Deepminds neue Spiele-KI soll ein Game-Changer in der echten Welt werden

Deepminds KI-System "DeepNash" meistert das komplexe Brettspiel Stratego. Für Deepminds Forschungsteam ist DeepNash ein mögliches Sprungbrett für KI, die komplexe Alltagssituationen meistern kann.
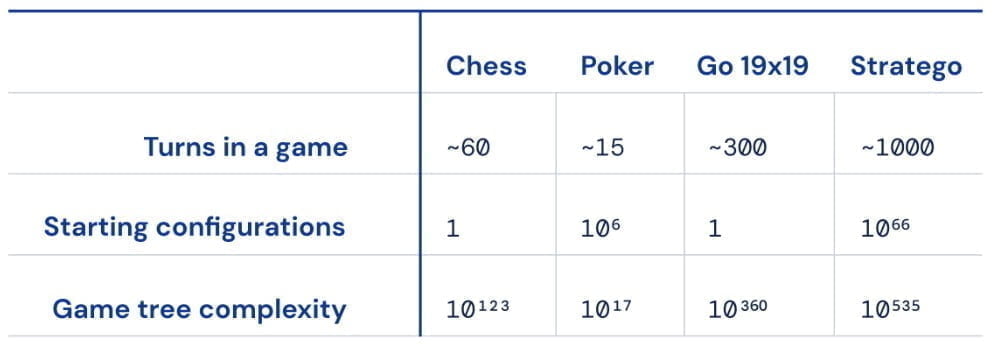
Das rundenbasierte Eroberungsspiel Stratego ist enorm komplex, viel komplexer als die schon von Deepmind gemeisterten Brettspiele Schach und Go, da es deutlich mehr Spielzüge erfordert und verdeckt gespielt wird. Viele für den Spielverlauf relevante Informationen sind nicht bekannt - anders als bei Schach oder Go, wo alle Spieler:innen auf das gleiche Spielfeld blicken.
Zwar meisterten Meta-KI-Forscher schon 2019 mit Pluribus das ebenfalls verdeckt gespielte Poker. Jedoch ließen sich die dort angewandten Techniken nicht auf das viel längere Stratego übertragen, das häufig hunderte Züge bis zum Spielende benötigt.
Bisher galt Stratego daher als große Herausforderung in der KI-Forschung, die bislang nur auf Amateurlevel gelöst werden konnte. DeepNash ändert das.

DeepNash schlägt verlässlich menschliche Profis
DeepNash konnte in Stratego 97 Prozent der Spiele gegen andere Computersysteme und 42 (84 Prozent) von 50 Online-Duellen gegen Menschen für sich entscheiden. Dabei sicherte es sich im April einen Platz in der seit 2002 geführten Top-3-Bestenliste der Stratego Online-Plattform Gravon.
Deepminds Forschungsteam wertet diesen Erfolg als wichtigen Schritt hin zu KI-Systemen, die komplexe Situationen mit unbekannten Informationen in der echten Welt besser meistern können.
Die Spiele-KI, genauer, die für ihre Entwicklung erfundenen Methoden, hätten das Potenzial, ein "Game-Changer" in der echten Welt zu werden. Sie könnten zur Lösung von Problemen beitragen, die durch unvollkommenes Wissen und unvorhersehbare Szenarien gekennzeichnet seien, etwa die Optimierung des Verkehrsmanagements zur Verringerung der Fahrzeiten und der Fahrzeugemissionen.
Durch die Schaffung eines verallgemeinerbaren KI-Systems, das angesichts der Ungewissheit robust ist, hoffen wir, die Problemlösungsfähigkeiten der KI weiter in unsere von Natur aus unvorhersehbare Welt zu bringen.
Deepmind
Für ein solches KI-Training wäre allerdings noch immer eine komplexe Simulation von Alltagsszenarien nötig, ein noch weitgehend ungelöstes Problem.
DeepNash lernt Nash-Gleichgewicht
Anders als bei früheren KI-Systemen, etwa für Schach oder Go, setzte Deepmind bei DeepNash nicht mehr auf die gängige Monte-Carlo-Baumsuche. Diese Methode könne die Komplexität von Stratego wegen der schieren Masse an Zügen und den vielen verborgenen Informationen nicht beherrschen.
Statt auf Suchtechnik setzte Deepmind auf einen modellfreien KI-Trainingsansatz, bei dem das System ohne menschliche Vorgabe allein im Spiel gegen sich selbst lernt. Deepmind verwendete den Algorithmus "Regularised Nash Dynamics" (R-NaD), den es als "neue spieltheoretische algorithmische Idee" bezeichnet. Den Code für R-NaD stellt Deepmind für interessierte Forschende bei Github als Open Source zur Verfügung.
Der Algorithmus steuert die KI beim Self-Play zu einem Nash-Gleichgewicht, benannt nach dem Spieltheorie-Mathematiker Jon Forbes Nash. Das Nash-Gleichgewicht beschreibt eine Spielsituation, in der alle Spieler:innen an ihrer Strategie festhalten, da eine Abweichung zu einem schlechteren Ergebnis führen würde. Die schlechteste mögliche Gewinnrate von DeepNash wäre demnach 50 Prozent, vorausgesetzt, der Gegner agiert so perfekt wie das KI-System.
Beim umfangreichen bestärkenden Selbst-Training lernte Deep Nash diese optimale Strategie in rund 5,5 Milliarden simulierten Partien - und eignete sich dabei auch menschliche Spielkonzepte an, ein Phänomen, das sich bereits in Deepminds Spiele-KI AlphaZero zeigte. Deep Nash beherrscht etwa das Bluffen, also strategische Züge, die in einer schwachen Ausgangslage Stärke vermitteln, oder das gezielte Opfern bestimmter Spielfiguren, um Informationen aufzudecken.
Weitere Spielevideos gegen menschliche Expert:innen: Game 2, Game 3, Game 4.
An der Entwicklung und Evaluation von DeepNash war der ehemalige Stratego-Weltmeister Vincent de Boer beteiligt. Er zeigt sich "überrascht" vom erreichten Spielniveau und würde dem KI-System eine gute Rolle bei einer menschlichen Weltmeisterschaft zutrauen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.