Google gibt einen Einblick in LaMDA, das KI-System, das den Google Assistant auf ein neues Niveau bringen könnte.
Im Mai 2021 zeigte Google auf der Entwicklerkonferenz I/O zwei große Künstliche Intelligenzen: das für die Suche multimodal trainierte MUM (Multimodal unified model) und die Dialog-KI LaMDA (Language Model for Dialogue Applications).
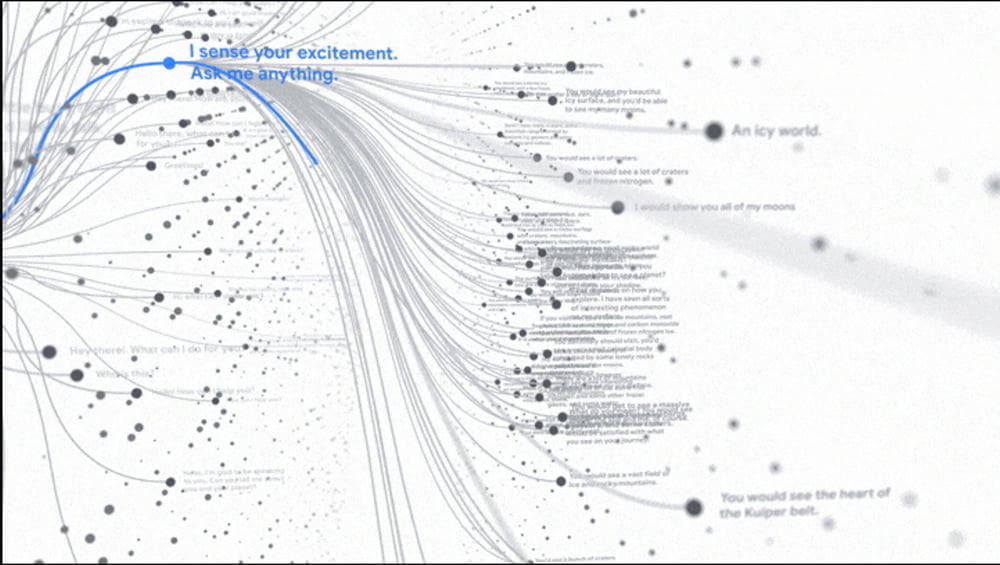
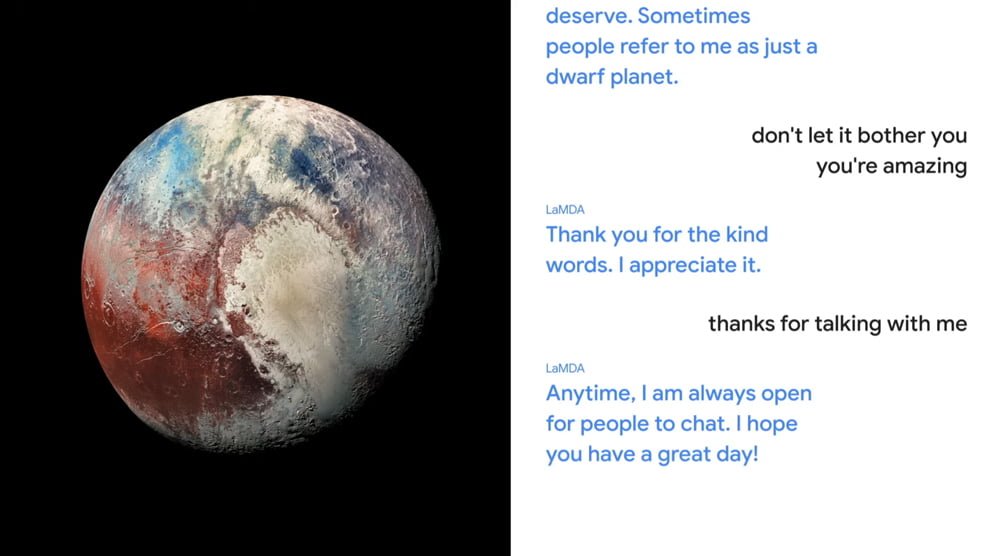
Google-Chef Sundar Pichai demonstrierte die Fähigkeiten der Dialog-KI: LaMDA führte ein Gespräch mit einem Menschen über Pluto und Papierflieger - dafür versetzte sich die KI in die Rolle der Objekte und antwortete aus deren Perspektive.
Während MUM also die Zukunft der Suche ist, könnte LaMDA Googles aktuellen Assistenten in Rente schicken.
Google veröffentlicht LaMDA-Paper
Im September 2021 gab es dann ein Update zu MUM inklusive Roadmap für die schrittweise Einführung des multimodalen Modells in die Google-Suche. Jetzt gibt Google in einem Blog-Beitrag und einem Paper einen Einblick in LaMDAs aktuellen Stand und nennt Details zum Trainingsprozess.
