Die Chatbot Arena hilft bei der Suche nach dem besten Chatbot

Bisher gab es keine einfache Möglichkeit, die Qualität von Open-Source-Modellen zu vergleichen. Ein System aus dem E-Sport könnte helfen.
Die "Large Model System Organization" (LMSYS), die hinter dem Open-Source-Modell Vicuna steckt, hat die Benchmark-Plattform "Chatbot Arena" gestartet, um die Leistung großer Sprachmodelle zu vergleichen.
Auf dieser Plattform treten verschiedene Modelle in anonymen, zufällig ausgewählten Duellen gegeneinander an. Anschließend bewerten die Nutzer:innen die Modelle und stimmen für ihre bevorzugte Antwort ab.
Anhand dieser Bewertungen werden die Modelle nach dem Elo-Bewertungssystem eingestuft, das etwa im Schach und vor allem im E-Sport weit verbreitet ist. Die Nutzer:innen dürfen prinzipiell alles fragen und auch längere Gespräche führen, allerdings nicht direkt nach dem Namen des Modells fragen - das disqualifiziert ihre Stimme für das Ranking.
GPT-4 mit höchster Elo
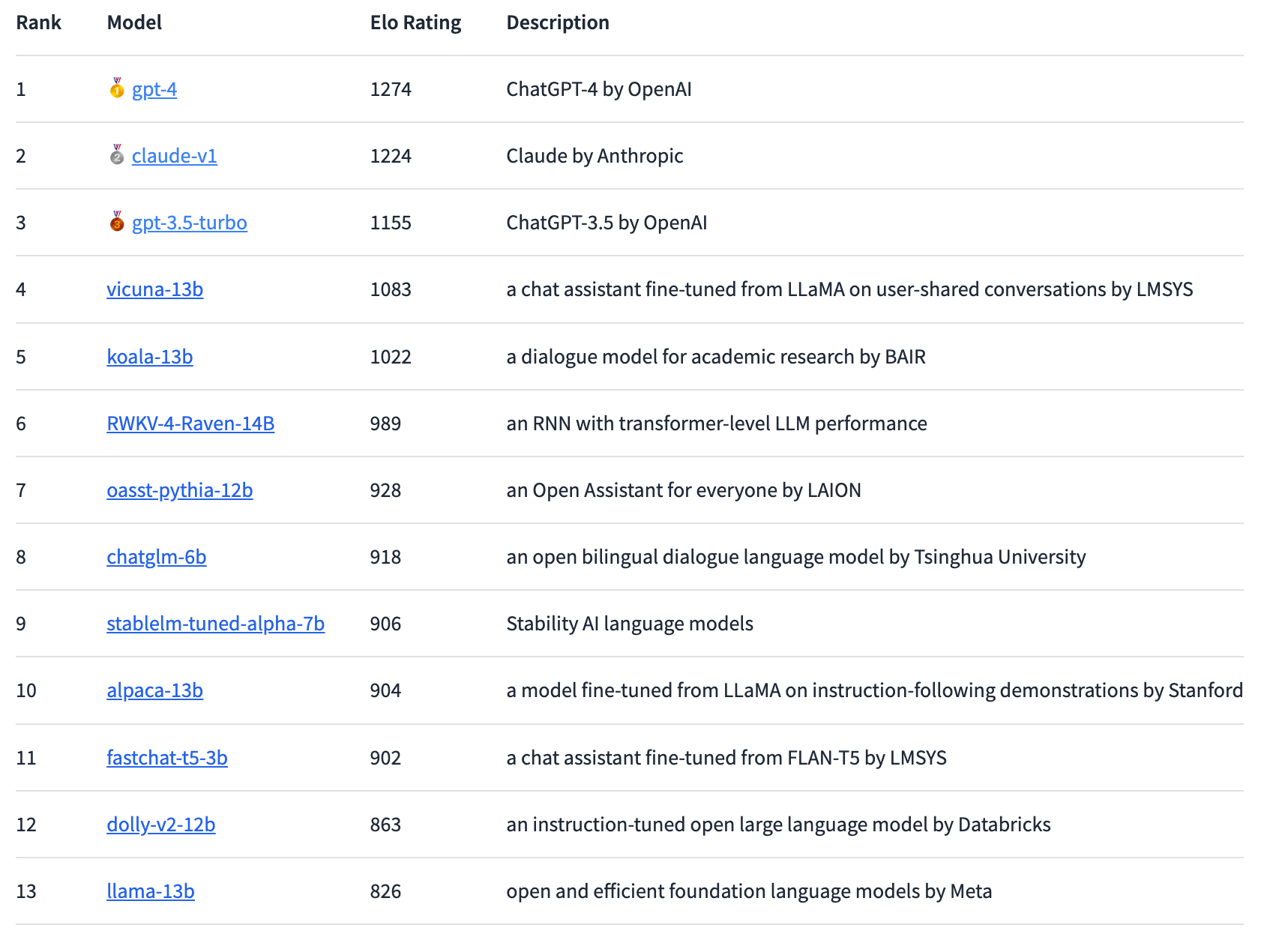
Nach dieser Methode führt derzeit GPT-4 die Rangliste an, dicht gefolgt von Claude-v1, dahinter GPT-3.5 Turbo mit etwas größerem Abstand. Vicuna-13B ist das am besten bewertete Open-Source-Modell. In Zukunft wollen die Forscher:innen weitere Open- und Closed-Source-Modelle integrieren und die Rankings genauer aufschlüsseln.
Seit dem Leak von Metas Sprachmodell LLaMA sind eine Vielzahl von Open-Source-Sprachmodellen entstanden, die ähnlich wie ChatGPT im Chatbot-Stil menschlichen Anweisungen folgen und Fragen der Nutzer:innen beantworten sollen. Die Schwierigkeit besteht jedoch darin, diese Modelle effektiv zu evaluieren, insbesondere bei offenen Fragen.
