Microsofts multimodales CoDi verarbeitet und generiert Text, Bilder, Video und Audio
Microsoft-Forscher stellen CoDi vor, ein auf Diffusion basierendes, kombinierbares KI-Modell, das Inhalte in mehreren Modalitäten, darunter Text, Bilder, Video und Audio, gleichzeitig verarbeiten und erzeugen kann.
Composable Diffusion (CoDi) wird im Rahmen des Microsoft-Projekts i-Code entwickelt, dessen Ziel die Realisierung einer integrativen und kombinierbaren multimodalen KI ist.
CoDi ist ein solches multimodales KI-Modell. Es kann Inhalte in mehreren Modalitäten, einschließlich Text, Bild, Video und Audio, gleichzeitig verarbeiten und generieren. Damit unterscheidet sich CoDi von herkömmlichen generativen KI-Systemen, die auf bestimmte Eingabemodalitäten beschränkt sind.
Da für die meisten Modalitätskombinationen nur wenige Trainingsdatensätze zur Verfügung stehen, haben die Forscher eine Alignment-Strategie entwickelt, die die Modalitäten sowohl im Input- als auch im Outputraum aufeinander abstimmt. Dadurch ist CoDi in der Lage, auf jede beliebige Kombination von Eingaben zu reagieren und jeden beliebigen Satz von Modalitäten zu erzeugen, auch solche, die nicht in den Trainingsdaten enthalten sind.
Herausforderungen bei der Entwicklung cross-modaler KI
CoDi adressiert die Einschränkungen traditioneller monomodaler KI-Modelle und bietet eine Lösung für den oft mühsamen und langsamen Prozess der Kombination modalitätsspezifischer generativer Modelle. Das Modell verwendet eine neuartige, zusammensetzbare Generierungsstrategie, die den Abgleich im Diffusionsprozess überbrückt und die synchrone Generierung von miteinander verknüpften Modalitäten, wie z.B. synchronisierte Video- und Audiodaten, erleichtert.
Video: Microsoft
Neu ist auch das Trainingsverfahren von CoDi. Es beinhaltet die Projektion von Eingabemodalitäten wie Bilder, Video, Audio und Sprache in einen gemeinsamen semantischen Raum. Das ermöglicht eine flexible Verarbeitung multimodaler Eingaben, und mit einem Cross-Attention-Modul und einem Umgebungscodierer ist es in der Lage, beliebige Kombinationen von Ausgabemodalitäten gleichzeitig zu erzeugen.
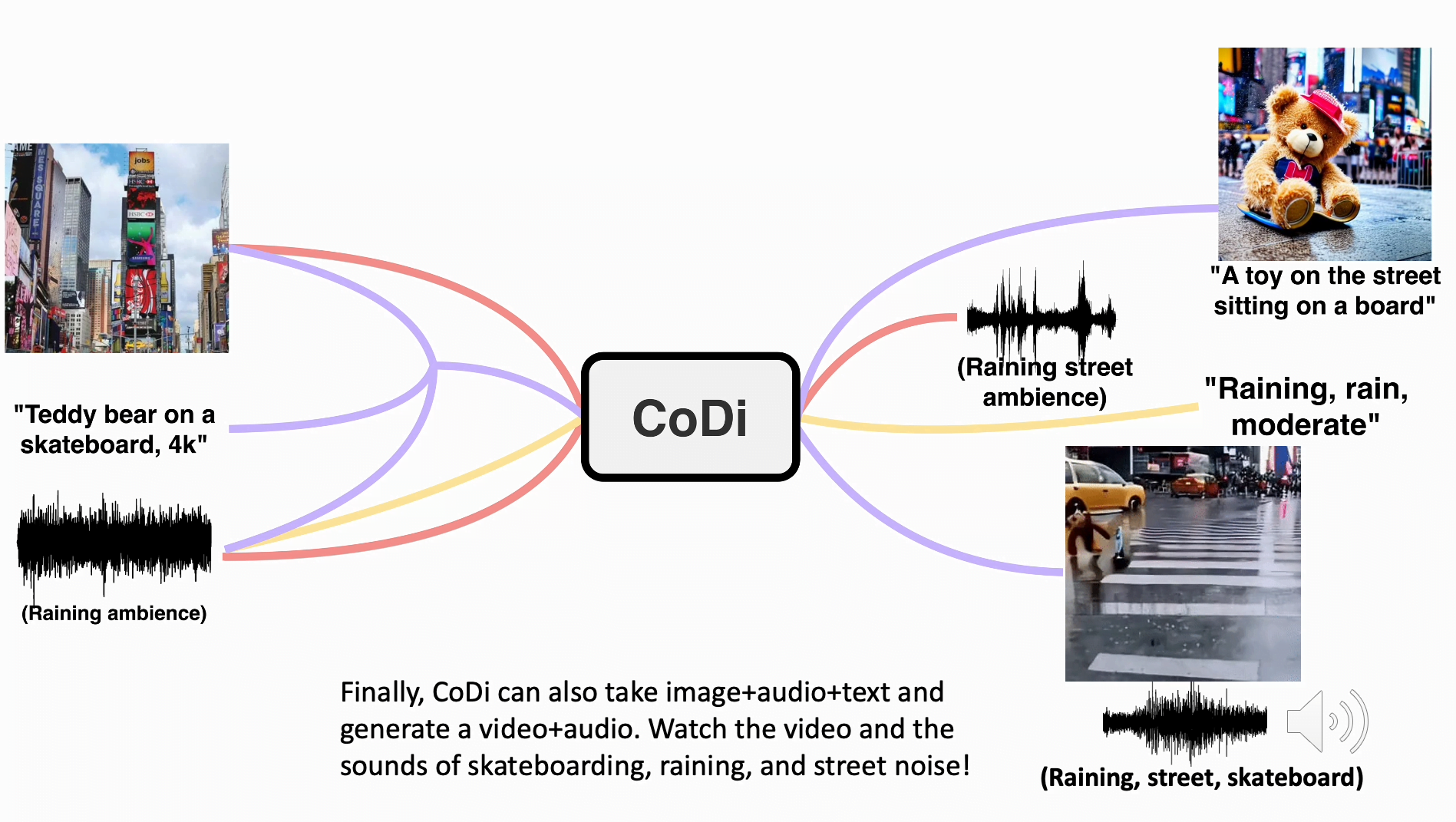
"Teddybär auf einem Skateboard, 4k, hohe Auflösung"
Die Forscher geben Beispiele für die Fähigkeiten von CoDi und zeigen, dass es aus getrennten Text-, Audio- und Bildeingaben synchronisierte Video- und Audiodaten erzeugen kann.
In einem Beispiel enthält der Prompt den Text "Teddybär auf Skateboard, 4k, high resolution", ein Bild vom Times Square und das Geräusch von Regen.
CoDi erzeugt daraufhin ein kurzes, wenn auch qualitativ ausbaufähiges Video eines Teddybären, der im Regen auf dem Times Square Skateboard fährt, begleitet von synchronisierten Regen- und Straßengeräuschen.
Die Anwendungsmöglichkeiten von CoDi sind vielfältig. Die Forscher verweisen auf mögliche Anwendungen in Bereichen wie Bildung und Barrierefreiheit für Menschen mit Behinderungen.
Unsere Arbeit ist ein wichtiger Schritt in Richtung einer ansprechenden und ganzheitlichen Mensch-Computer-Interaktion und bildet eine solide Grundlage für zukünftige Forschung im Bereich der generativen künstlichen Intelligenz.
Aus dem Paper
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.