Google startet Gemini Pro API-Zugang
Google bietet Entwicklern Zugang zu Gemini Pro, seiner neuen multimodalen KI, die Text- und Bildeingaben verarbeiten kann.
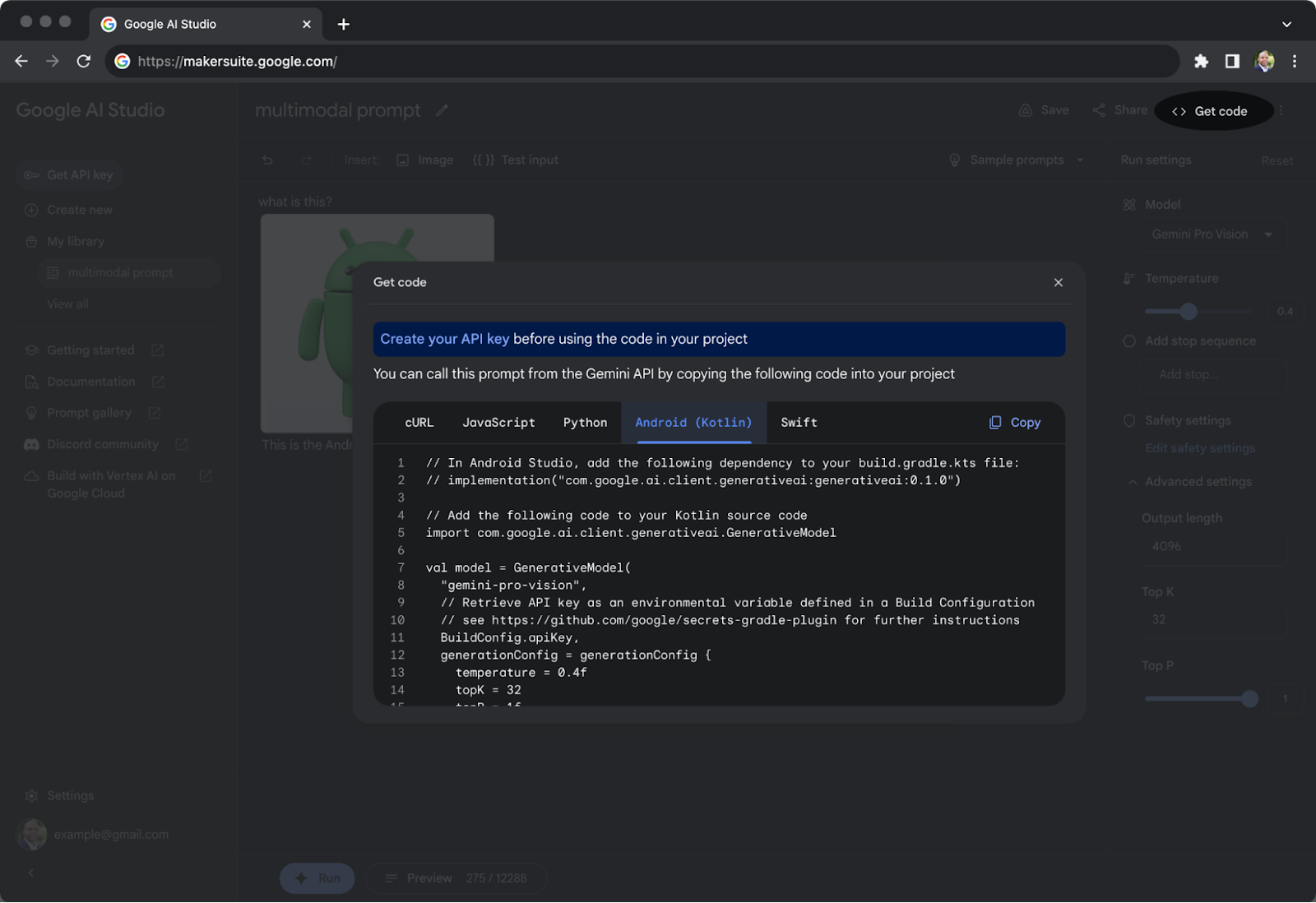
Das Modell, das in den Rechenzentren von Google läuft, ist über die Gemini-API zugänglich und kann mit dem Google AI SDK, einem Client-SDK für Android, integriert werden. Das SDK befreit Entwickler laut Google von der Notwendigkeit, eine eigene Backend-Infrastruktur aufzubauen.
Entwickler können Gemini Pro integrieren, API-Schlüssel generieren und KI-Anwendungen über das Google AI Studio erstellen. Google hat nach eigenen Angaben die Nutzung der Gemini-API für Entwickler mit einer neuen Projektvorlage in der neuesten Vorschau von Android Studio vereinfacht.
In der vergangenen Woche hat Google bereits den Zugang zu Gemini Nano freigegeben, einem On-Device-Modell, das auf ausgewählten Geräten über AICore verfügbar ist. Nano wird auf dem neuen Google Pixel 8 laufen.
Die MLLM-Benchmark-Kriege sind eröffnet
Die Leistung von Gemini Pro entspricht in etwa der von GPT-3.5. Laut Google übertrifft Gemini Pro das OpenAI-Modell in sechs von acht Benchmarks. Google hat auch seinen ChatGPT-Konkurrenten Bard mit Gemini Pro aktualisiert.
Googles GPT-4-Konkurrent Ultra wird Anfang nächsten Jahres folgen. Google hat gezeigt, dass es mit speziellen Prompting-Methoden GPT-4 in wichtigen Benchmarks wie MMLU schlagen kann. Microsoft hat inzwischen geantwortet, dass GPT-4, ebenfalls durch spezielle Prompting-Methoden gesteuert, in Benchmarks genauso gut, wenn nicht sogar besser ist.
Microsoft hat kürzlich zudem Phi-2 vorgestellt, wie Nano ein kleines, großes Sprachmodell, das für die Leistung auf dem Gerät optimiert ist. Phi-2 übertrifft Googles Gemini Nano in allen von Microsoft vorgestellten Benchmarks.
Interessanter wird sein, wie sich das Modell in realen Szenarien verhält. Hier zählt die Leistung, und kann von den in Benchmarks gemessenen Werten abweichen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.