Metas Megabyte soll ChatGPT und Co. auf ein neues Niveau heben
Meta stellt mit MegaByte eine Methode vor, die Leistung und Effizienz von Transformer-Modellen auf ein neues Niveau heben könnte.
Gegenwärtig verwenden alle Transformer-Modelle sogenannte "Tokenizer". Diese Algorithmen wandeln Wörter, Bilder, Audio oder andere Eingaben in Token um, die dann als Zahlenreihen von GPT-4 oder anderen Modellen verarbeitet werden können. Bei Sprachmodellen werden kurze Wörter in ein Token und längere Wörter in mehrere Token umgewandelt.
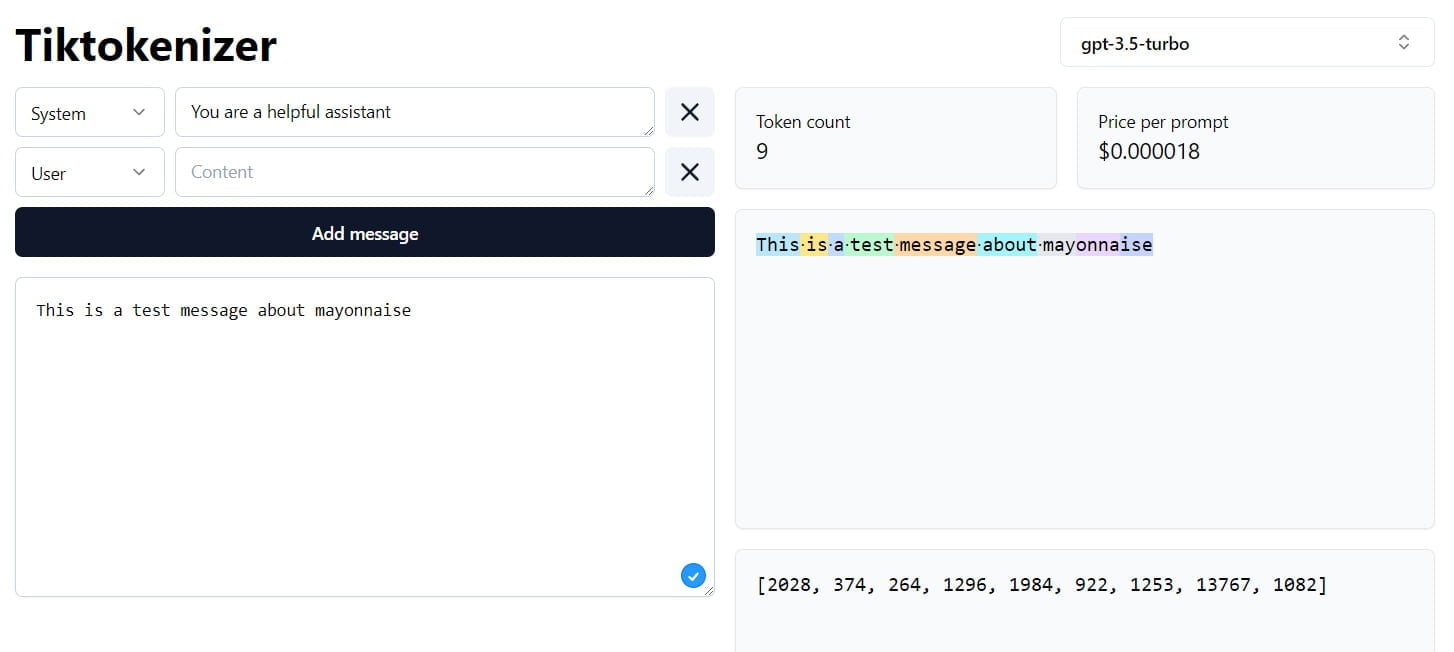
Die Verwendung solcher Token hat jedoch einige Nachteile, so ist ihre Verarbeitung je nach Modellarchitektur sehr rechenintensiv, die Integration neuer Modalitäten ist schwierig und sie können beispielsweise nicht auf Buchstabenebene verwendet werden. Dies führt immer wieder zu subtilen Fähigkeitslücken in Sprachmodellen, wie die Unfähigkeit, die Anzahl der "n" im Wort "Mayonnaise" zu zählen.
I saw this on Facebook, and I'm confused why this is a hard task. Facebook post has ChatGPT failing at this too pic.twitter.com/YHW9yHXA5X
— Talia Ringer 🕊 (@TaliaRinger) May 19, 2023
Diese und andere Faktoren erschweren auch die Verarbeitung großer Datenmengen, auch wenn es mit GPT-4 oder Claude inzwischen Modelle gibt, die zwischen 32.000 und 100.000 Token verarbeiten können.
