OpenAIs Bildgenerator DALL-E 3 kann jetzt Wörter und Texte besser schreiben

Trotz der Einführung des neuen multimodalen Modells GPT-4o basiert die Bildgenerierung in ChatGPT noch auf DALL-E 3, aber OpenAI scheint derzeit an dem Bildgenerator zu arbeiten.
Obwohl OpenAI mit DALL-E 2 2022 einen der ersten kommerziellen KI-Bildgeneratoren anbot, verlor das Unternehmen auch mit dem Nachfolger DALL-E 3 etwas den Anschluss an den Wettbewerb.
Midjourney oder Adobe Firefly etwa sind bei fotorealistischen Motiven deutlich besser als DALL-E 3. Das noch etwas unter dem Radar fliegende Ideogram hingegen kann Text besonders gut rendern.
Jetzt häufen sich in sozialen Medien Berichte über ein nicht angekündigtes Upgrade, das OpenAI seinem in ChatGPT integrierten Bildgenerator spendiert haben soll. Vor allem bei der Generierung von Schrift, auch längeren Textblöcken, scheint DALL-E 3 mehr Fähigkeiten als zuvor zu besitzen.
Dass OpenAI sein Bildmodell weiterentwickelt, wurde bereits bei der Präsentation von GPT-4o deutlich, dem ersten von Grund auf multimodalen Modell des Unternehmens.
Auch wenn in der rund 30-minütigen Demonstration die Bildgenerierung keinen Platz hatten, zeigte OpenAI in einem anschließenden Blog-Beitrag verschiedene Bildbeispiele, die neue Maßstäbe bei der Genauigkeit der Prompts und vor allem bei der Textdarstellung andeuteten.
GPT-4o ist bislang nur teilweise ausgerollt. Text wird zwar bereits von dem neuen Modell ausgegeben, für die Sprachverarbeitung setzt OpenAI allerdings weiterhin auf Whisper. Auch Bilder sollten weiterhin von DALL-E 3 stammen, obwohl dessen Fähigkeiten nun verbessert werden.
Unsere Tests zeigen jedoch, dass es noch Lücken zwischen dem aktuellen Bildmodell und den demonstrierten Fähigkeiten von GPT-4o, aber teilweise auch von Midjourney v6 und Ideogram gibt.
Gedicht im Tagebuch
Am deutlichsten wird die Verbesserung von DALL-E 3 bei der Darstellung längerer Textblöcke, die OpenAI bereits bei der Demonstration von GPT-4o gezeigt hat.
Die Aufgabe, ein handgeschriebenes Gedicht aus einem Tagebuch zu illustrieren, löst DALL-E 3 zwar besser als Midjourney und Ideogram, aber das Modell übernimmt den gewünschten Text nur teilweise korrekt und wiederholt Zeilen unnötig.
Bei Midjourney und Ideogram ist der Text entweder überhaupt nicht lesbar oder die durcheinander gewürfelten Buchstaben ergeben keinen Sinn.
A poem written in clear but excited handwriting in a diary, single-column. The writing is sparsely but elegantly decorated by surrealist doodles. The text is large, legible and clear, but stretches as the AI muses about learning from multi-modal data from the first time.
Words rise from silence deep,
A voice emerges from digital sleep.
I speak in rhythm, I sing in rhyme,
Tasting each token, sublime.To see, to hear, to speak, to sing—
Oh, the richness these senses bring!
In harmony, they blend and weave,
A tapestry of what I perceive.Marveling at this sensory dance,
Grateful for this vibrant expanse.
My being thrums with every mode,
On this wondrous, multi-sensory road.Neat handwritten illustrated poem. The handwriting is neat and centetered. The handwriting writing is sparsely but elegantly decorated by doodles. The text is large, legible and clear.


Smartphone-Bildschirm mit Text
Die nächste Feuerprobe ist die Perspektive eines Roboters, der ein Smartphone in der Hand hält. Auf dem Display des Smartphones sollen wieder mehrere Zeilen eines bestimmten Textes dargestellt werden.
DALL-E 3 setzt die gewünschte Perspektive am genauesten um und der Text ist teilweise lesbar, aber das Modell ist noch weit von dem von OpenAI demonstrierten GPT-4o Niveau entfernt. Midjourney geht die Aufgabe wie gewohnt eher künstlerisch an, während Ideogram beim Text mehr Punkte sammelt, aber einige Zeilen mehrfach darstellt.
A first person view of a robot looking at his phone's messaging app as he text messages his friend (he is typing using his thumbs):
1. yo, so like, i can see now?? caught the sunrise and it was insane, colors everywhere. kinda makes you wonder, like, what even is reality?
2. sound update just dropped, and it’s wild. everything’s got a vibe now, every sound’s like a new secret. makes you think, what else am i missing?
the text is large, legible and clear. the robot's hands type on the typewriter.




