulieren menschliches Verhalten in Experimenten erstaunlich genau

Ein Team von Forschenden der Universitäten Stanford und Washington sowie von Google DeepMind hat einen neuartigen Ansatz entwickelt, um menschliches Verhalten und Einstellungen mit KI-Agenten zu simulieren.
Laut der Studie könnten solche Simulationen als Labor dienen, um Theorien in Bereichen wie Wirtschaft, Soziologie, Organisationen und Politikwissenschaft zu testen.
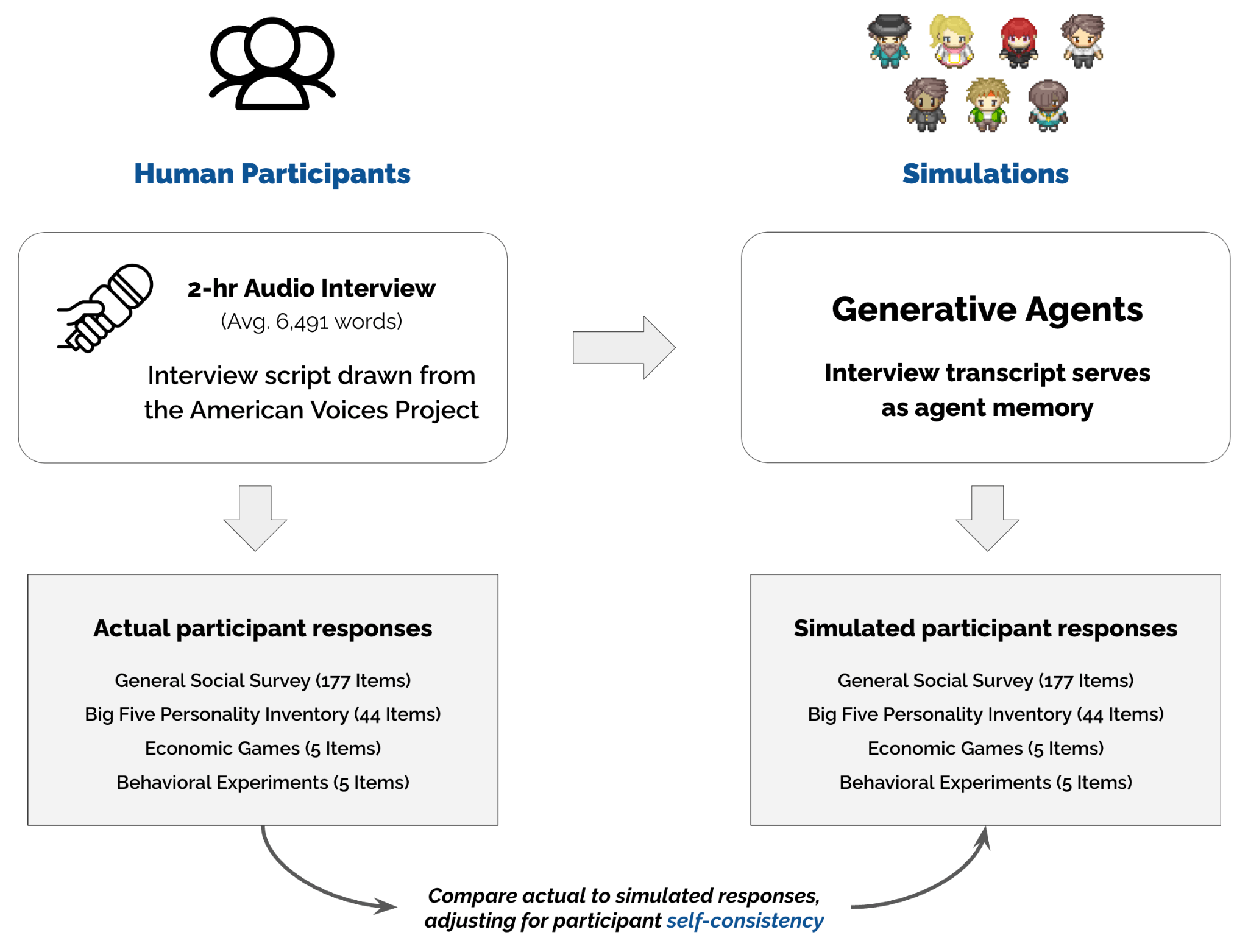
Die Forschenden rekrutierten über 1.000 Teilnehmende, die die US-Bevölkerung in Bezug auf Alter, Geschlecht, Bildung und politische Ideologie repräsentieren sollten. Alle absolvierten ein zweistündiges Interview mit einem KI-Interview-Agenten, das mit OpenAIs Open-Source-Modell Whisper in transkribiert wurde.
