OpenChat-Framework soll Open-Source-Sprachmodelle deutlich verbessern

Forscher der Tsinghua Universität, des Shanghai Artificial Intelligence Laboratory und 01.AI haben ein neues Framework namens OpenChat entwickelt, um Open-Source-Sprachmodelle mit gemischter Datenqualität zu verbessern.
Open-Source-Sprachmodelle wie LLaMA und LLaMA2, die es jedermann ermöglichen, den Programmcode einzusehen und zu verstehen, werden häufig durch spezielle Techniken wie Supervised Fine-Tuning (SFT) und Reinforcement Learning Fine-Tuning (RLFT) verfeinert und optimiert.
Diese Techniken gehen jedoch häufig davon aus, dass alle verwendeten Daten von gleicher Qualität sind. In der Praxis besteht ein Datensatz jedoch oft aus einer Mischung von optimalen und relativ schlechten Daten. Das kann sich negativ auf die Leistung von Sprachmodellen auswirken.
Um dieses Problem zu lösen, verwendet OpenChat eine neue Methode namens Conditioned-RLFT (C-RLFT). Diese Methode behandelt verschiedene Datenquellen als verschiedene Klassen, die als grobe Belohnungslabel dienen, ohne dass bevorzugte Daten speziell gelabelt werden müssen.
Vereinfacht ausgedrückt lernt das System, dass einige Daten exzellent sind, während andere relativ schlecht sind, und gewichtet sie entsprechend, ohne dass die Daten explizit gekennzeichnet werden müssen.
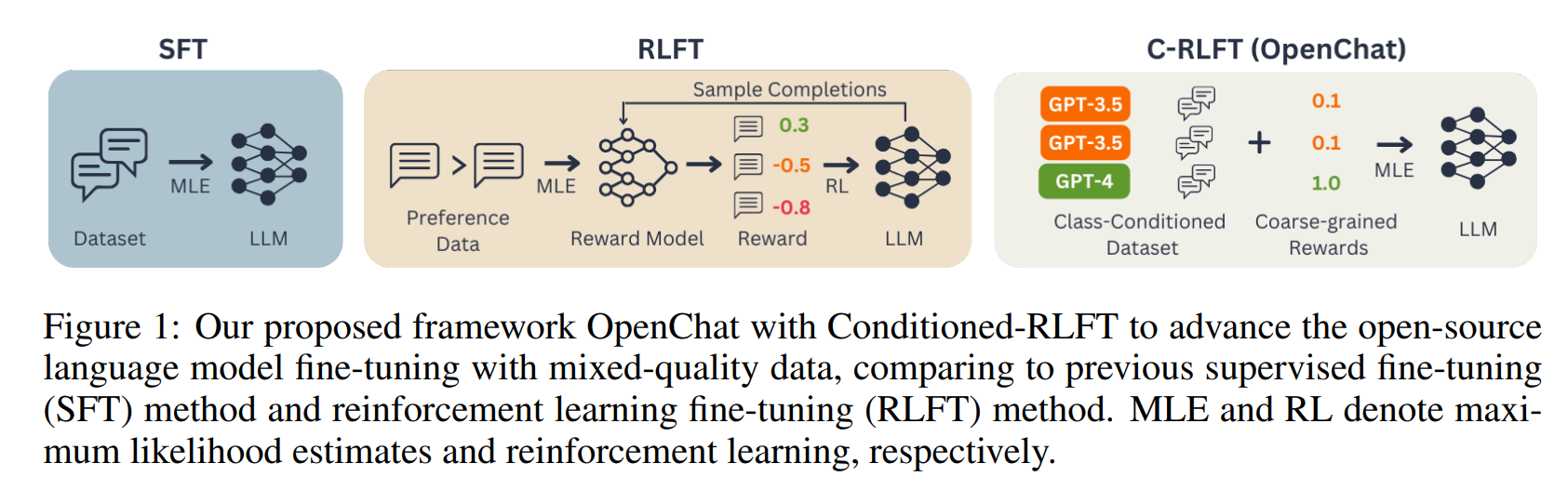
Da keine komplexen Verfahren des Reinforcement Learning oder teures menschliches Feedback nötig sind, ist C-RLFT relativ einfach zu implementieren. Den Forschern zufolge genügt ein einstufiges, RL-freies überwachtes Lernen, bei dem die KI aus wenigen Beispielen mit richtigen Antworten lernt, ohne auf Versuch-und-Irrtum-Methoden wie beim Reinforcement Learning zurückgreifen zu müssen. Das spart Zeit und Rechenleistung.
