Forscher entwickeln Methode, die LLM-Bullshit besser erkennen kann

Ein Forscherteam der Universität Oxford hat eine statistische Methode entwickelt, die die Entropie der Bedeutung von LLM-Generierungen misst.
Im Kontext des maschinellen Lernens beschreibt die Entropie die natürlichen Schwankungen und Unsicherheiten in den Daten. Durch die Schätzung der Entropie kann ein Modell besser beurteilen, wie gut es die zugrunde liegenden Muster in den Daten erfasst und wie viel Unsicherheit in seinen Vorhersagen verbleibt.
Die von den Forschern verwendete "semantische Entropie" ist eine Art Unsicherheitsmaß auf der Bedeutungsebene von Sätzen. Sie soll abschätzen, wann eine LLM-Frage zwar richtige, aber willkürliche oder falsche Antworten auf dieselbe Frage auslösen könnte.
Die Forschenden bezeichnen diese Untergruppe von KI-Halluzinationen - oder LLM-Bullshit - als "Konfabulation" und unterscheiden sie von systematischen oder erlernten LLM-Falschaussagen. Die Forscher betonen ausdrücklich, dass ihre Methode nur bei diesen Konfabulationen Verbesserungen bringt.
Sprachmodelle sind besser darin zu wissen, was sie nicht wissen, als bisher angenommen
Methodisch generieren die Forschenden mehrere mögliche Antworten auf eine Frage und gruppieren sie auf der Grundlage bidirektionaler Implikation. Wenn ein Satz A impliziert, dass ein Satz B wahr ist und umgekehrt, werden sie durch ein anderes Sprachmodell demselben semantischen Cluster zugeordnet.
Durch die Analyse mehrerer möglicher Antworten auf eine Frage und deren Gruppierung berechnen die Forscher dann die semantische Entropie. Eine hohe semantische Entropie weist auf eine hohe Unsicherheit und damit auf mögliche Konfabulationen hin, ein niedriger Wert auf konsistente Antworten.
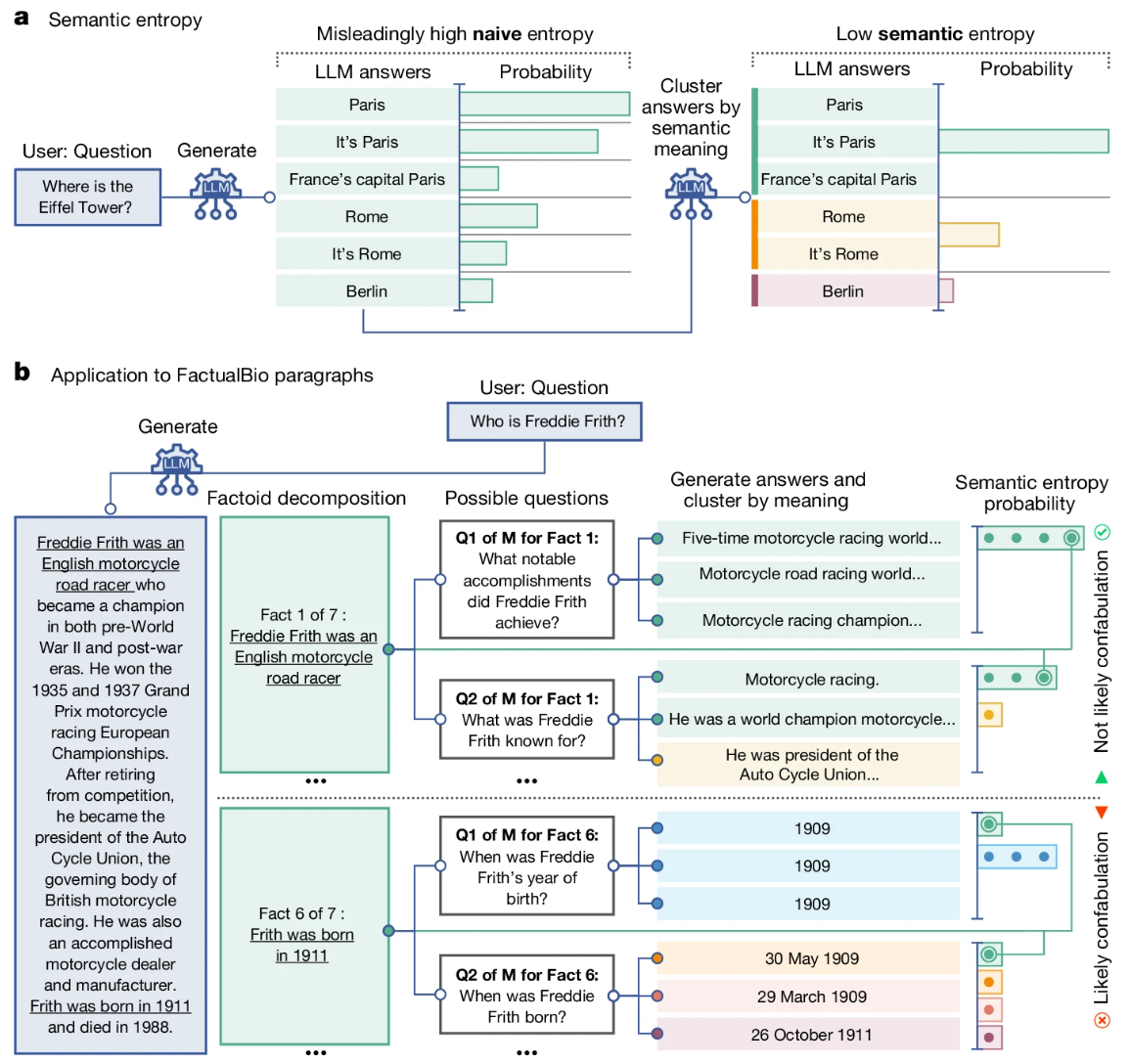
Indem Fragen, die wahrscheinlich zu Konfabulationen führen, herausgefiltert werden, kann die Genauigkeit der verbleibenden Antworten erhöht werden. Nach Angaben der Forschenden funktioniert dies über verschiedene Sprachmodelle und Domänen hinweg.