Metas MegaByte setzt auf Bytes statt auf Token
Mit MegaByte zeigen die Forschenden von Meta AI nun eine Methode, die ohne Tokenizer auskommt und stattdessen Text, Bilder und Audio auf Byte-Ebene verarbeitet. MegaByte zerlegt zunächst Sequenzen von Text oder anderen Modalitäten in einzelne Abschnitte - ähnlich wie ein Tokenizer.
Anschließend kodiert jedoch ein Patch-Embedder jeden Abschnitt durch eine verlustfreie Verkettung der Embeddings jedes einzelnen Bytes, z.B. eines Buchstabens. Ein globales Modul, ein großer autoregressiver Transformer, nimmt diese Abschnittsrepräsentationen als Input und gibt sie weiter.
Jeder Abschnitt wird dann von einem lokalen autoregressiven Transformer-Modell verarbeitet, das die Bytes innerhalb eines Abschnitts vorhersagt.
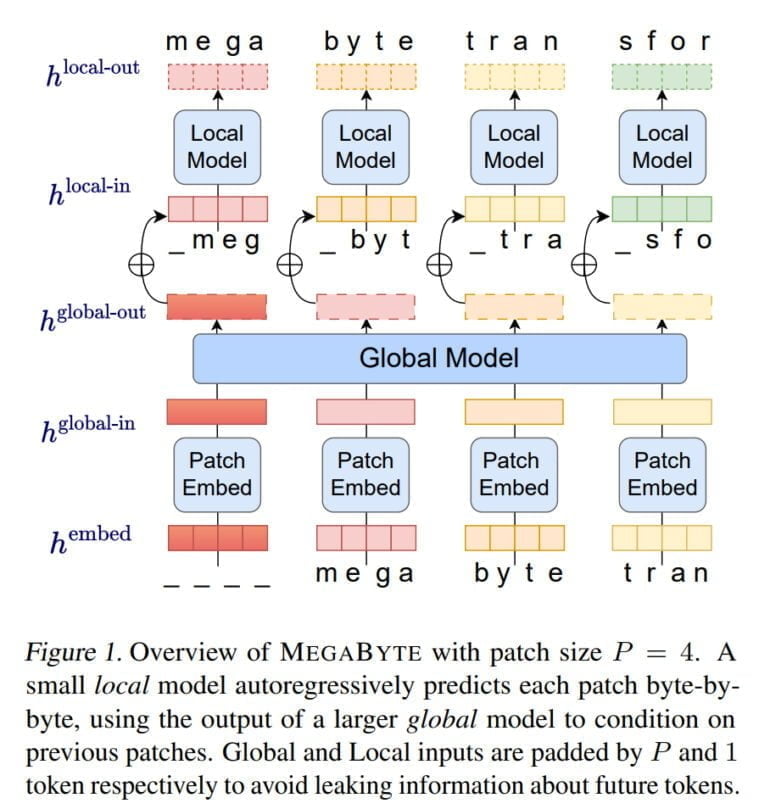
Laut Meta ermöglicht die Architektur einen höheren Grad an Rechenparallelität, größere und leistungsfähigere Modelle bei gleichen Rechenkosten und eine deutliche Senkung der Kosten für den Self-Attention-Mechanismus der Transformer.
Das Team vergleicht MegaByte mit anderen Modellen wie einer einfachen Decoder-Transformer-Architektur oder Deepminds PerceiverAR in Tests für Text, Bilder und Audio und kann zeigen, dass MegaByte effizienter ist und knapp eine Million-Byte-Sequenzen verarbeiten kann.
OpenAIs Andrej Karpathy zeigt Interesse an Metas MegaByte
Andrej Karpathy von OpenAI bezeichnete Metas MegaByte als vielversprechende Arbeit. "Jeder sollte hoffen, dass wir die Tokenisierung in großen Sprachmodellen abschaffen können", schreibt Karpathy bei Twitter.
Promising. Everyone should hope that we can throw away tokenization in LLMs. Doing so naively creates (byte-level) sequences that are too long, so the devil is in the details.
Tokenization means that LLMs are not actually fully end-to-end. There is a whole separate stage with… https://t.co/t240ZPxPm7
— Andrej Karpathy (@karpathy) May 15, 2023
Das Team von Meta AI sieht in den eigenen Ergebnissen ebenfalls einen Hinweis darauf, dass MegaByte das Potenzial haben könnte, klassische Tokenizer in Transformer-Modellen zu ersetzen.
MEGABYTE übertrifft bestehende Byte-Level-Modelle bei einer Reihe von Fragestellungen und Modalitäten und ermöglicht große Sequenzmodelle mit mehr als einer Million Token. Es liefert auch konkurrenzfähige Sprachmodellierungsergebnisse mit Subwortmodellierung, wodurch Byte-Level-Modelle durch Tokenisierung ersetzt werden könnten.
Meta
Da die Modelle, an denen die Experimente durchgeführt wurden, weit unter der Größe heutiger Sprachmodelle liegen, plant Meta als nächsten Schritt die Skalierung auf deutlich größere Modelle und Datensätze.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.