Nvidia Eureka optimiert mit generativer KI das Roboter-Training

Nvidia Research hat den KI-Agenten Eureka entwickelt, der Robotern komplexe Fähigkeiten beibringen kann. Eureka kombiniert die neue generative KI mit der klassischen KI-Technik des maschinellen Reinforcement Learning in einer beschleunigten Simulation.
Insgesamt zehn verschiedene Roboter hat Eureka in um den Faktor 1000 beschleunigten Simulationen 29 unterschiedliche Aufgaben bewältigen lassen. Sie können Schubladen und Schränke öffnen, Bälle werfen und fangen oder Scheren benutzen.
Eine der beeindruckenden Fähigkeiten, die Eureka einem Roboter beigebracht hat, ist das schnelle Drehen eines Bleistifts in der Hand, ähnlich wie es manche Menschen können.
Die Visualisierung dieser Fähigkeit wurde mit Nvidia Omniverse realisiert. Für einen menschlichen CGI-Künstler ist diese Animation laut der beteiligten Forscher sehr aufwendig.
Generative KI schreibt bessere Anweisungen als menschliche Experten
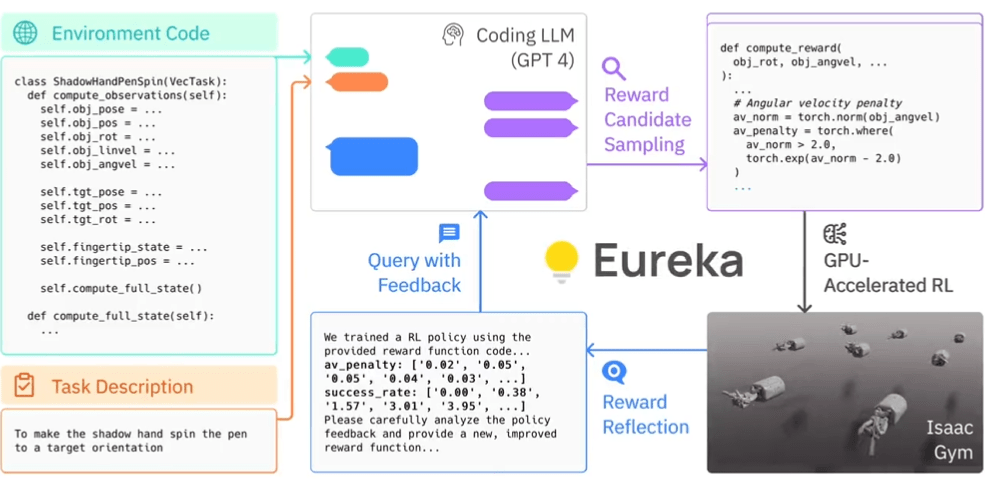
Eureka schreibt selbstständig Belohnungsalgorithmen, um Roboter zu trainieren. Laut einer von Nvidia veröffentlichten Studie sind die von Eureka generierten Belohnungsprogramme in 83 Prozent der Aufgaben besser als die von Experten geschriebenen Programme. Dies führt zu einer durchschnittlichen Verbesserung der Roboterleistung um 52 Prozent.
Zehn verschiedene Robotertypen lernten in der Simulation 29 verschiedene Aufgaben mit Hilfe von Belohnungsprogrammen eines KI-Agenten. | Video: Nvidia
Eureka verwendet OpenAIs GPT-4, um die Belohnungsprogramme zu schreiben, mit denen der Roboter durch Versuch und Irrtum lernt. Das System ist nicht auf aufgabenspezifische Prompts von Menschen oder vordefinierte Belohnungsmuster angewiesen.
Mit der GPU-beschleunigten Simulation in Isaac Gym kann Eureka schnell die Qualität großer Mengen von Belohnungskandidaten für ein effizienteres Training bewerten. Eureka erstellt dann eine Zusammenfassung der wichtigsten Statistiken aus den Trainingsergebnissen und weist das LLM an, die Generierung der Belohnungsfunktionen zu verbessern. Auf diese Weise verbessert der KI-Agent selbständig die Instruktionen des Roboters.
Nvidia fand heraus, dass je komplexer die Aufgabe ist, desto stärker übertreffen die maschinellen Anweisungen des Roboters die menschlichen Anweisungen von Experten, so genannten "Reward Engineers". Der beteiligte Forscher Jim Fan nennt Eureka daher auch einen "Super Human Reward Engineer".
Eureka überbrückt die Lücke zwischen logischem Denken auf hoher Ebene (Codierung) und motorischer Steuerung auf niedriger Ebene. Es handelt sich um eine "hybride Gradientenarchitektur": Ein Black-Box-LLM, das nur auf Inferenz basiert, instruiert ein lernfähiges neuronales Netz in der White-Box. Die äußere Schleife führt GPT-4 aus, um die Belohnungsfunktion zu verfeinern (ohne Gradienten), während die innere Schleife Verstärkungslernen durchführt, um eine Robotersteuerung zu trainieren (mit Gradienten).
Linxi "Jim" Fan, Senior Research Scientist bei NVIDIA
Fang glaubt, dass Eureka neue Möglichkeiten für die Steuerung von Robotern und die Erstellung realistischer Animationen für Künstler bieten wird.
Weiter kann Eureka laut Nvidia menschliches Feedback integrieren, um die Belohnungen besser an die Vorstellungen des Entwicklers anzupassen. Nvidia nennt dieses Verfahren "in-context RLHF" (kontextuelles Lernen aus menschlichem Feedback). Das System könne als eine Art Co-Pilot für Roboterentwickler:innen fungieren, schreibt Fan.
"Die Vielseitigkeit und die signifikanten Leistungsverbesserungen von Eureka deuten darauf hin, dass das einfache Prinzip der Kombination großer Sprachmodelle mit evolutionären Algorithmen ein allgemeiner und skalierbarer Ansatz für die Belohnungsgenerierung ist", schreibt das Forschungsteam.
Nvidia veröffentlicht alle Elemente der Eureka-Forschungsarbeit als Open Source bei Github.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.