Open-Source-Sprachmodell Falcon 180B soll GPT-3.5 und Llama 2 übertreffen

Update –
- Falcon 180B ergänzt
Letztes Update am 07. September 2023:
Das Technology Innovation Institute veröffentlicht Falcon 180B, das größte Modell der Falcon-Serie. Es basiert auf Falcon 40B und wurde mit 3,5 Billionen Token auf bis zu 4096 GPUs gleichzeitig mit Amazon SageMaker für insgesamt ~7.000.000.000 GPU-Stunden skaliert.
Falcon 180B soll Llama 2 70B sowie OpenAIs GPT-3.5 übertreffen. Je nach Aufgabe soll die Leistung zwischen GPT-3.5 und GPT-4 liegen. Mit dem Google-Sprachmodell PaLM 2 soll es in einer Reihe von Benchmarks gleichauf liegen.
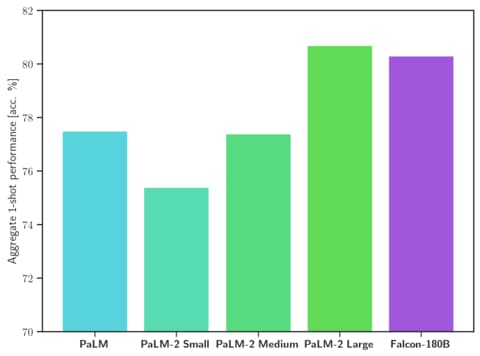
Im Hugging Face Leaderboard liegt Falcon 180B derzeit knapp vor Metas Llama 2. Im Vergleich zu Llama 2 erforderte das Training die vierfache Rechenleistung und das Modell ist um den Faktor 2,5 größer.
Eine Falcon180B Demo und weitere Informationen gibt es bei Hugging Face. Die kommerzielle Nutzung ist möglich, aber sehr restriktiv. Daher sollte man sich die Lizenz genau ansehen. Ein mit Instruktionen verfeinertes Chatmodell ist verfügbar.
Ursprünglicher Artikel vom 29. Mai 2023:
Open-Source-Sprachmodell FalconLM soll Metas LLaMA schlagen
Das Open-Source-Sprachmodell FalconLM soll eine bessere Performance als Metas LLaMA bieten und ist zudem kommerziell nutzbar. Allerdings werden ab einem Umsatz von einer Million US-Dollar Lizenzgebühren fällig.
FalconLM wird vom Technology Innovation Institute (TII) in Abu Dhabi, Vereinigte Arabische Emirate, entwickelt. Die Organisation behauptet, FalconLM sei das bisher leistungsfähigste Open-Source-Sprachmodell, obwohl die größte Variante mit 40 Milliarden Parametern deutlich kleiner ist als Metas LLaMA mit 65 Milliarden Parametern.
Die beiden größten FalconLM-Modelle, von denen eines mit Instruktionen verfeinert wurde, belegen derzeit mit deutlichem Vorsprung die ersten beiden Plätze im Hugging Face OpenLLM Leaderboard, das die Ergebnisse verschiedener Benchmarks zusammenfasst. Zusätzlich bietet das TII ein 7-Milliarden-Modell an.
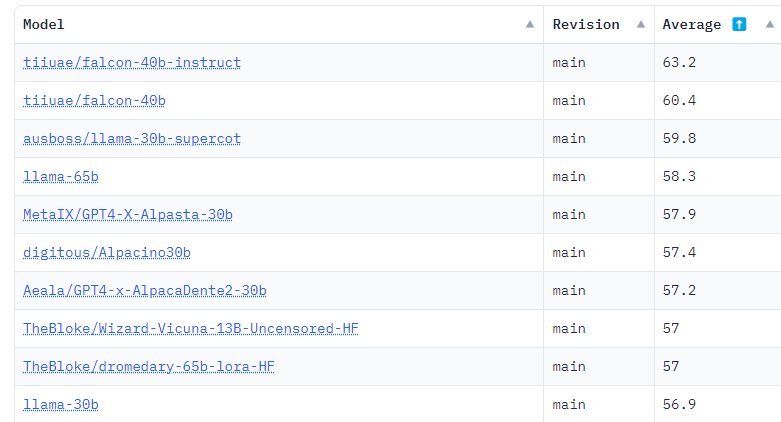
FalconLM trainiert effizienter als GPT-3
Ein wichtiger Aspekt für den Leistungsvorsprung von FalconLM ist nach Ansicht des Entwicklungsteams die Datenauswahl für das Training. Sprachmodelle reagieren empfindlich auf die Datenqualität beim Training.
Das Forschungsteam entwickelte daher ein Verfahren, um aus dem bekannten Common-Crawl-Datensatz qualitativ hochwertige Daten zu extrahieren und Dubletten zu entfernen. Trotz dieser gründlichen Bereinigung blieben fünf Billionen Textstücke (Tokens) übrig - genug, um leistungsfähige Sprachmodelle zu trainieren. Das Kontextfenster liegt bei 2048 Token, also etwas unterhalb von ChatGPT-Niveau.