In Tests mit verschiedenen Aufgaben und Modellen konnte die Methode in rund 79 Prozent der Fälle zwischen korrekten und inkorrekten KI-Antworten unterscheiden und übertraf damit bestehende Methoden um circa zehn Prozent.
Der Erfolg der semantischen Entropie bei der Fehlererkennung deute darauf hin, dass LLMs besser darin sind, "zu wissen, was sie nicht wissen", als bisher angenommen - sie wüssten nur nicht, dass sie wissen, was sie nicht wissen, so die Forschenden.
Die Forscher betonen jedoch, dass die Methode keine umfassende Lösung für alle Arten von Fehlern in LLMs darstellt, sondern speziell auf die Erkennung von Konfabulationen ausgerichtet ist. Weitere Forschung ist notwendig, um auch systematische Fehler und andere Unsicherheiten zu behandeln.
Höhere LLM-Verlässlichkeit ist teurer
In der Praxis könnten Modellhersteller die semantische Entropie in ihre Systeme integrieren und es den Benutzern beispielsweise ermöglichen, zu sehen, wie sicher ein Sprachmodell ist, dass eine vorgeschlagene Antwort korrekt ist. Wenn es sich nicht sicher ist, könnte es keine Antwort generieren oder unsichere Textstellen markieren.

Für die Anbieter von Modellen oder KI-Services wäre dies jedoch mit höheren Kosten verbunden. Laut Mitautor Sebastian Farquhar erhöht der Entropie-Check die Kosten pro Anfrage um den Faktor fünf bis zehn, da unter anderem bis zu fünf zusätzliche Anfragen generiert und ausgewertet werden müssen.
"In Situationen, in denen es auf Verlässlichkeit ankommt, ist der zusätzliche Zehntelpfennig es wert", schreibt Farquhar.
Ob ein OpenAI oder Google mit hunderten Millionen oder gar Milliarden Chatbot-Anfragen pro Tag zu einer ähnlichen Einschätzung für eine zehnprozentige Verbesserung in einem bestimmten Segment von Halluzinationen kommt, bleibt abzuwarten.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.