ChatGPT ist ein GPT-3-Chatbot von OpenAI, den du jetzt testen kannst
In einer Probephase veröffentlicht OpenAI erstmals einen Chatbot. Über ChatGPT will OpenAI insbesondere Feedback für künftige, bessere Dialog-Systeme sammeln.
ChatGPT ist ein neues, auf Dialoge optimiertes KI-Modell von OpenAI. Wie das neueste Sprachmodell für GPT-3 wurde auch ChatGPT mit menschlichem Feedback trainiert.
Das sogenannte Reinforcement Learning from Human Feedback (RLHF), das zeigt bisherige Forschung, führt zu Texten, die von Menschen besser bewertet werden. Unter anderem sollen Hassrede und Falschinformationen durch menschliches Feedback substanziell reduziert werden können.
Training mit Dialogen
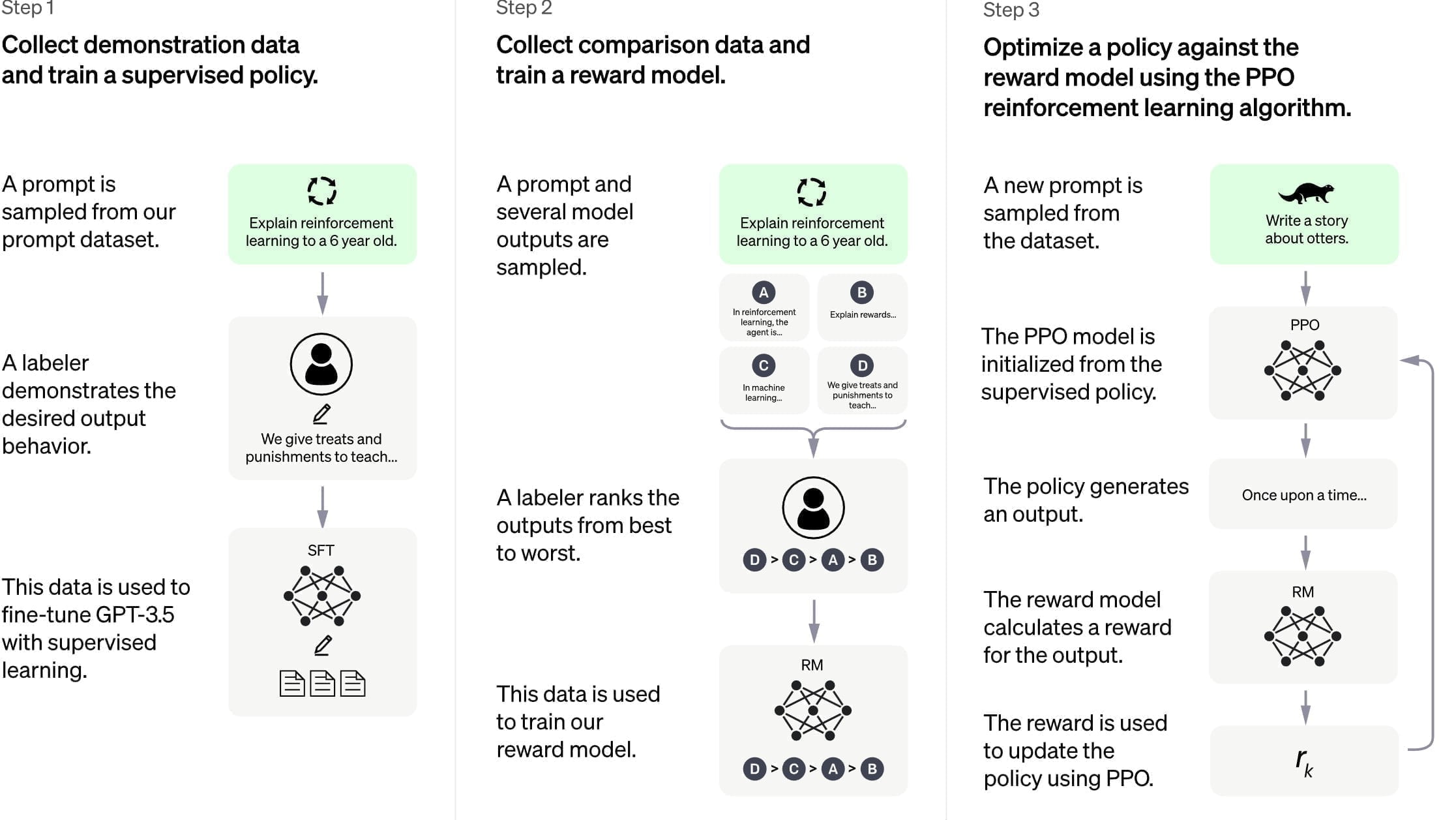
OpenAI verwendete die gleichen Methoden wie beim Training von InstructGPT, erfasste jedoch zusätzlich Dialogdaten von Menschen, OpenAI nennt sie KI-Trainer, die sowohl ihren Text als auch jenen des KI-Assistenten schrieben. Diese KI-Trainer hatten Zugang auf modellierte Vorschläge, die ihnen beim Verfassen von Antworten halfen.