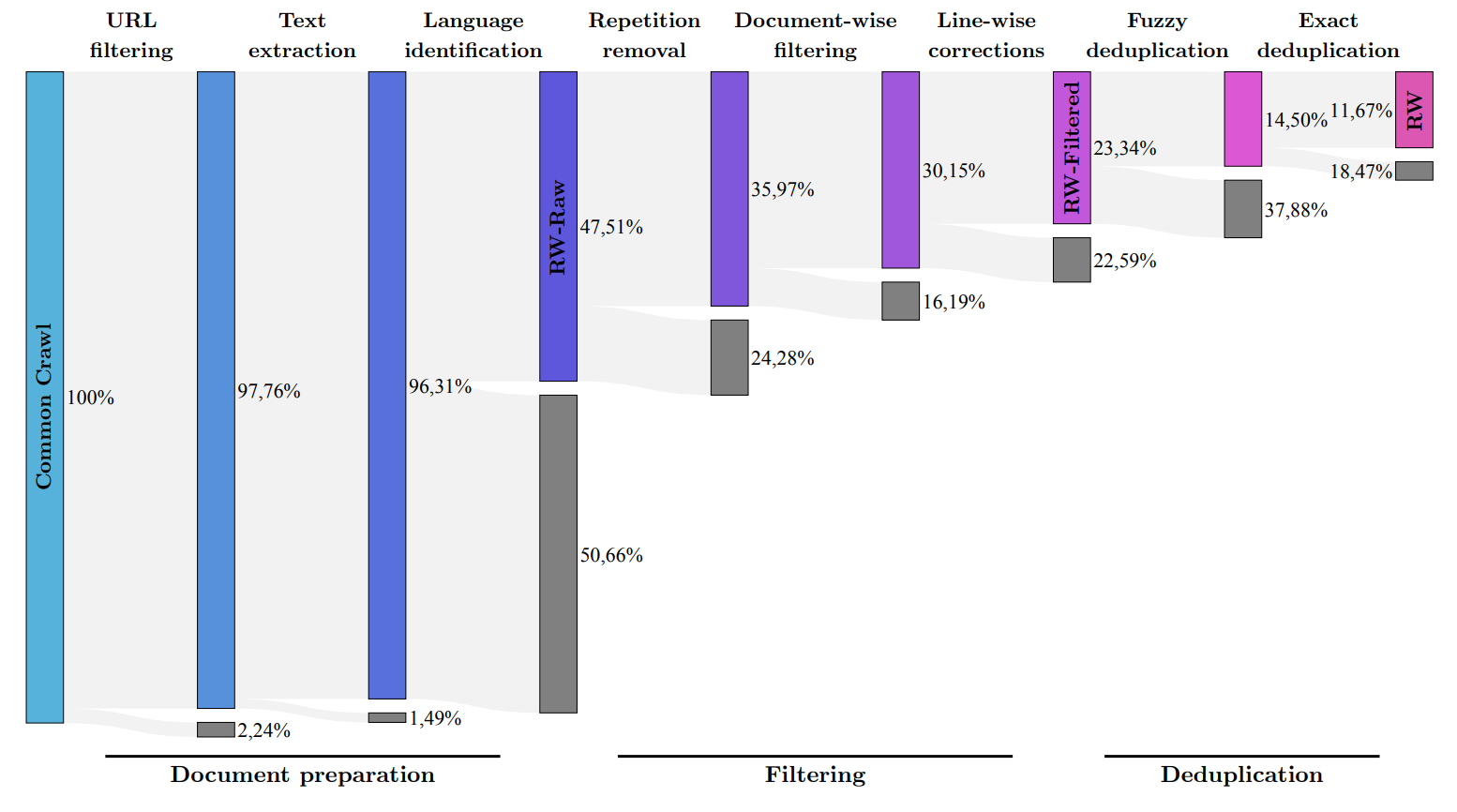
FalconLM mit 40 Milliarden Parametern wurde mit einer Billion Token trainiert, das 7-Milliarden-Parameter-Modell mit 1,5 Billionen. Die Daten aus dem RefinedWeb-Datensatz wurden dabei durch "einige wenige" kuratierte Daten aus wissenschaftlichen Artikeln und Diskussionen in sozialen Medien ergänzt. Die leistungsfähigste Instruktionsvariante, die Chatbot-Version, wurde zudem mit dem Baize-Datensatz verfeinert.
Weiterhin spricht das TII von einer "auf Leistung und Effizienz optimierten Architektur", ohne jedoch Details zu nennen. Das Paper ist noch nicht verfügbar. Nach Angaben des Teams soll die optimierte Architektur zusammen mit dem qualitativ hochwertigen Datensatz dazu geführt haben, dass FalconLM beim Training nur 75 Prozent des Rechenaufwands von GPT-3 benötigte, aber die Leistung des älteren OpenAI-Modells deutlich übertrifft. Die Inferenzkosten sollen bei einem Fünftel von GPT-3 liegen.
Verfügbar als Open Source, aber kommerzielle Nutzung kann kostenpflichtig sein
Als Anwendungsszenarien für FalconLM nennt das TII die Textgenerierung, das Lösen komplexer Probleme, den Einsatz des Modells als privaten Chatbot oder in kommerziellen Bereichen wie Kundenservice oder Übersetzung.
Bei kommerziellen Anwendungen will das TII allerdings ab einem Umsatz von einer Million US-Dollar, der dem Sprachmodell zugeordnet werden kann, mitverdienen: Hier werden zehn Prozent des Umsatzes als Lizenzgebühr fällig. Wer an eine kommerzielle Nutzung denkt, sollte sich mit der Verkaufsabteilung des TII in Verbindung setzen. Für die private Nutzung und für Forschungszwecke ist FalconLM kostenlos verfügbar.
Die FalconLM-Modelle sind in allen Varianten kostenlos bei Huggingface herunterladbar. Zusammen mit den Modellen veröffentlicht das Team auch einen Auszug aus dem "RefinedWeb"-Datensatz mit 600 Milliarden Text-Token als Open Source unter einer Apache 2.0 Lizenz. Der Datensatz sei zudem für eine multimodale Erweiterung vorbereitet, da in den Beispielen bereits Links und Alt-Texte für Bilder enthalten seien.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.