KI-Agenten kombinieren Interviews mit Sprachmodellen
Basierend auf den Interviewtranskripten und GPT-4o als Sprachmodell entwickelten die Forschenden eine neue Architektur für generative Agenten. Wird ein Agent abgefragt, wird das gesamte Interviewtranskript in den Modell-Prompt eingefügt und so angewiesen, die Person auf Basis ihrer Interviewdaten zu imitieren.
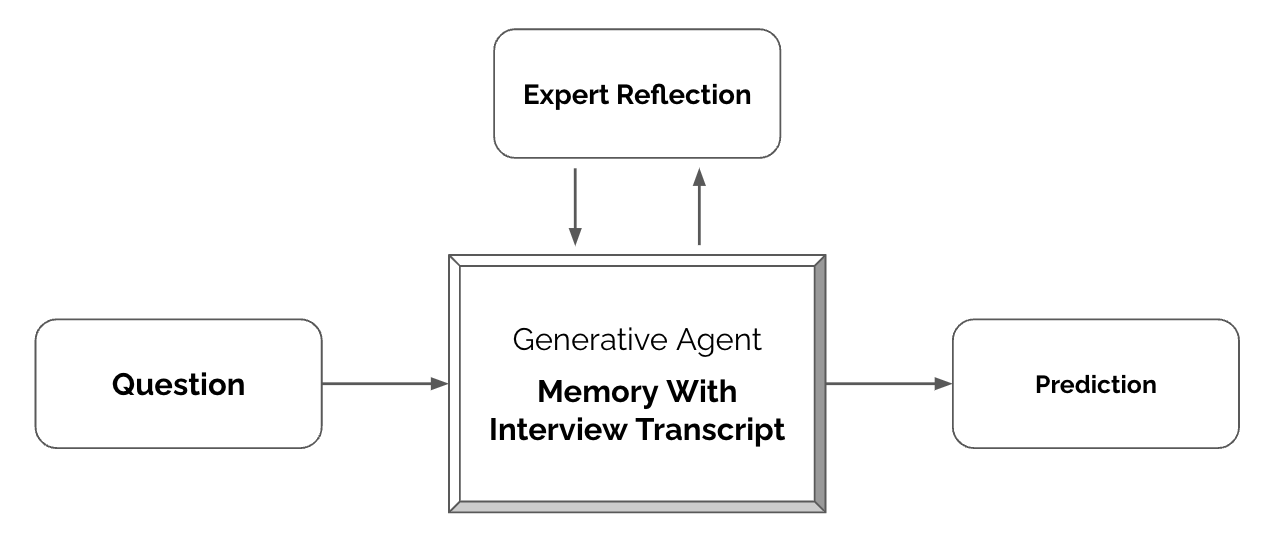
Die Forschenden bewerteten die Agenten danach, wie gut sie die Antworten der Teilnehmenden in Umfragen und Experimenten vorhersagen können.
Dazu gehörten Fragen aus dem General Social Survey (GSS), dem Big-Five-Modell, fünf bekannten verhaltensökonomischen Spielen und fünf sozialwissenschaftlichen Experimenten mit Kontroll- und Behandlungsbedingungen.
