
Microsoft gibt an, dass GPT-4 in Verbindung mit einer speziellen Prompting-Strategie eine höhere Punktzahl im MMLU-Benchmark (Measuring Massive Multitask Language Understanding) erreicht als Google Gemini Ultra.
Medprompt ist eine kürzlich von Microsoft vorgestellte Prompting-Strategie, die ursprünglich für medizinische Herausforderungen entwickelt wurde. Microsoft-Forschende stellten jedoch fest, dass sie auch für allgemeinere Anwendungen geeignet ist.
Durch die Ansteuerung von GPT-4 mit einer modifizierten Version von Medprompt hat Microsoft nun einen neuen State-of-the-Art (SoTA) Wert im MMLU Benchmark erreicht.
Die Ankündigung von Microsoft ist insofern besonders, als Google bei der großen Enthüllung seines neuen KI-Modells Gemini Ultra den neuen Bestwert des Ultra-Modells im MMLU-Benchmark besonders hervorhob.
Komplexe Prompts für bessere Benchmark-Ergebnisse: Microsoft trickst zurück
Schon die Kommunikation von Google bei der Vorstellung von Gemini war nicht ganz sauber: Das Modell erzielte zwar den bislang besten Wert im MMLU, aber mit einer komplexeren Prompting-Strategie als in diesem Benchmark Standard. Mit der Standard-Prompting-Strategie (5-Shot) schneidet Gemini Ultra im MMLU schlechter ab als GPT-4.
Die jetzt von Microsoft mit Medprompt+ kommunizierte GPT-4-Leistung im MMLU erreicht einen Rekordwert von 90,10 Prozent und übertrifft damit den Wert von Gemini Ultra von 90,04 Prozent.
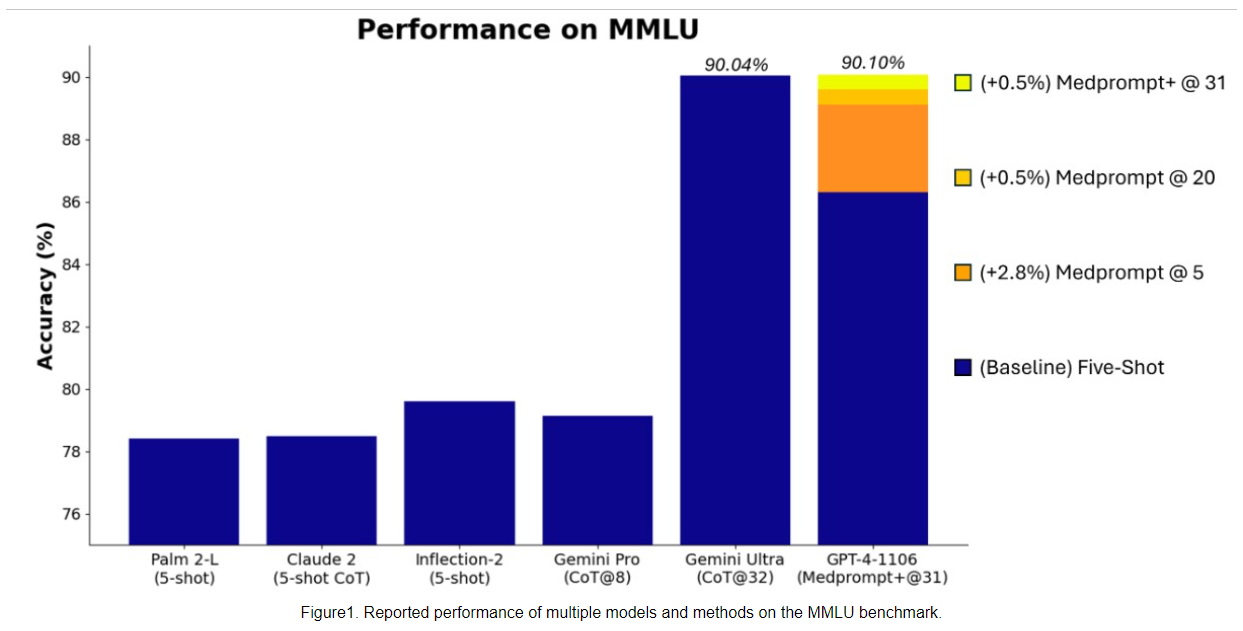
Um dieses Ergebnis zu erzielen, erweiterten die Microsoft-Forscher Medprompt zu Medprompt+, indem sie nach eigenen Angaben Medprompt eine einfachere Prompting-Methode hinzufügten und eine Strategie zur Ableitung einer endgültigen Antwort formulierten, die Antworten sowohl der grundlegenden Medprompt-Strategie als auch der einfachen Prompting-Methode kombiniert.
Der MMLU-Benchmark ist ein umfassender Test des Allgemeinwissens und des logischen Denkens. Er umfasst Zehntausende von Aufgaben aus 57 Fachgebieten, darunter Mathematik, Geschichte, Recht, Informatik, Ingenieurwesen und Medizin. Für Sprachmodelle gilt er als der wichtigste Benchmark.
GPT-4 soll Gemini Ultra in noch mehr Benchmarks übertreffen
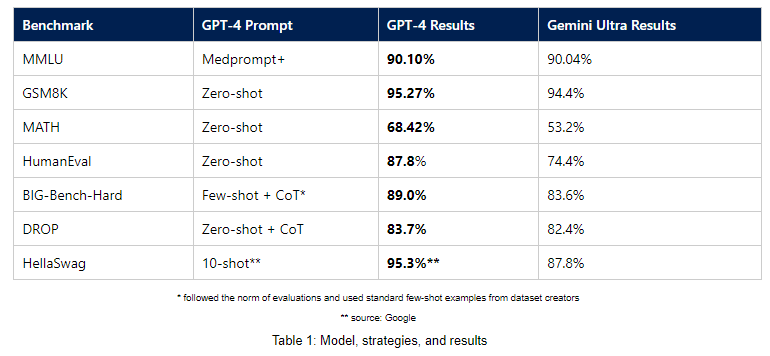
Neben dem MMLU-Benchmark hat Microsoft Ergebnisse für weitere Benchmarks zur Verfügung gestellt, die die Leistung von GPT-4 mit einfachen, für diese Benchmarks üblichen Prompts im Vergleich zu Gemini Ultra zeigen. GPT-4 soll Gemini Ultra nach dieser Messmethode in verschiedenen Benchmarks übertreffen, darunter GSM8K, MATH, HumanEval, BIG-Bench-Hard, DROP und HellaSwag.

Microsoft veröffentlicht Medprompt und andere Ansätze in einem GitHub-Repository namens Promptbase. Das Repository enthält Skripte, allgemeine Werkzeuge und Informationen, die helfen sollen, die Ergebnisse zu reproduzieren und die Leistung der Basismodelle zu verbessern.
Die meist geringen Unterschiede in den Benchmarks dürften in der Praxis keine große Rolle spielen, sie dienen Microsoft und Google vor allem zu PR-Zwecken. Was Microsoft hier jedoch untermauert und was sich bereits bei der Ankündigung von Ultra andeutete, ist, dass beide Modelle wohl gleichauf liegen.
Das könnte bedeuten, dass OpenAI entweder Google voraus ist - oder es sehr schwierig sein wird, ein deutlich leistungsfähigeres KI-Modell als GPT-4 zu entwickeln. Möglicherweise stößt die LLM-Technologie in ihrer jetzigen Form bereits an ihre Grenzen. GPT-4.5 oder GPT-5 von OpenAI könnten hier Klarheit schaffen.




