SpreadsheetLLM: Wie Microsoft große Excel-Tabellen für KI verdaubar macht

Microsoft-Forscher haben mit SpreadsheetLLM eine Methode entwickelt, um Sprachmodelle für die Analyse von Tabellenkalkulationen zu optimieren.
Die Forscher erklären, dass herkömmliche Tabellenkalkulationen oft zu groß und komplex für KI-Modelle sind. SpreadsheetLLM löst dieses Problem, indem es die Daten in ein kompakteres Format umwandelt und so Sprachmodelle für viele wissenschaftliche und finanzielle Anwendungsfälle nutzbar machen könnte.
"Unser Ansatz reduziert die Datenmenge um bis zu 96 Prozent, ohne dass wichtige Informationen verloren gehen", heißt es in dem Artikel. Dadurch können KI-Systeme auch sehr große Tabellenkalkulationen analysieren, was bisher nicht möglich war.
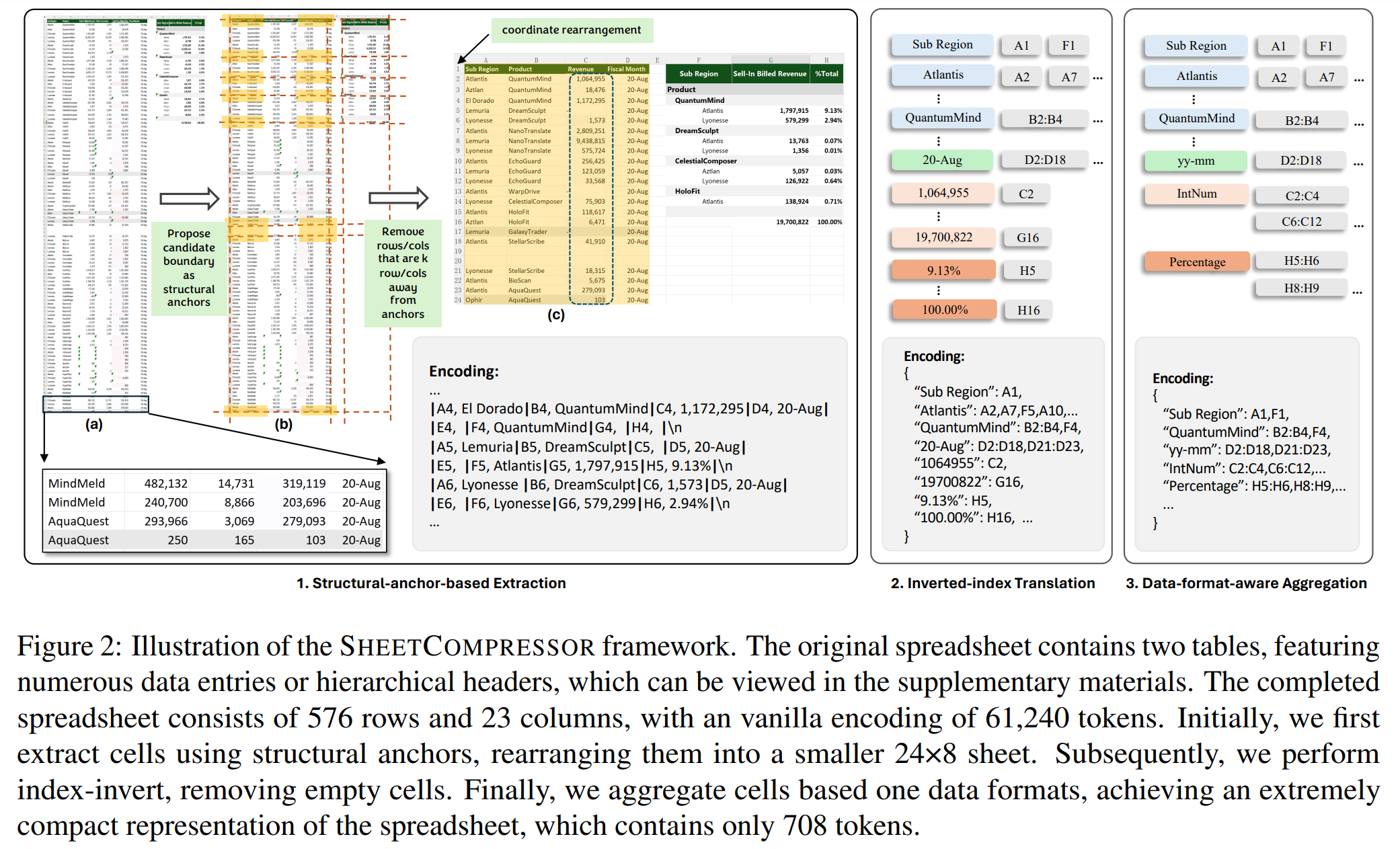
Die neue Methode basiert auf drei Haupttechniken:
- Strukturelle Anker: Das System identifiziert wichtige Bereiche in der Tabellenkalkulation, die die Gesamtstruktur repräsentieren. Weniger wichtige Daten werden entfernt.