C-RLFT sorgt für hohe Benchmark-Performance
Gegenüber anderen Verfahren hat C-RLFT mehrere Vorteile. Es ist weniger abhängig von der Datenqualität, da es mit einer Mischung aus guten und schlechten Daten arbeiten kann. Die Methode ist einfacher zu implementieren als andere, da sie keine aufwendigen Lern- und Evaluierungsprozesse erfordert, und sie ist robust, da sie gezielt unterschiedliche Datenqualitäten nutzt. Da das Verfahren nicht auf teures menschliches Feedback angewiesen ist, ist C-RLFT auch kosteneffizient.
In ersten Tests schneidet das mit C-RLFT verfeinerte OpenChat-13b-Modell besser ab als alle anderen getesteten Sprachmodelle und kann sogar deutlich größere Modelle wie Llama 2 70B im MT-bench übertreffen.
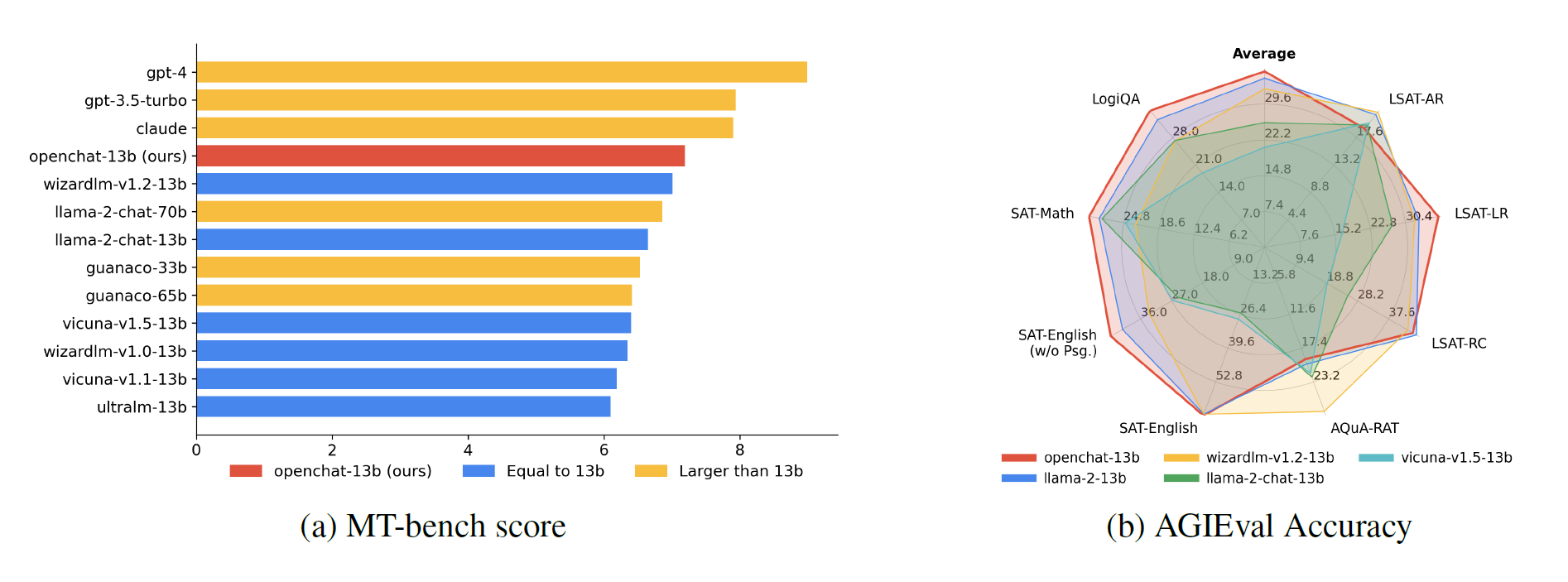
Die Benchmarks oben stammen aus dem C-RLFT-Paper von Ende September. Das Anfang November veröffentlichte Modell OpenChat-3.5-7B-Modell mit 8K-Kontextfenster soll laut des Forschungsteams sogar ChatGPT in einigen Benchmarks übertreffen.