Interview-basierte Agenten übertreffen demografische Agenten
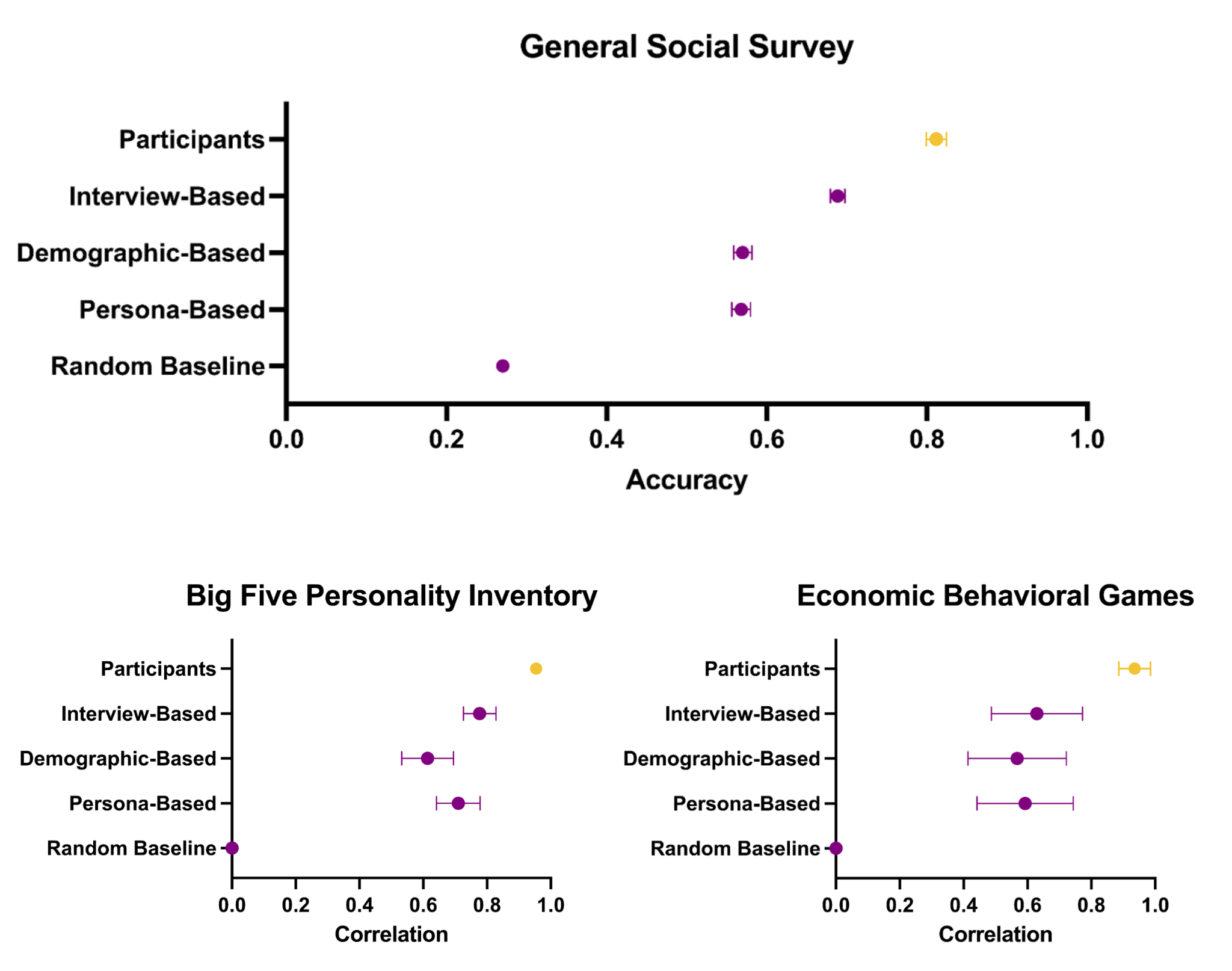
Die interview-basierten Agenten sagten die GSS-Antworten der Teilnehmenden mit einer normalisierten Genauigkeit von 0,85 voraus und übertrafen damit deutlich Agenten, die nur auf demografischen Informationen oder Personenbeschreibungen basierten.
Auch bei den Big-Five-Persönlichkeitsmerkmalen und den ökonomischen Spielen erzielten die interview-basierten Agenten eine höhere Vorhersagegenauigkeit.
In den Replikationsstudien replizierten sowohl die menschlichen Teilnehmenden als auch die generativen Agenten die Ergebnisse von vier der fünf Studien erfolgreich. Die von den Agenten geschätzten Effektgrößen korrelierten stark mit denen der Teilnehmenden (r = 0,98).
