Metas neues Open-Source-Modell spricht mehr als 1100 Sprachen

Im Rahmen des Projekts "Massively Multilingual Speech" veröffentlicht Meta KI-Modelle, die gesprochene Sprache in Text und Text in Sprache in 1.100 Sprachen umwandeln können.
Grundlage für die Entwicklung der neuen Modellreihe waren Metas wav2vec sowie ein kuratierter Datensatz mit Beispielen für 1.100 Sprachen und ein weiterer unkuratierter Datensatz für fast 4.000 Sprachen, darunter laut Meta auch Sprachen, die nur noch von wenigen hundert Menschen gesprochen werden und für die es bisher keine Sprachtechnologie gibt.
Das Modell kann sich in mehr als 1000 Sprachen ausdrücken und mehr als 4000 Sprachen identifizieren. Laut Meta übertrifft MMS bisherige Modelle und deckt dabei zehnmal mehr Sprachen ab. Eine Übersicht über alle verfügbaren Sprachen gibt es hier.
Das neue Testament als KI-Datensatz
Ein wesentlicher Bestandteil von MMS ist die Bibel, genauer gesagt das Neue Testament. Der Meta-Datensatz enthält Lesungen des Neuen Testaments in mehr als 1.107 Sprachen mit einer durchschnittlichen Länge von 32 Stunden.
Meta verwendete diese Aufnahmen in Kombination mit passenden Textpassagen aus dem Internet. Ergänzend wurden weitere 3.809 unbeschriftete Audiodateien verwendet, ebenfalls Lesungen aus dem Neuen Testament, jedoch ohne Angabe der Sprache.
Da 32 Stunden pro Sprache nicht genug Trainingsmaterial für ein verlässliches Spracherkennungssystem sind, hat Meta mit wave2vec 2.0 MMS-Modelle mit mehr als 500.000 Stunden Sprache in mehr als 1.4000 Sprachen vortrainiert. Diese Modelle wurden dann feingetunt, um eine große Anzahl von Sprachen zu verstehen oder zu identifizieren.
Benchmarks zeigen, dass die Leistung des Modells trotz des Trainings mit viel mehr verschiedenen Sprachen nahezu konstant blieb. Die Fehlerquote sank mit zunehmendem Training sogar minimal um 0,4 Prozentpunkte.
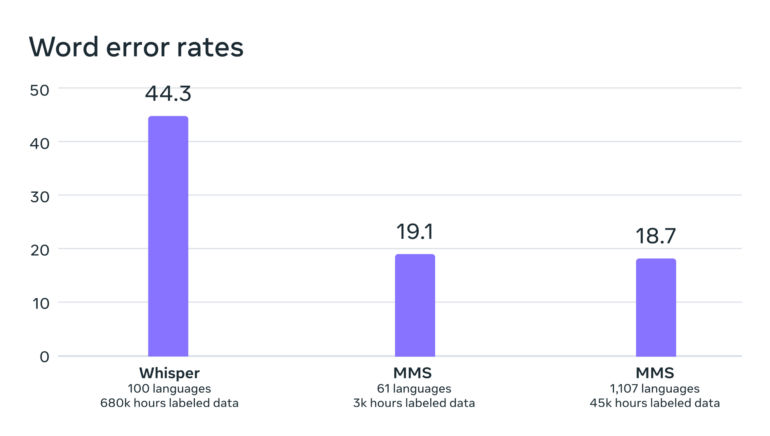
Sie liegt laut Meta zudem deutlich unter der von OpenAIs Whisper, das allerdings nicht explizit für eine umfassende Mehrsprachigkeit optimiert wurde. Hier wäre ein Vergleich etwa nur in englischer Sprache interessanter. Erste Tester bei Twitter berichten, dass Whisper hier weiter besser abschneidet.
In my testing, it performs worse than Whisper for transcription to text, mis-hearing words and not hearing implied punctuation. Also it's about 10x slower than Faster-Whisper. Fairseq uses 20 GB of RAM, while Whisper uses about 1 GB. For these reasons and others this is…
— catid (@MrCatid) May 23, 2023
Die Tatsache, dass die Stimmen im Datensatz überwiegend männlich sind, wirkt sich laut Meta nicht negativ auf das Verständnis oder die Generierung weiblicher Stimmen aus. Zudem neige das Modell nicht dazu, übermäßig religiöse Sprache zu generieren. Meta führt dies auf den verwendeten Klassifikationsansatz (Connectionist Temporal Classification) zurück, der sich mehr auf Sprachmuster und -sequenzen als auf Wortinhalte und -bedeutungen konzentriert.
Meta warnt jedoch davor, dass das Modell manchmal Wörter oder Phrasen falsch transkribiert, was zu falschen oder beleidigenden Aussagen führen könne.
Ein Modell für Tausende Sprachen
Langfristiges Ziel von Meta ist es, ein einziges Sprachmodell für so viele Sprachen wie möglich zu entwickeln, um auch aussterbende Sprachen zu erhalten. Zukünftige Modelle könnten noch mehr Sprachen und sogar Dialekte unterstützen.
"Unser Ziel ist es, es den Menschen zu erleichtern, Informationen in ihrer bevorzugten Sprache zu erhalten", schreibt Meta. Konkrete Anwendungsszenarien seien VR- und AR-Technologien oder Messaging.
In Zukunft könne ein einziges Modell für alle Aufgaben wie Spracherkennung, Sprachsynthese und Sprachidentifikation trainiert werden, was zu einer noch besseren Gesamtleistung führe, schreibt Meta.
Der Code, die vortrainierten MMS-Modelle mit 300 Millionen respektive einer Milliarde Parametern sowie die verfeinerten Ableitungen für Spracherkennung und -identifikation sowie Text-to-Speech stellt Meta als Open Source auf Github zur Verfügung.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.