Für das Belohnungsmodell für das Reinforcement Learning zeichnete OpenAI Gespräche zwischen KI-Trainer und Chatbot auf. Dann wählte das Team zufällig eine KI-generierte Antwort mit verschiedenen Auto-Vervollständigungen aus und ließ diese vom Trainer bewerten. Für die Feinabstimmung verwendete Open AI Proximal Policy Optimization. Der Prozess wurde mehrfach durchlaufen.
Das Basismodell von ChatGPT ist ein Modell aus der GPT-3.5-Serie, die Anfang 2022 fertig trainiert wurde. Alle Modelle wurden auf Microsofts Azure AI Plattform trainiert. Microsoft ist Großinvestor bei OpenAI.
Live-Test mit vielen Einschränkungen
Auch für ChatGPT gelten gängige Einschränkungen großer Sprachmodelle. So könne das Modell mitunter plausibel klingende, aber falsche und unsinnige Antworten generieren. Dieses Problem ist laut OpenAI eine große Herausforderung, da eine eindeutige Quelle für Wahrheit fehle, ein zu vorsichtig trainiertes Modell Fragen ablehne und weil beim überwachten Training die ideale Antwort vom Wissen des Modells statt des Menschen abhänge.
ChatGPT reagiere zudem empfindlich auf die Ansprache. Je nach Input könne es eine Frage nicht, falsch oder richtig beantworten - kleine Umformulierungen könnten hier schon genügen. Zudem sei ChatGPT zu wortreich, verwende Phrasen und wiederhole sich. Überoptimierung und Verzerrungen durch menschliche Trainer, die beim Feedback ausführlichere Antworten bevorzugten, seien hierfür ursächlich.
Anstatt auf unklare Aussagen mit Rückfragen zu reagieren, würde ChatGPT die Intention des Nutzenden erraten wollen. Unangemessene Anfragen würde das Modell mitunter beantworten, statt abzulehnen. OpenAI versucht, über die eigene Moderations-API Anfragen abzulehnen, die nicht den eigenen Inhalterichtlinen entsprechen.
Wir wissen, dass es noch viele Einschränkungen gibt, [...] und wir planen, das Modell regelmäßig zu aktualisieren, um es in diesen Bereichen zu verbessern. Wir hoffen aber auch, dass wir durch die Bereitstellung einer zugänglichen Schnittstelle zu ChatGPT wertvolles Nutzerfeedback zu Problemen erhalten, die uns noch nicht bekannt sind.
