Forscher kombinieren zwei Sprachmodelle und eine Datenbank für präzisere LLMs

Das "Speculative RAG" Framework kombiniert zwei Sprachmodelle, um Retrieval Augmented Generation (RAG) Systeme effizienter und akkurater zu machen.
Standard-RAG-Systeme ergänzen Large Language Models (LLMs) mit externen Wissensdatenbanken. Das kann faktische Fehler und "Halluzinationen" der Modelle reduzieren.
RAGs sind jedoch kein Allheilmittel, da auch sie fehleranfällig sein können, insbesondere bei großen Datenmengen und komplexen Zusammenhängen. Es gibt daher verschiedene Ansätze, RAG-Systeme zu erweitern, etwa durch eine kontextbasierte Suche mit Ranking (Knowledge Graph), die Ergebnisse aus der Datenbank für das LLM vorfiltert.
Ein neuer Ansatz ist Speculative RAG, der darauf abzielt, RAG-Systeme zu verbessern, indem die Stärken eines kleineren spezialisierten Sprachmodells und eines größeren allgemeinen Sprachmodells kombiniert werden.
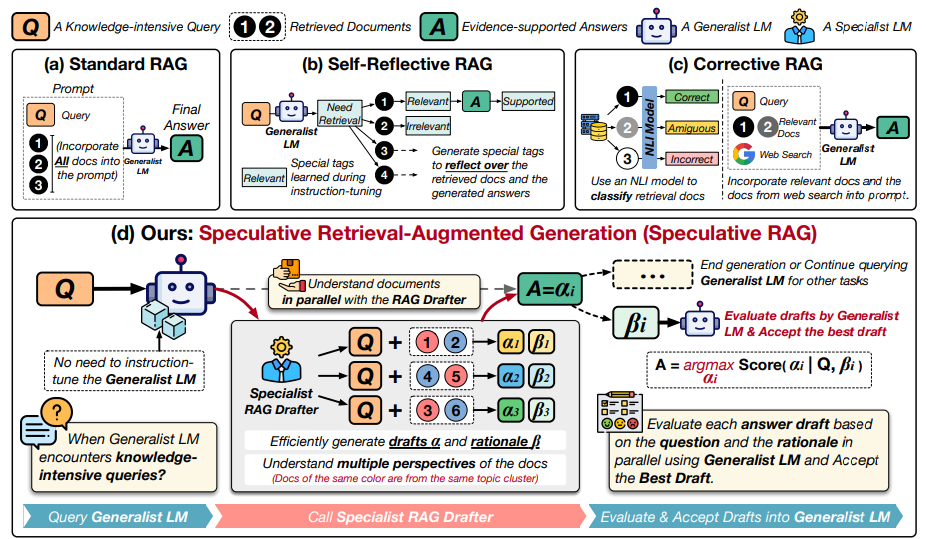
Das Speculative RAG Framework teilt die Aufgabe in zwei Schritte auf: Zuerst generiert ein kleineres, spezialisiertes "RAG Drafter"-Modell mehrere Antwortvorschläge parallel, basierend auf verschiedenen Teilmengen der abgerufenen Dokumente. Das Drafter-Modell wird durch Instruction Tuning auf Tripeln aus (Frage, Antwort, Dokument) trainiert. Dabei wird auch eine Begründung für die Antwort generiert.
Anschließend überprüft ein größeres allgemeines "RAG Verifier"-Modell die Vorschläge und wählt die beste Antwort aus.
Durch die parallele Generierung aus verschiedenen Untermengen von Dokumenten erzeugt das spezialisierte Modell laut der Forscher qualitativ hochwertige Antwortmöglichkeiten mit einer reduzierten Anzahl von Input-Tokens. Das generische Modell kann dann die Vorschläge effizient verifizieren, ohne lange Kontexte verarbeiten zu müssen.
Das Speculative RAG Framework erreichte in Tests mit mehreren Referenzdatensätzen eine um bis zu 12,97 Prozent höhere Genauigkeit bei 51 Prozent geringerer Latenz im Vergleich zu herkömmlichen RAG-Systemen.
Die Forscherinnen und Forscher der Universität California und von Google sehen in der Aufteilung in spezialisierte und allgemeine Modelle einen vielversprechenden Ansatz, um RAG-Systeme leistungsfähiger zu machen. Das Speculative RAG Framework zeige das Potenzial kollaborativer Architekturen für wissensintensive KI-Aufgaben.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.