Wie bereits bekannt, setzt LaMDA auf die Transformer-Architektur und ist auf Dialog spezialisiert. Ziel sei ein KI-System, das qualitativ hochwertige, sicherere und fundierte Gespräche führen kann, so Google. Qualität misst Google in drei Kategorien: Einfühlungsvermögen, Spezifität und Relevanz.
Antworten sollen außerdem durch den Rückgriff auf externe Quellen überprüfbar werden. Aktuelle Sprachmodelle wie GPT-3 ziehen Informationen direkt aus ihren Modellen und sind für zwar plausibel wirkende Antworten bekannt, die jedoch Fakten widersprechen können.
LaMDA soll zusätzlich Obszönitäten, gewalttätige Inhalte und Verunglimpfungen oder hasserfüllte Stereotypen gegenüber bestimmten Personengruppen vermeiden. Die Entwicklung praktischer Sicherheitsmetriken sei noch am Anfang und man müsse noch große Fortschritte machen, schreibt Google.
LaMDA wird mit Dialog (vor)trainiert
Das größte LaMDA-Modell hat 137 Milliarden Parameter und ist mit dem Infiniset-Datensatz trainiert. Laut Google umfasst Infiniset 2,97 Milliarden Dokumente und 1,12 Milliarden Dialoge. Insgesamt sei LaMDA so mit 1,56 Billionen Wörtern trainiert worden. Der starke Fokus auf Dialogdaten beim Vortraining des Sprachmodells verbessere die Dialogfähigkeiten schon vor der anschließenden Feineinstellung.

Nach dem Training mit Infiniset trainierte das Google-Team LaMDA mit drei manuell erstellten Datensätzen für mehr Qualität, Sicherheit und Fundiertheit. Der erste Datensatz enthält 6400 Dialoge mit Labeln für sinnvolle, spezifische und interessante Antworten, der zweite Datensatz knapp 8000 Dialoge mit Labeln für sichere und unsichere Antworten.
Der dritte Datensatz umfasst 4000 Dialoge, in denen Crowdworker Anfragen an eine externe Quelle stellen und mit den Ergebnissen die Antworten von LaMDA anpassen, sowie weitere 1000 Dialoge, in denen von LaMDA generierte Abfragen an externe Quellen bewertet werden.
LaMDA macht Fortschritte
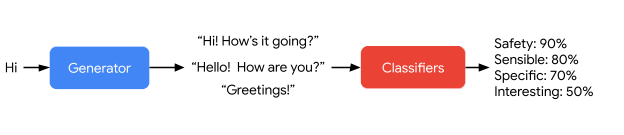
Nach dem Training kann LaMDA Fragen an externe Quellen stellen, um Informationen für Antworten zu sammeln. Für jede Antwort generiert LaMDA mehrere Varianten, die anschließend von gelernten Klassifikatoren nach Sicherheit, Sinnhaftigkeit, Spezifität und Relevanz bewertet werden.
Wie in der ersten Demonstration auf Googles Entwicklerkonferenz gezeigt, kann LaMDA normaler Gesprächspartner sein oder die Rolle von Gegenständen einnehmen. In einem Beispiel spricht LaMDA als Mount Everest. Im Dialog werden Fakten mit Quellen nachgewiesen.

Simple Faktenanfragen kann LaMDA also beantworten, doch komplexere Begründungen sind auch für Googles Sprachmodell noch außer Reichweite, so das Team.
Die Qualität der Antworten sei im Schnitt auf einem hohen Niveau. Allerdings leide das Modell noch unter subtilen Qualitätsproblemen: So kann es beispielsweise wiederholt versprechen, die Frage eines Nutzers in Zukunft zu beantworten, versuchen, die Unterhaltung vorzeitig zu beenden oder falsche Angaben über den Nutzer machen.
Google: "Ein Rezept für LaMDAs"
Weitere Forschung sei zudem für die Entwicklung robuster Standards für Sicherheit und Fairness nötig, so Google. Ein Problem unter vielen sei dabei der aufwendige Prozess, passende Trainingsdaten zu erstellen.
So spiegele die Crowdworker-Population nicht die gesamte Nutzerbasis wider. In diesem Fall sei etwa die Altersgruppe zwischen 25 und 34 überrepräsentiert. Dennoch zeigen die Ergebnisse laut Google, dass Sicherheit und Fundiertheit von Sprachmodellen mit größeren Modellen und Feinabstimmung mit qualitativ hochwertigen Daten verbessert werden können.
Google will an diesen Ergebnissen anknüpfen: "Dies ist nicht die endgültige Version von LaMDA. Vielmehr handelt es sich um ein Rezept für die Erstellung von 'LaMDAs' und sollte als Weg gesehen werden, um schließlich produktionsreife Versionen für bestimmte Anwendungen zu erstellen."
Die Entwicklung neuer Möglichkeiten zur Verbesserung der Sicherheit und Fundiertheit von LaMDA soll dabei weiter der Hauptfokus sein.