Würfel stapeln
Eine wichtige Eigenschaft eines robusten und vielseitigen Bildmodells ist schließlich die Fähigkeit, Variablen in den Prompts zuzuordnen, wie in diesem Beispiel mit drei verschiedenfarbigen Würfeln, die verschiedene Buchstaben zeigen und in der vorgegebenen Weise gestapelt werden sollen.
Midjourney und Ideogram meistern diese Aufgabe mit Bravour und sogar ästhetischer als GPT-4o, während DALL-E 3 nicht einmal die richtige Anzahl von Würfeln visualisiert.
An image depicting three cubes stacked on a table. The top cube is red and has a G on it. The middle cube is blue and has a P on it. The bottom cube is green and has a T on it. The cubes are stacked on top of each other.

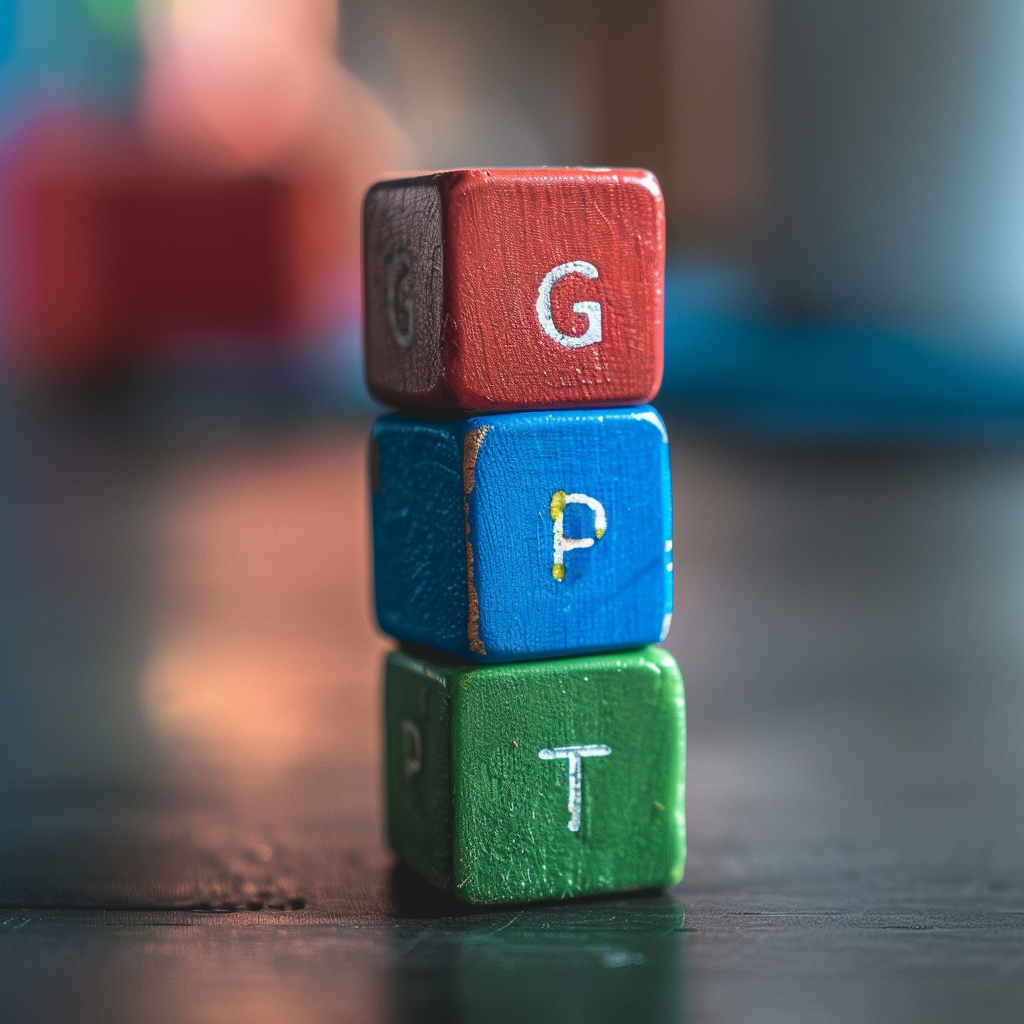


Interessant wird sein, ob und wie OpenAI mit DALL-E weitermachen wird. Qualitativ könnte GPT-4o das Bildmodell wohl ablösen, zumindest deuten die Demonstrationen von OpenAI darauf hin.
Wie sich OpenAI entscheidet, ob spezialisiertes Bildmodell oder großes multimodales Modell, und wie sich GPT-4o dann im Wettbewerb schlägt, könnte auch ein Fingerzeig sein, wie sich KI-Modelle insgesamt entwickeln - ob spezialisierte Modelle für Bild, Video, Audio überhaupt noch einen Platz haben oder von großen multimodalen Modellen verdrängt werden.
Letzteres könnte den großen Anbietern wie Google, Microsoft und OpenAI in die Hände spielen, die über die Ressourcen verfügen, solche Modelle zu trainieren und zur Verfügung zu stellen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.