MM1: Apple stellt multimodales KI-Modell mit hohem visuellem Verständnis vor
Mit MM1 stellt Apple ein leistungsfähiges multimodales KI-Modell vor, das es dank intelligenter Architektur und umfangreichem Training mit GPT-4V und Google Gemini aufnehmen kann. Ein ausführliches Paper gibt erste Einblicke.
Apple hat mit MM1 ein multimodales KI-Modell entwickelt, das durch umfangreiches Training mit Bild- und Textdaten eine für seine Größe beeindruckende Leistungsfähigkeit erreicht hat.
Wie GPT-4V und Gemini basiert MM1 auf der Architektur der Large Language Models (LLMs) und wurde mit einer Mischung aus Bild-Text-Paaren, verschachtelten Bild-Text-Dokumenten und reinen Textdaten trainiert (45 % Bild-Text-Paare, 45 % verschachtelte Bild-Text-Dokumente, 10 % reine Textdaten).
Dadurch erlangte das Modell ähnliche Fähigkeiten wie seine Konkurrenten, darunter Bildbeschreibung, Beantwortung von Fragen und sogar grundlegende Mathematik.
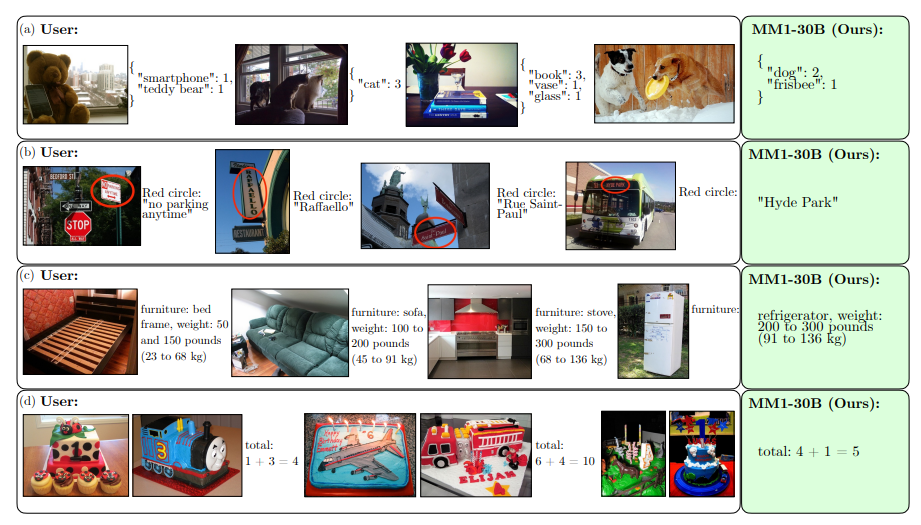
Die Apple-Forscher untersuchten im Detail, welche Faktoren, wie Architekturkomponenten und Trainingsdaten, den stärksten Einfluss auf die Leistung von MM1 haben. Sie fanden heraus, dass eine hohe Bildauflösung, die Leistung des Bildverarbeitungsteils (des sogenannten "visuellen Encoders") und die Menge der Trainingsdaten besonders wichtig sind, während die Verbindung zwischen Bild und Sprache weniger entscheidend ist.
Der visuelle Encoder ist dafür zuständig, die Bildinformationen in eine Form zu bringen, die das KI-System verarbeiten kann. Je leistungsfähiger dieser Encoder ist, desto besser kann MM1 den Bildinhalt verstehen und interpretieren.
Auch die richtige Mischung der Trainingsdaten spielt eine große Rolle: Für gute Ergebnisse mit wenigen Beispielen im Prompt waren Bild-Text-Paare, gemischte Bild-Text-Daten und reine Textdaten entscheidend. Musste MM1 dagegen ohne Beispiele im Prompt auskommen, waren primär Bild-Text-Paare in den Trainingsdaten für das Generierungsergebnis ausschlaggebend.
Bild-Text-Paare (image-caption pairs oder image-text pairs) sind Daten, bei denen jedes Bild direkt mit einem zugehörigen Text gepaart ist. Dieser Text ist typischerweise eine Beschreibung oder Erklärung des Bildinhalts.
Ein Beispiel wäre ein Bild von einem Hund mit der Beschriftung "Ein brauner Hund spielt mit einem Ball im Park". Solche paarweisen Daten werden häufig verwendet, um Modelle für Aufgaben wie automatische Bildbeschriftung zu trainieren.
Bild-Text-Daten (interleaved image-text) hingegen sind Daten, in denen Bilder und Texte in gemischter Reihenfolge auftreten, ohne dass jedes Bild notwendigerweise direkt mit einem bestimmten Text verknüpft ist.
Ein Beispiel wäre ein Nachrichtenartikel, der aus einer Mischung von Bildern und Textabschnitten besteht, die sich auf dasselbe Thema beziehen, aber nicht unbedingt in einer 1:1-Beziehung stehen. Solche Daten spiegeln eher die Art und Weise wider, wie visuelle und textuelle Informationen in natürlichen Kontexten oft zusammen auftreten.
Im Kontext des Papers hat sich gezeigt, dass eine Mischung aus beiden Datentypen - also sowohl Bild-Text-Paare als auch gemischte Bild-Text-Daten - zusammen mit reinen Textdaten für das Training von multimodalen KI-Modellen vorteilhaft ist, insbesondere wenn es darum geht, mit wenigen Beispielen gute Ergebnisse zu erzielen (Few-Shot Learning).
30 Milliarden Parameter können für State-of-the-Art-Ergebnisse ausreichen
Durch die Skalierung auf bis zu 30 Milliarden Parameter und die Verwendung von Mixture-of-Experts (MoE)-Modellen, eine spezielle Technik, bei der mehrere spezialisierte KI-Modelle zusammenarbeiten, erzielte MM1 überzeugende Ergebnisse. Es übertraf die meisten veröffentlichten Modelle im Few-Shot-Learning für Bildunterschriften und visuelle Frage-Antwort-Generierung.
MM1 zeigt seine Stärken auch in komplexeren Szenarien. Es kann Informationen aus mehreren Bildern kombinieren, um komplexe Fragen zu beantworten oder Schlussfolgerungen zu ziehen, die sich nicht aus einem einzelnen Bild ableiten lassen, sogenanntes Multi-Image-Reasoning.

Nach einem weiteren Training mit ausgewählten Daten, dem so genannten "Supervised Fine-Tuning" (SFT), erzielte MM1 auch in zwölf etablierten Vergleichstests konkurrenzfähige Ergebnisse. Damit könnte es in Zukunft zu einem ernsthaften Konkurrenten für andere führende KI-Systeme wie GPT-4V und Google Gemini werden.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.