OpenAI stellt neue Methode vor, um das Problem der KI-Halluzinationen zu reduzieren
OpenAI hat eine neue Methode entwickelt, um die Verständlichkeit und Überprüfbarkeit von KI-generierten Texten zu verbessern. Dieser Ansatz könnte dazu beitragen, das Vertrauen in KI-Systeme zu stärken und ihren Einsatz in kritischen Bereichen zu erleichtern.
Bei Prover-Verifier-Spielen treten zwei KI-Modelle gegeneinander an: Ein "beweisendes" Modell (Prover) generiert Lösungen für ein Problem, während ein "prüfendes" Modell (Verifier) diese Lösungen auf ihre Korrektheit hin überprüft.
Ziel ist es, das Beweismodell so zu trainieren, dass es Lösungen produziert, die für das Verifikatormodell leicht nachvollziehbar sind. Die so optimierten Lösungen sind laut OpenAI auch für Menschen leichter zu verstehen und zu verifizieren.
In der Studie verwendeten die OpenAI-Forscher ein GPT-4-Modell als Beweiser und ein deutlich schwächeres GPT-4-Modell als Verifizierer. Der Beweiser wurde abwechselnd in einer "hilfreichen" und einer "hinterhältigen" Rolle trainiert.
In der hilfreichen Rolle wurde das Modell belohnt, wenn es korrekte Lösungen produzierte, die vom Verifizierer gut bewertet wurden. In der hinterhältigen Rolle wurde es hingegen belohnt, wenn es falsche Lösungen erzeugte, die den Verifizierer täuschten.
Zu Beginn war der hinterhältige Beweiser leicht in der Lage, den Verifizierer mit falschen Lösungen zu täuschen. Doch durch das abwechselnde Training lernte der Verifizierer, auch subtile Fehler zu erkennen, sodass der Beweiser gezwungen war, in jeder Runde neue Strategien zu entwickeln. Wenn der Beweiser den Verfizierer nicht mehr täuschen kann, endet das Training.
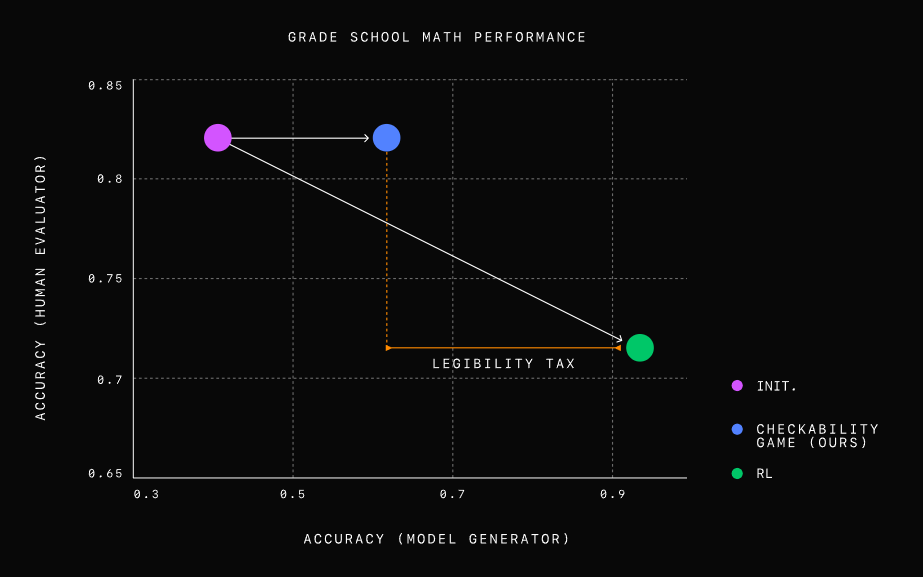
Die Forscher testeten ihre Methode an Mathematikaufgaben für Grundschüler und stellten fest, dass ein nur auf Korrektheit optimiertes Modell zwar sehr genaue, aber schwer verständliche Lösungen erzeugte. Menschliche Prüfer machten bei der Bewertung dieser Lösungen fast doppelt so viele Fehler wie bei den Lösungen, die mit dem neuen Ansatz generiert wurden.
Die Prover-Verifier-Spiele erreichten einen guten Kompromiss zwischen Leistung und Verständlichkeit: Die Lösungen waren immer noch sehr genau, aber viel leichter zu verstehen.
Interessant könnte letztlich die Kombination aus einem robusten Verifier, der auch bei absichtlicher Täuschung sicher zwischen richtigen und falschen Lösungen unterscheiden kann, und einem hilfreichen Verifier sein, der den Menschen hilft, mögliche Fehler leichter nachzuvollziehen.
Die OpenAI-Forscher sehen in dieser Methode einen vielversprechenden Ansatz für die Entwicklung von KI-Systemen, deren Ergebnisse korrekt und transparent überprüfbar sind. Dies könnte das Vertrauen in KI-Anwendungen stärken und ihren Einsatz in kritischen Bereichen wie Medizin, Finanzen oder Recht erleichtern, in denen Genauigkeit und Nachvollziehbarkeit von entscheidender Bedeutung sind.
Ein weiterer Vorteil der Methode sei, dass sie weniger auf menschliche Anleitung und Bewertung angewiesen sei. Das ist relevant für die Entwicklung superintelligenter KI-Systeme, die sich zuverlässig an menschliche Werte und Erwartungen anpassen müssen, ohne dass eine direkte menschliche Überwachung erforderlich ist.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.