Microsofts "Interactive Agent Foundation Model" lernt in Minecraft

Foundation-Modelle bestimmen die Forschung. Microsoft stellt nun ein "Interactive Agent Foundation Model" vor, das besser in der virtuellen und echten Welt zurechtkommen soll.
Forschende von Microsoft Research, der Stanford University und der University of California stellen in ihrer neuen Arbeit das Interactive Agent Foundation Model vor, das für eine Vielzahl von Anwendungen mit Text-, Bild- und Aktionsdaten trainiert wurde.
Das Team verwendet ein einheitliches Framework, das verschiedene Pre-Trainings-Strategien für Bild, Text und Aktion kombiniert. Mit dieser Arbeit will das Team die Machbarkeit eines solchen vielseitigen und anpassungsfähigen KI-Frameworks demonstrieren und testete es in drei Domänen: Robotik, Spiele-KI und Gesundheitswesen.
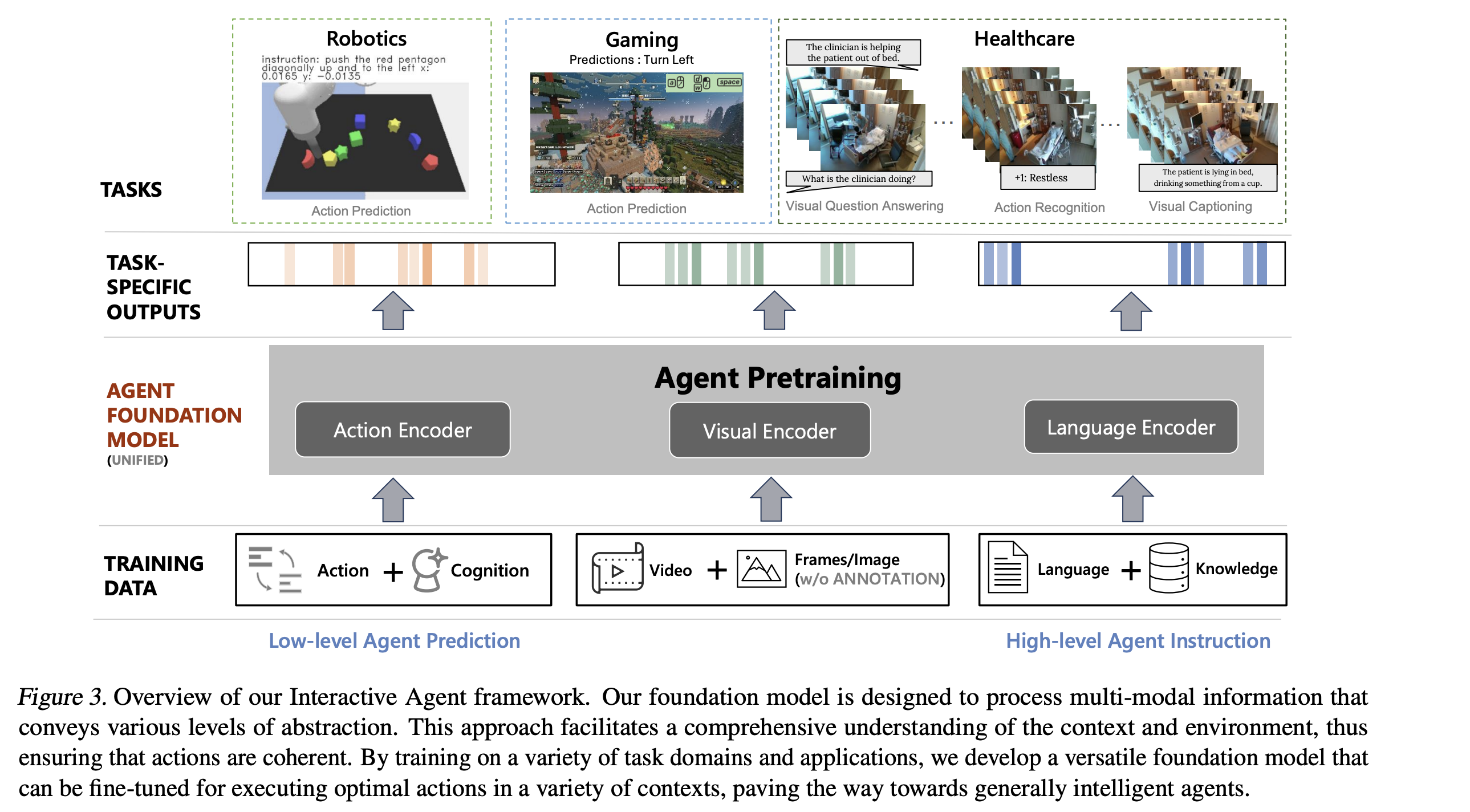
Das Modell mit 277 Millionen Parametern wurde mit 13,4 Millionen Videoframes vortrainiert. Diese umfassten eine Vielzahl von Robotik- und Spielaufgaben, einschließlich Minecraft, wobei die Daten neben den Videos auch Textbeschreibungen und Aktionstoken für Roboter enthielten.