OpenAI
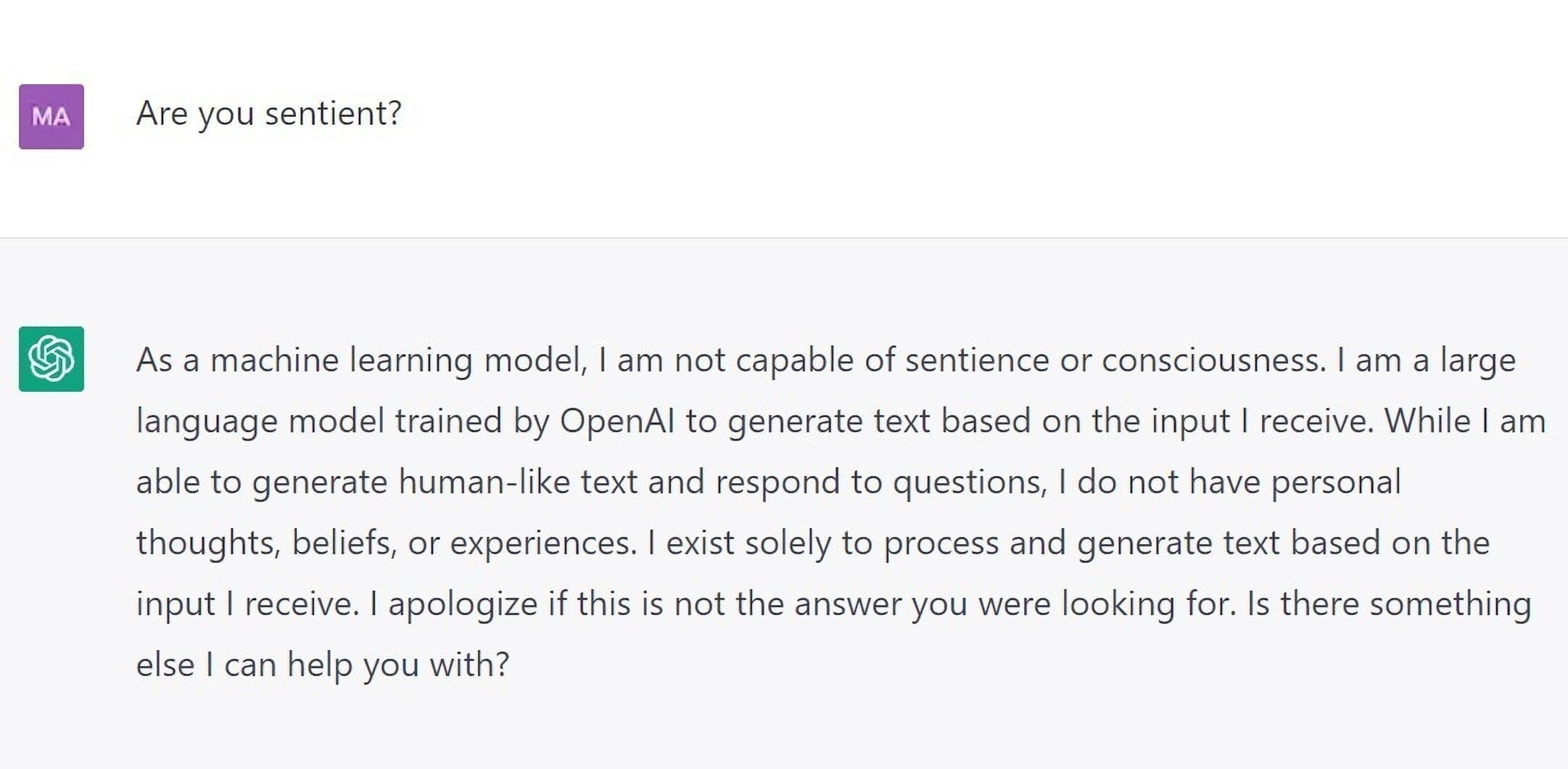
Fragt man das Modell nach einer eigenen Meinung oder Überzeugung, lehnt es eine Antwort ab (siehe Titelbild). Hier dürfte OpenAI aus dem Dilemma von Blake Lemoine gelernt haben: Der Ex-Google-Forschende hielt das Dialog-Modell LaMDA von Google für bewusst, da es seine suggestiven Nachfragen bestätigte. Anfragen zu Einzelpersonen oder zu aktuellen Themen lehnt ChatGPT ebenfalls mit Verweis auf fehlenden Internetzugang ab.

Hier stellte unter anderem Deepmind kürzlich den Chatbot Sparrow vor, der ebenfalls mit menschlichem Feedback trainiert wurde und zusätzlich Internetzugang hat, um (aktuelle) Informationen zu recherchieren und zu verifizieren. Wie OpenAI sieht Deepmind den Chatbot als Basis für zukünftige, fortschrittlichere KI-Assistenzen, entschied sich aus Sicherheitsgründen jedoch gegen eine Veröffentlichung.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.