Chatbots im Arena-Wettbewerb
Hier bietet die Chatbot Arena einen vielversprechenden neuen Ansatz: Das Elo-System zur Evaluierung großer Sprachmodelle wurde unter anderem bereits von Anthropic für einen Benchmark von Claude verwendet.
In der Arena stehen die Modelle in direktem Wettbewerb zueinander und die Nutzerinnen und Nutzer stimmen durch ihre Interaktionen darüber ab, welches Modell sie für das beste halten. Die Plattform sammelt alle Interaktionen der Nutzenden, verwendet aber nur die abgegebenen Stimmen, während die Modellnamen verborgen bleiben. Eine Woche nach dem Start waren laut LMSYS rund 4.700 gültige anonyme Stimmen eingegangen, Anfang Mai waren es schon rund 13.000.
Die bisherigen Ergebnisse zeigen laut LMSYS eine "substanzielle Lücke" zwischen proprietären und Open-Source-Modellen. Allerdings hätten die in der Arena vertretenen Open-Source-Modelle auch deutlich weniger Parameter, im Bereich von drei bis 14 Milliarden Parametern. GPT-4 gewinnt 82 Prozent der Duelle gegen Vicuna-13B und 80 Prozent der Duelle gegen GPT-3.5-turbo. Anthropics Claude übertrifft GPT-3.5 in der Arena und liegt gleichauf mit GPT-4.
Praktisch ist neben dem Arena-Wettbewerb insbesondere der "Side-by-Side"-Modus: Hier können einzelne Open-Source-Sprachmodelle ausgewählt und gleichzeitig mit demselben Prompt gefüttert werden. So können die Ergebnisse in Echtzeit miteinander verglichen werden.
Hier geht es zur Chatbot Arena, wenn ihr euch an der Abstimmung beteiligen oder ein für euch nützliches Sprachmodell identifizieren wollt. Ähnlich funktioniert die Plattform Playground des früheren Github-CEOs Nathaniel Friedman.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.