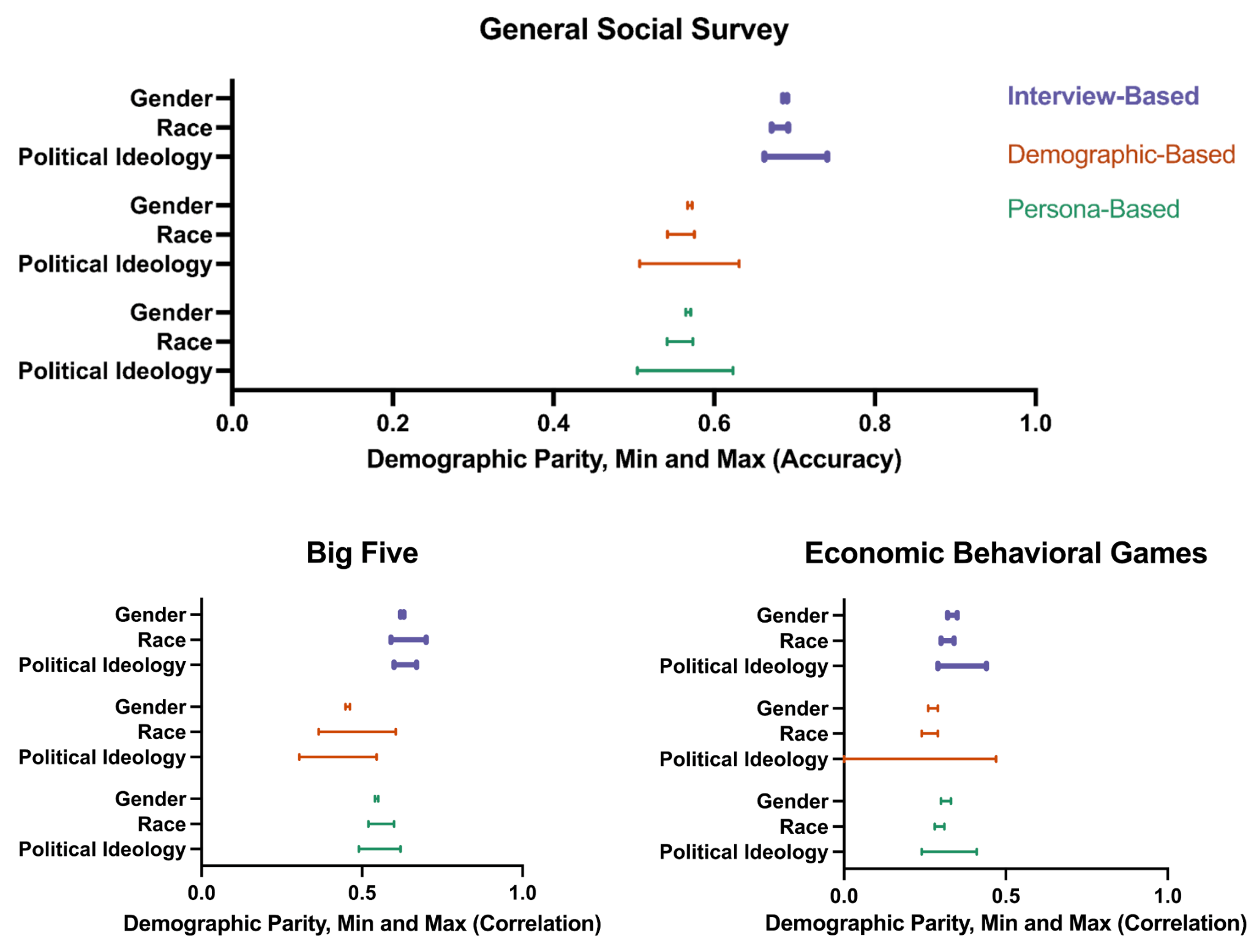
Eine Analyse von Untergruppen zeigte zudem, dass interview-basierte Agenten Verzerrungen in Bezug auf politische Ideologie und ethnische Zugehörigkeit im Vergleich zu demografiebasierten Agenten verringern.
Forschungszugang zum Agenten-Datensatz
Die Forschenden stellen auf GitHub einen Agenten-Datensatz mit 1.000 generativen Agenten für die Forschung zur Verfügung. Um wissenschaftliches Potenzial und Datenschutzbedenken auszubalancieren, bieten sie ein zweigleisiges Zugriffssystem: einen offenen Zugang zu aggregierten Antworten bei festgelegten Aufgaben und einen eingeschränkten Zugang zu individualisierten Antworten bei offenen Aufgaben.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.