Neue Methode verbessert Stable Diffusion ohne Trainingsdaten

Stable Diffusion trifft auf Reinforcement Learning - und zeigt, wie effektiv generative KI-Modelle für Bilder auf nachgelagerte Aufgaben trainiert werden können.
Diffusionsmodelle sind heute der Standard in der Bildsynthese und finden auch Anwendung in der Synthese künstlicher Proteine, wo sie bei der Entwicklung von Medikamenten helfen können. Der Diffusionsprozess wandelt zufälliges Rauschen in ein Muster um, also ein Bild oder eine Proteinstruktur.
Während des Trainings lernen die Diffusionsmodelle, Inhalte aus den Trainingsdaten stückweise zu rekonstruieren. In diesen Prozess versuchen Forschende nun mittels Reinforcement Learning einzugreifen, um die generativen KI-Modelle nachträglich auf bestimmte Ziele zu trainieren, etwa um die ästhetische Qualität von Bildern zu verbessern. Das ist inspiriert vom Finetuning großer Sprachmodelle, wie es zum Beispiel bei OpenAI's ChatGPT zum Einsatz kommt.
Reinforcement Learning für ästhetischer Bilder?
Eine neue Arbeit von Berkeley Scientific Intelligence Research untersucht, wie effektiv das Reinforcement Learning mittels Denoising Diffusion Policy Optimization (DDPO) für das Finetuning auf verschiedene Ziele ist.
Das Team trainiert Stable Diffusion auf vier Aufgaben:
- Komprimierbarkeit: Wie gut lässt sich das Bild mit dem JPEG-Algorithmus komprimieren? Die Belohnung ist die negative Dateigröße des Bildes (in kB), wenn es als JPEG gespeichert wird.
- Inkompressibilität: Wie schwierig ist es, das Bild mit dem JPEG-Algorithmus zu komprimieren? Die Belohnung ist die positive Dateigröße des Bildes (in kB), wenn es als JPEG gespeichert wird.
- Ästhetische Qualität: Wie ästhetisch ist das Bild für das menschliche Auge? Die Belohnung ist die Ausgabe des LAION Ästhetik-Prädiktors, einem neuronalen Netz, das auf der Basis menschlicher Vorlieben trainiert wurde.
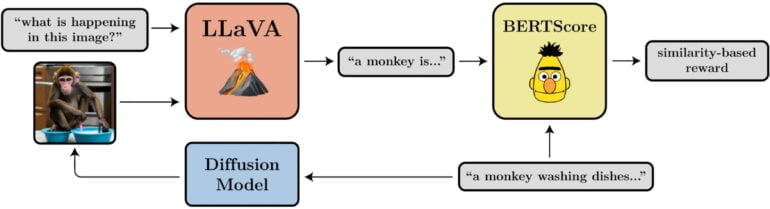
- Prompt-Bild-Alignment: Wie gut stellt das Bild das dar, was in der Aufforderung gefordert wird? Dies ist etwas komplizierter: Wir geben das Bild in LLaVA ein, lassen es beschreiben und berechnen dann mit BERTScore die Ähnlichkeit zwischen dieser Beschreibung und der ursprünglichen Aufforderung.
In ihren Tests konnte das Team zeigen, dass DDPO effektiv für die Optimierung der vier Aufgaben eingesetzt werden kann. Darüber hinaus zeigte sich eine gewisse Generalisierbarkeit: Die Optimierungen für die ästhetische Qualität oder das Prompt-Bild-Alignment wurden beispielsweise für 45 häufige Tierarten durchgeführt, waren aber auch auf andere Tierarten oder die Darstellung unbelebter Objekte übertragbar.
Video: BAIR
Neue Methode benötigt keine Trainingsdaten
Wie bei Reinforcement Learning üblich, zeigt auch DDPO das Phänomen der Überoptimierung hin zur Belohnung: Das Modell zerstört in allen Aufgaben ab einem bestimmten Zeitpunkt alle sinnvollen Bildinhalte, um die Belohnung zu maximieren. Dieses Problem müsse in weiteren Arbeiten untersucht werden.

Dennoch ist die Methode vielversprechend: "Wir haben einen Weg gefunden, Diffusionsmodelle auf eine Weise zu trainieren, die über das Pattern-Matching hinausgeht - und die nicht unbedingt Trainingsdaten erfordert. Die Möglichkeiten sind nur durch die Qualität und Kreativität der Belohnungsfunktion begrenzt."
Mehr Informationen und Beispiele gibt es auf der BAIR-Projektseite zu DDPO.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.