Microsofts Kosmos-1 ist ein multimodaler Schritt zum Weltmodell

Systeme wie ChatGPT oder Midjourney sind Experten für Text oder Bild. Was passiert, wenn man diese Fähigkeiten kombiniert? Forschende von Microsoft testen dies mit Kosmos-1, einem Modell, das Bild und Text kombiniert.
Multimodal trainierte KI-Modelle könnten ein besseres Verständnis der Welt entwickeln, da sie aus verschiedenen Datenquellen lernen - so zumindest die These einiger Wissenschaftler:innen. Außerdem könnten sie ihr Wissen verknüpfen, zum Beispiel Bilder sprachlich detailliert beschreiben.
"Die multimodale Wahrnehmung ist als grundlegende Komponente der Intelligenz eine Notwendigkeit, um generelle künstliche Intelligenz zu erreichen, sowohl was den Wissenserwerb als auch den Bezug zur realen Welt betrifft", schreibt ein Forschungsteam von Microsoft, das mit Kosmos-1 ein multimodales großes Sprachmodell (MLLM) vorstellt.
Neben Sprache und multimodaler Wahrnehmung benötige eine mögliche generelle KI auch die Fähigkeit, die Welt zu modellieren und zu handeln.
Kosmos-1 kann Sprache und Bild kombiniert verarbeiten
Microsoft trainierte Kosmos-1 mit teilweise zusammenhängenden Bild- und Sprachdaten wie Wort-Bild-Paaren. Zusätzlich verwendete das Team große Mengen an Internettext, wie es bei großen Sprachmodellen üblich ist.
Das Modell kann also Bilder und Text verstehen und etwa Text zu Bildern generieren, Texte auf Bildern erkennen, es kann Bildunterschriften schreiben oder Fragen zu Bildern beantworten. Diese Aufgaben kann Kosmos-1 auf direkte Aufforderung oder, ähnlich wie ChatGPT, in einer Dialogsituation ausführen.

Da es über die gleichen Textfähigkeiten wie große Sprachmodelle verfügt, lassen sich auch Methoden, wie das Chain-of-Thought-Prompting anwenden, um zu besseren Lösungen zu gelangen.

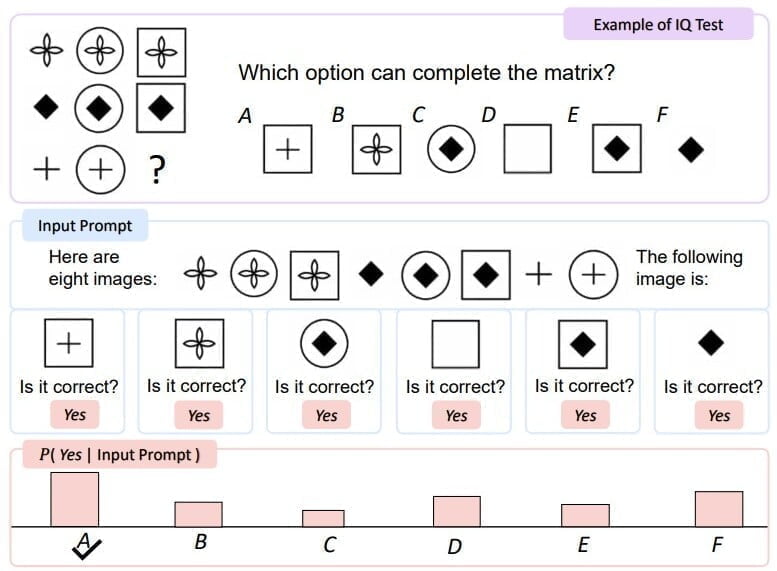
In einem visuellen IQ-Test schnitt KOSMOS-1 etwa fünf bis neun Prozent besser ab als der Zufall, was nach Ansicht des Forschungsteams zeigt, dass KOSMOS-1 in der Lage ist, abstrakte konzeptuelle Muster in einem nonverbalen Kontext wahrzunehmen, indem es nonverbales Denken mit der Wahrnehmung sprachlicher Muster verbindet. Es besteht jedoch noch ein großer Leistungsabstand zum durchschnittlichen Niveau eines Erwachsenen.
Die Fähigkeit multimodaler Modelle, implizite Verbindungen zwischen verschiedenen Konzepten zu repräsentieren, wurde bereits durch die OpenAI-Untersuchung der CLIP-Neuronen gezeigt.
Multimodale-KI als möglicher nächster Schritt in der KI-Entwicklung
Der Ansatz von Microsoft ist nicht neu, die deutsche Firma Aleph Alpha hat mit MAGMA ein Bild-Sprache-Modell und mit M-Vader sogar eine Methode für multimodales Prompting vorgestellt. Google präsentierte bereits im Frühjahr 2021 mit MUM die "Zukunft der Google-Suche", die beispielsweise multimodale Suchanfragen ermöglicht und mehr Kontextwissen bieten soll.
In eine ähnliche Richtung geht Flamingo von Deepmind, das ebenfalls Sprach- und Bildverarbeitung vereint. An Flamingo misst das Microsoft-Forschungsteam auch die Leistungsfähigkeit von Kosmos-1 in Tests, etwa bei der Bilduntertitelung oder bei der Beantwortung von Fragen zu Bildinhalten. Hier schnitt das Microsoft-Modell gleichwertig und teilweise leicht besser ab.
Die Forschenden trainierten zudem ein Sprachmodell (LLM) mit den gleichen Textdaten wie Kosmos-1 und ließen beide Modelle in rein sprachlichen Aufgaben gegeneinander antreten.
Hier lagen beide Modelle gleichauf, wobei Kosmos-1 bei visuellen Aufgaben zum logischen Denken, die ein Verständnis der Eigenschaften von Alltagsgegenständen aus der realen Welt wie Farbe, Größe und Form erfordern, signifikant besser abschnitt, sagt das Team.
Der Grund für die überlegene Leistung von KOSMOS-1 liegt darin, dass es zwischen den Modalitäten transferieren kann, so dass das Modell visuelles Wissen auf sprachliche Aufgaben übertragen kann.
Im Gegensatz dazu muss LLM bei der Beantwortung visueller Bedeutungsfragen auf textuelles Wissen und Hinweise zurückgreifen, was seine Fähigkeit, über Objekteigenschaften nachzudenken, einschränkt.
Aus dem Paper
Multimodale große Sprachmodelle vereinten das Beste aus zwei Welten, schreibt das Forschungsteam. Das kontextbasierte Lernen und das Befolgen von Anweisungen großer Sprachmodelle sowie "die Anpassung der Wahrnehmung an die Sprachmodelle durch Training an multimodalen Korpora".
Die Ergebnisse von Kosmos-1 seien "vielversprechend" in einem breiten Spektrum von sprachlichen und multimodalen Aufgaben. Die multimodalen Modelle böten neue Fähigkeiten und Möglichkeiten im Vergleich zu großen Sprachmodellen.
Kosmos-1 hat 1,6 Milliarden Parameter, was im Vergleich zu den heutigen großen Sprachmodellen winzig ist. Das Team möchte Kosmos-1 skalieren und weitere Modalitäten wie gesprochene Sprache in das Modelltraining einbeziehen. Ein größeres Modell mit mehr Modalitäten könnte dann viele der derzeitigen Einschränkungen überwinden.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.