MPT-7B: Das beste Open-Source-Sprachmodell ist kommerziell nutzbar

MosaicML veröffentlicht das bisher beste Open-Source-Sprachmodell, auch für kommerzielle Zwecke. Eine Variante kann sogar ganze Bücher verarbeiten.
MosaicMLs MPT-7B ist ein großes Sprachmodell mit fast 7 Milliarden Parametern, das das Team mit einem eigenen Datensatz von fast einer Billion Token trainiert hat.
Damit folgte MosaicML dem Trainingsregime des Vorbilds LLaMA von Meta. Das Training kostete knapp 200.000 US-Dollar und dauerte 9,5 Tage mit der MosaicML-Plattform.
MosaicML MPT-7B ist das bisher beste Open-Source-Modell
MPT-7B erreicht laut MosaicML die Leistungsfähigkeit von Metas 7-Milliarden-Parameter-Modell LLaMA, ist damit das erste Open-Source-Modell, das dieses Niveau erreicht und liegt vor OpenLLaMA.
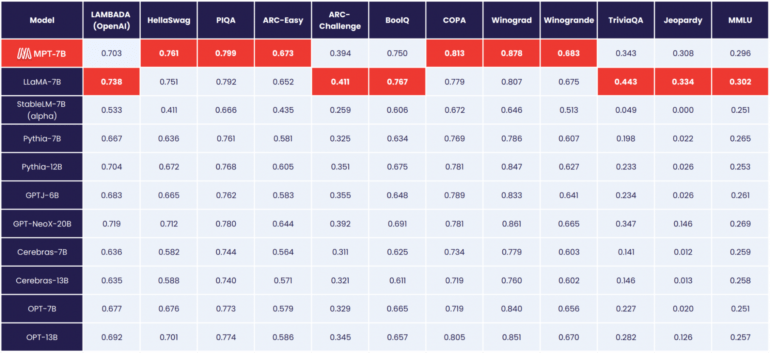
Im Gegensatz zu Metas Modellen ist MPT-7B jedoch für die kommerzielle Nutzung freigegeben.
Neben dem Modell "MPT-7B Base" veröffentlicht MosaicML auch drei Varianten: MPT-7B-StoryWriter-65k+, MPT-7B-Instruct und MPT-7B-Chat.
MosaicML zeigt Sprachmodell mit 65.000 Token Kontext
MPT-7B-Instruct ist ein Modell für das Verfolgen von Kurzanweisungen, das Chat-Modell ist eine Chatbot-Variante im Stil von Alpaca oder Vicuna.
Mit MPT-7B-StoryWriter-65k+ veröffentlicht MosaicML auch ein Modell, das in der Lage sein soll, Stories mit sehr langen Kontextlängen zu lesen und zu schreiben. Dazu wurde MPT-7B mit einer Kontextlänge von 65.000 Token mit einer Teilmenge des books3-Datensatzes verfeinert. Die größte GPT-4-Variante von OpenAI soll 32.000 Token verarbeiten können.
Laut MosiacML kann das Modell mit einigen Optimierungen sogar über 65.000 Token extrapolieren und das Team konnte bis zu 84.000 Token auf einem einzelnen Knoten mit Nvidia A100-80GB GPUs demonstrieren. Aber selbst mit 65.000 Token war es möglich, ganze Romane zu generieren und einen Epilog zu schreiben.

Alle MPT-7B-Modelle sind auf GitHub verfügbar.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.