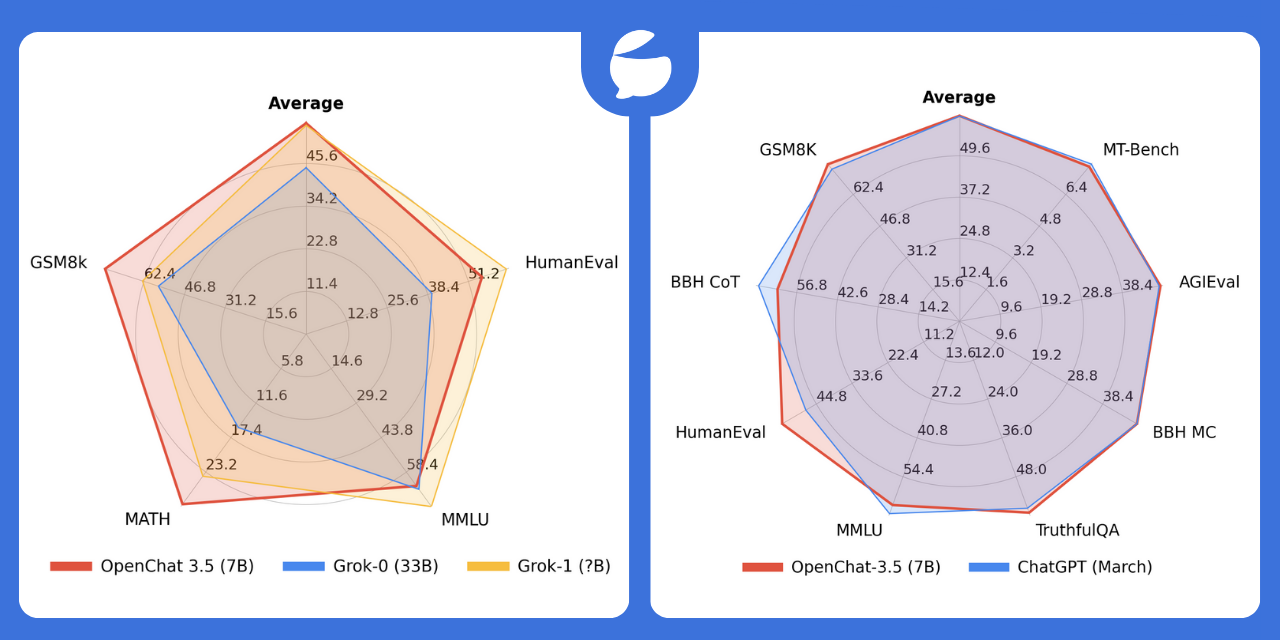
Die Forscher sehen noch Raum für Verbesserungen. So könnte beispielsweise die Verteilung der Belohnungen auf die verschiedenen Datenquellen weiter verfeinert werden. Außerdem könnte die Methode in Zukunft auch eingesetzt werden, um die Fähigkeiten von Sprachmodellen in anderen Bereichen zu verbessern, zum Beispiel beim logischen Schlussfolgern.
Das OpenChat-System und alle damit verbundenen Daten und Modelle sind auf Github öffentlich zugänglich. Eine Online-Demo ist hier zugänglich. Die OpenChat-v3-Modelle basieren auf Llama und sind nach der Llama-Lizenz kommerziell nutzbar.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.