Deepminds AlphaZero gilt als KI-Meilenstein. Eine neue Arbeit untersucht, wie genau das KI-System Schach gelernt hat - und wie nahe es dabei am Menschen ist.
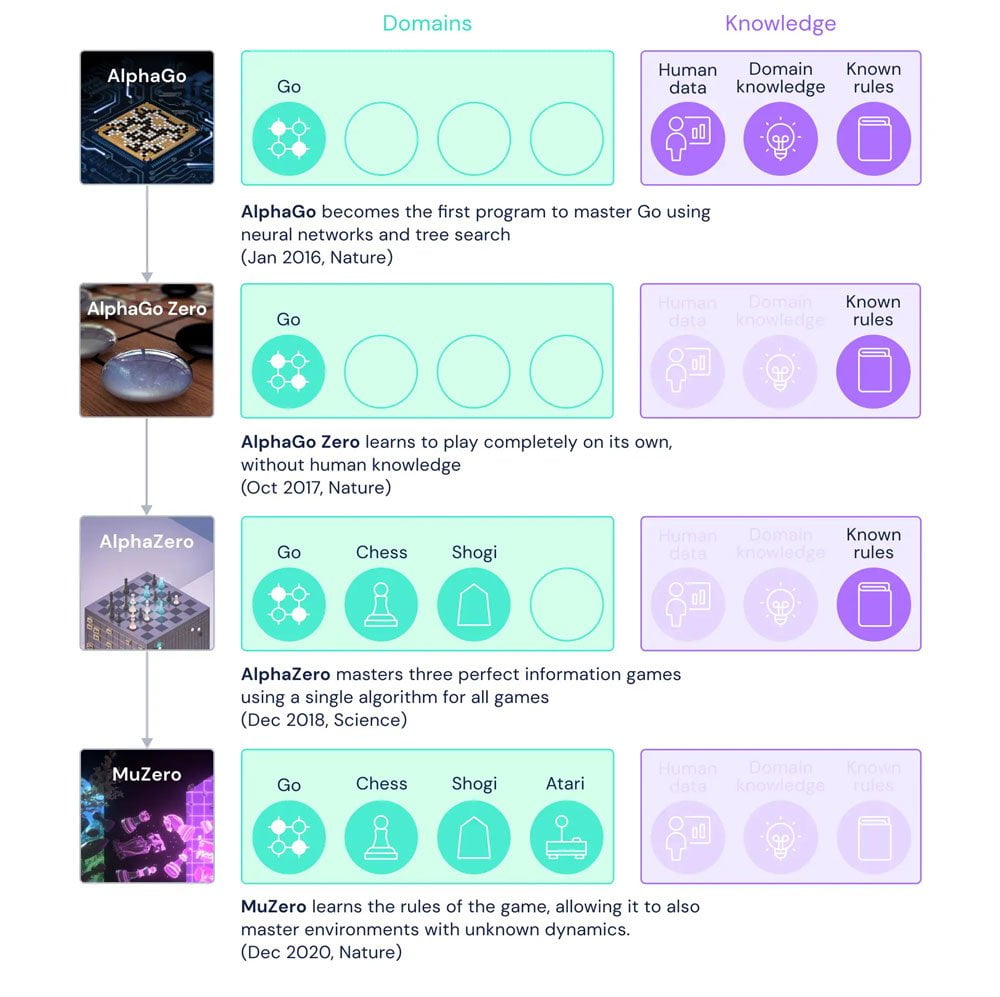
In 2017 zeigte Deepmind AlphaZero, ein KI-System, das Schach, Shogi und Go auf Weltklasse-Niveau spielen kann. Das Unternehmen kombinierte für das KI-System verschiedene Methoden wie Self-Play, bestärkendes Lernen und Suche. Schachweltmeister Magnus Carlsen bezeichnete AlphaZero als eine Inspiration für seinen Wandel als Spieler.
In einem neuen Paper von Deepmind, Google und dem ehemaligen Schachweltmeister Vladimir Kramnik analysieren die Autor:innen nun, wie genau AlphaZero lernt, Schach zu spielen.
AlphaZeros Repräsentationen gleichen menschlichen Konzepten
In ihrer Forschung fand das Team "viele starke Übereinstimmungen zwischen menschlichen Konzepten und den Repräsentationen von AlphaZero, die sich während des Trainings herauskristallisieren, auch wenn keines dieser Konzepte ursprünglich im Netzwerk vorhanden war."
Obwohl das KI-System also keinen Zugang zu menschlichen Partien hatte und nicht von Menschen unterstützt wird, scheint es Konzepte zu lernen, die denen menschlicher Schachspieler:innen gleichen.