- Invertierte Indizierung: Statt jede Zelle einzeln zu speichern, werden gleiche Werte zusammengefasst und mit ihrer Position verknüpft. Das spart Speicherplatz.
- Datenformat-Aggregation: Ähnliche Zahlenformate werden gruppiert, anstatt jeden Wert einzeln zu speichern.
Mit diesen Techniken erfasst das System die wesentlichen Informationen einer Tabellenkalkulation, ohne jede einzelne Zelle speichern zu müssen.
SpreadsheetLLM verbessert Genauigkeit um bis zu 75 Prozent
Die Forscher testeten ihre Methode mit verschiedenen KI-Modellen, darunter GPT-4 von OpenAI und Open-Source-Modelle wie Llama 2. Bei der Aufgabe, Tabellen in Tabellenkalkulationen zu erkennen, erreichte das System eine Genauigkeit von 79 Prozent - eine Verbesserung um 13 Prozentpunkte gegenüber dem bisherigen Bestwert.
Vor allem bei sehr großen Tabellenkalkulationen zeigte sich der Vorteil der neuen Methode. Bei den größten getesteten Dateien verbesserte sich die Genauigkeit im Vergleich zu herkömmlichen Techniken um 75 Prozentpunkte, da die Token-Limits der Sprachmodelle nicht mehr gesprengt werden.
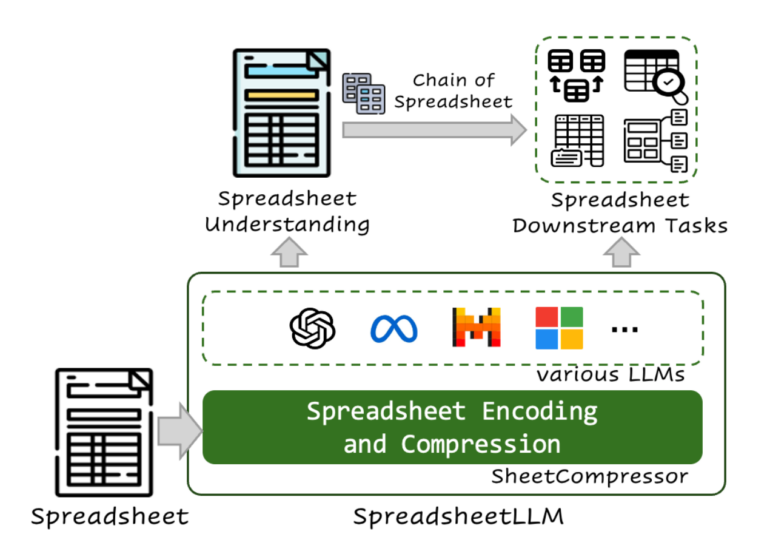
Die Forscher entwickelten auch eine Technik namens "Chain of Spreadsheet" (CoS), um komplexe Anfragen an Tabellenkalkulationen zu beantworten. Dabei wird die Aufgabe in zwei Schritte unterteilt: Zuerst identifiziert das System den relevanten Tabellenbereich, dann generiert es die Antwort. Mit dieser Methode erreichte das System bei Frage-Antwort-Aufgaben zu Tabellenkalkulationen eine Genauigkeit von 74 Prozent.
Die Wissenschaftler räumen ein, dass ihre Methode noch Grenzen hat. So werden derzeit keine Formatierungsdetails wie Hintergrundfarben berücksichtigt, die zusätzliche Informationen liefern könnten. Auch bei der semantischen Verdichtung von Textzellen sehen die Forscher noch Verbesserungspotenzial.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.