In Tests hat das Modell gezeigt, dass es in der Lage ist, Aktionen in einer Vielzahl von Domänen effektiv zu modellieren, etwa die Steuerung eines Roboters oder die Vorhersage von Aktionen in Minecraft. Das Team zeigte auch, dass das Modell in Bereichen wie dem Gesundheitswesen eingesetzt werden kann, wo es mit zusätzlichen Video- und Textdaten verfeinert wurde und seine Leistung von den anderen Datenquellen profitierte.
Microsofts "Interactive Agent Foundation Model" als Embodied Agent
Die Arbeit ist als Beitrag zur Grundlagenforschung auf dem Weg von statischen, aufgabenspezifischen Modellen zu dynamischen, agentenbasierten Systemen zu verstehen und erinnert an Arbeiten wie Deepminds GATO.
Die Forscher betonen dabei die Notwendigkeit, dynamisches Verhalten zu generieren, das in einem Verständnis der Umgebungskontexte verankert ist. Zu diesem Zweck definieren sie auch ein neues Paradigma für verkörperte Agenten:
Wir definieren das Embodied-Agent-Paradigma als "jeden intelligenten Agenten, der in der Lage ist, auf der Grundlage von Sinneseindrücken autonom angemessene und nahtlose Aktionen auszuführen, sei es in der physischen Welt oder in einer virtuellen oder gemischten realen Umgebung, die die physische Welt repräsentiert".
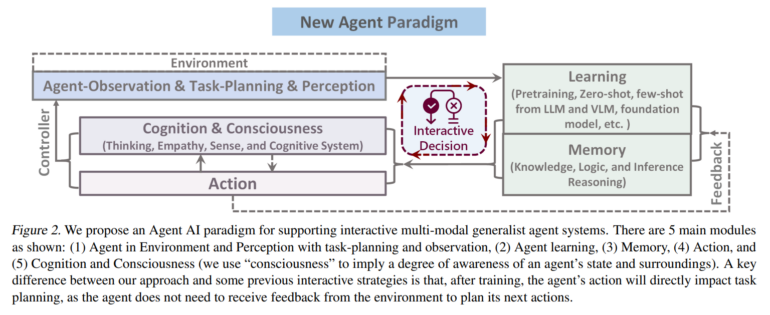
Es sei wichtig, dass ein verkörperter Agent als Mitglied eines kollaborativen Systems konzipiert wird, in dem er mit Menschen kommuniziert und eine Vielzahl von Aktionen ausführt, die auf den Bedürfnissen von Menschen basieren. Auf diese Weise, so das Team, können verkörperte Agenten mühsame Aufgaben in der virtuellen und physischen Welt erleichtern.
Die Forscher wollen ihren Code und Modelle demnächst öffentlich zugänglich machen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.