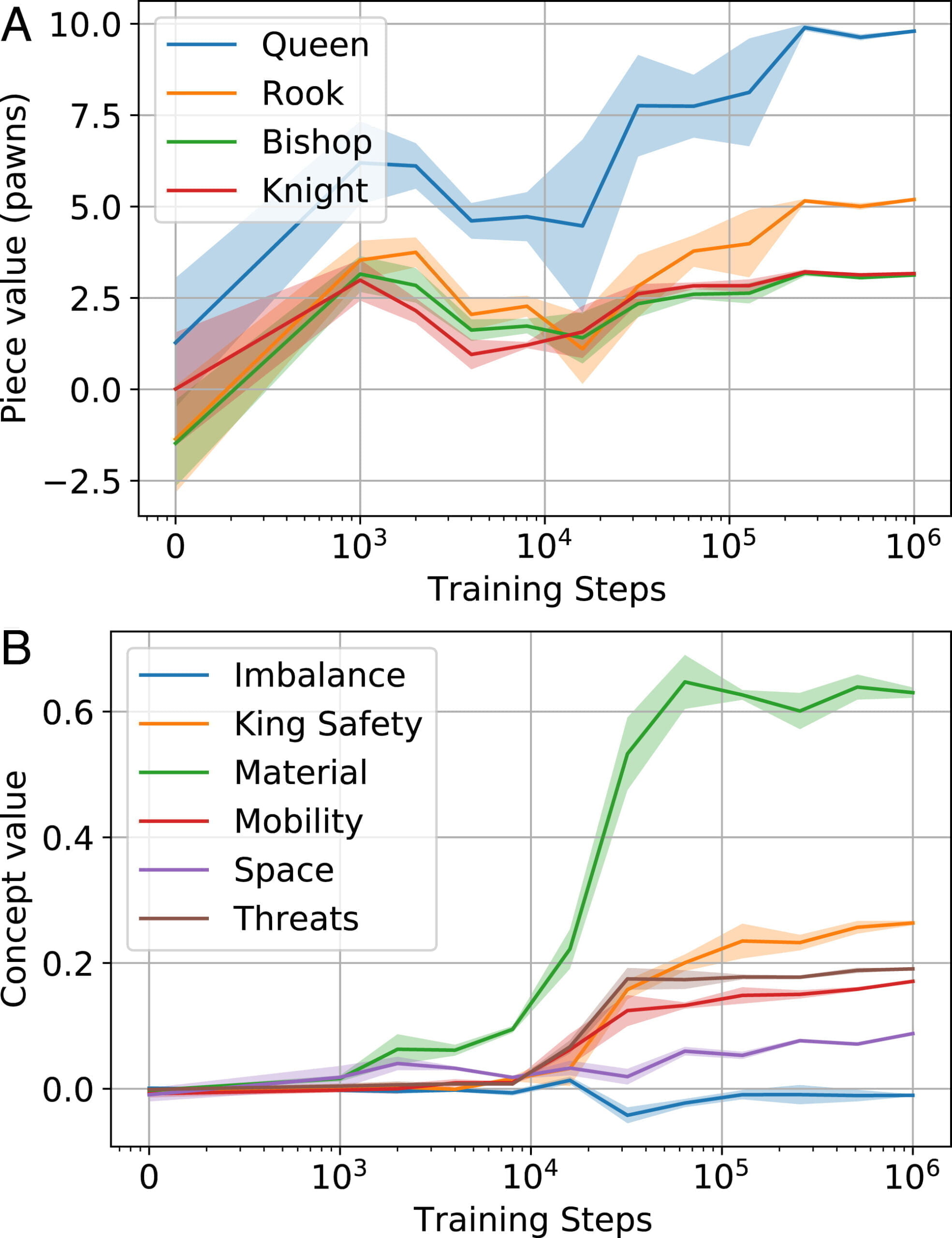
Für die Untersuchung greift das Team auf zwei Methoden zurück: In einer quantitativen Analyse verortet es in Stockfish überprüfbare Schach-Konzepte wie "König Sicherheit", "Materieller Vorteil" oder "Postioneller Vorteil" durch Proben in AlphaZero.
In einer qualitativen Analyse untersucht das Team mit einer Verhaltensanalyse durch Kramnik den Lernprozess von AlphaZero bei Spieleröffnungen und vergleicht diesen mit Menschen.
Trotz aller Ähnlichkeiten ist AlphaZero etwas anders
Die Forschenden nutzen für ihre Untersuchung etwa 100.000 menschliche Spiele aus dem ChessBase-Archiv. Für jede Stellung im Satz berechnete das Team Konzept-Werte und AlphaZeros Aktivierungen.
Zudem deckte es Gemeinsamkeiten im Lernprozess auf: "Zuerst wird der Figurenwert entdeckt; dann folgt eine Explosion des grundlegenden Eröffnungswissens in einem kurzen Zeitfenster. Schließlich wird die Eröffnungstheorie des Netzes in Hunderttausenden von Trainingsschritten verfeinert."

Diese schnelle Entwicklung spezifischer Elemente in AlphaZero spiegle Beobachtungen eines Phasenübergangs in großen Sprachmodellen wider, heißt es im Papier.
Weitere Untersuchungen könnten zudem mehr Konzepte aufdecken, womöglich auch bisher unbekannte. AlphaZeros Untersuchung zeige zudem, dass menschliche Konzepte selbst in einem KI-System gefunden werden können, das durch Self-Play trainiert wurde. Das erweitere den "Bereich der Systeme, in denen wir erwarten sollten, bestehende oder neue, für den Menschen verständliche Konzepte zu finden."