OpenAI verbessert mathematische Fähigkeiten von GPT-4 mit menschlichem Feedback

OpenAI zeigt ein KI-Modell, das bei der Lösung einiger mathematischer Probleme neue Bestwerte erreicht. Der zugrunde liegende Prozess könnte zu allgemein besseren Sprachmodellen führen.
In der Arbeit "Let's Verify Step by Step" trainierte das OpenAI-Team mehrere Modelle auf Grundlage von GPT-4, um Aufgaben im MATH-Datensatz zu lösen. Ziel war es, zwei Varianten von Feedbackprozessen für das Training von Belohnungsmodellen zu vergleichen.
Konkret verglich das Team "Outcome Supervision", bei der das KI-Modell Feedback über das Endergebnis einer Aufgabe erhält, mit "Process Supervision", bei der das Modell Feedback für jeden konkreten Denkschritt erhält.
In der Praxis erfordert der letztgenannte Prozess menschliches Feedback und ist daher für große Modelle und vielfältige Aufgaben kostspielig. Die aktuelle Arbeit ist daher eine Untersuchung, die die zukünftige Richtung von OpenAI bestimmen könnte.
Process Supervision hat keine negativen Auswirkungen
Für mathematische Aufgaben konnte OpenAI sowohl für große als auch für kleine Modelle zeigen, dass "Process Supervision" deutlich bessere Ergebnisse liefert, die Modelle also häufiger richtig liegen und nach Ansicht des Teams auch einen menschenähnlicheren Denkprozess aufweisen. Halluzinationen oder logische Fehler, die auch in den derzeit besten Modellen immer wieder auftreten, können so reduziert werden.
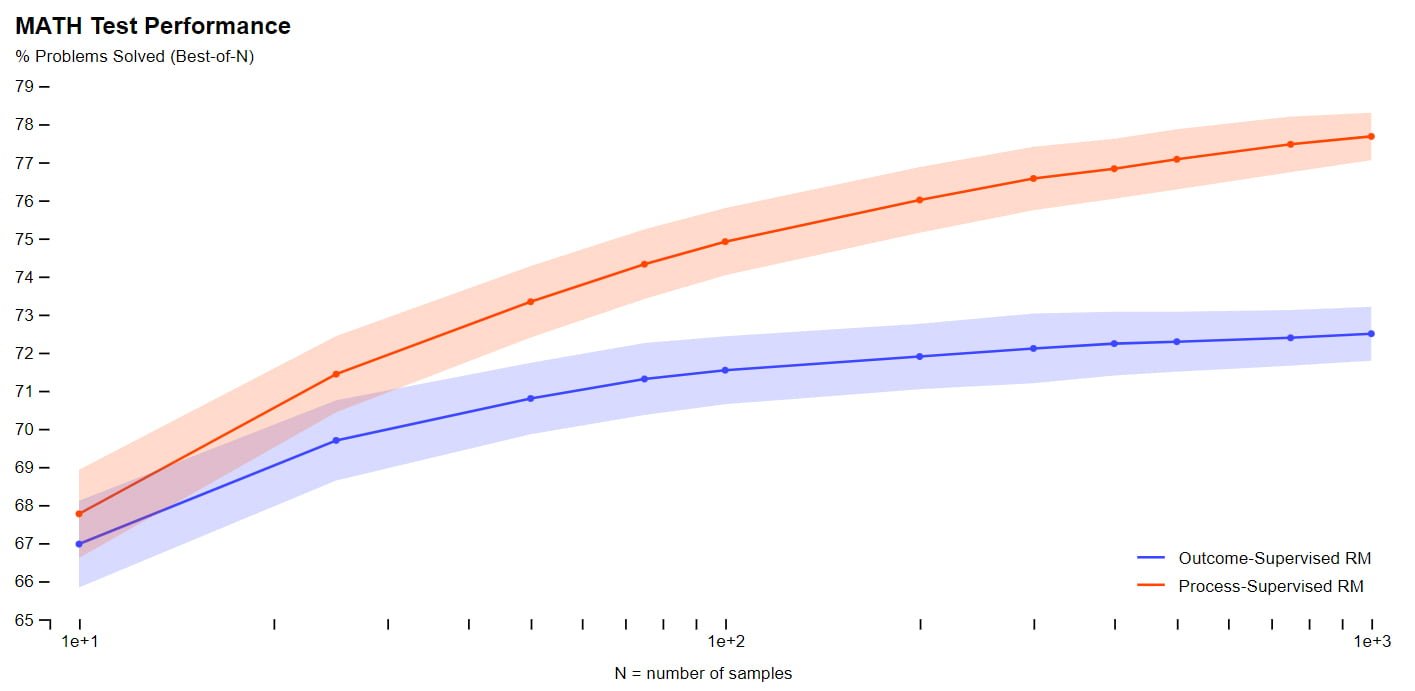
Außerdem vermeidet die Belohnung korrekter Zwischenschritte laut OpenAI das als "alignment tax" bezeichnete Phänomen, bei dem die Leistung eines Modells durch die Anpassung an menschliche Werte und Erwartungen reduziert wird. Im Falle der getesteten Mathematikaufgaben stellt das Unternehmen sogar eine negative "alignment tax" fest.
Es ist nicht bekannt, inwieweit diese Ergebnisse über den Bereich der Mathematik hinaus verallgemeinert werden können, und wir halten es für wichtig, in zukünftigen Arbeiten die Auswirkungen der Process Supervision in anderen Bereichen zu untersuchen. Wenn sich diese Ergebnisse verallgemeinern lassen, könnten wir feststellen, dass die Process Supervision uns das Beste aus beiden Welten bietet - eine Methode, die sowohl leistungsfähiger als auch angemessener ist als die Outcome Supervision.
OpenAI
OpenAI veröffentlicht Datensatz mit menschlichen Labels
Inwieweit "Process Supervision" auch für Bereiche außerhalb der Mathematik geeignet ist, muss weiter erforscht werden. Um diesen Prozess zu unterstützen, hat OpenAI den für das eigene Modell eingesetzten Datensatz PRM800K veröffentlicht, der 800.000 menschliche Labels für alle Zwischenschritte des MATH-Datensatzes enthält.
Der beteiligte Autor und OpenAI-Mitbegründer John Schulman hat die zentrale Rolle eines Belohnungsmusters bei der Ausbildung erwünschter Verhaltensweisen in großen Sprachmodellen kürzlich in einem Vortrag ausführlich erläutert.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.