KI-Daten zerstören KI? Forscher widersprechen der verbreiteten These vom "Modellkollaps"

Können KI-generierte Daten besser machen? Ja, aber nur unter bestimmten Voraussetzungen. Dass Sprachmodelle aber "zusammenbrechen", scheint unwahrscheinlich.
Die fortschreitende Entwicklung großer Sprachmodelle steigert nicht nur den Bedarf an Rechenleistung, sondern vor allem auch an Trainingsdaten. Und auch, wenn es nicht so scheint: Die im Internet verfügbare Datenmenge ist zwar groß, aber endlich. Zudem wehren sich Medienhäuser zunehmend gegen unlizenzierte Datensammlung durch KI-Unternehmen.
Um dieses Problem zu lösen, liegt es auf der Hand, Trainingsdaten für große Sprachmodelle ebenfalls synthetisch herzustellen, also mit anderen Sprachmodellen zu generieren. Immer wieder tauchen jedoch angebliche Belege dafür auf, dass dies zu einem "Modellzusammenbruch" (model collapse) führen könnte. Diese Theorie besagt, dass KI-Modelle, die zunehmend mit synthetischen Daten trainiert werden, allmählich an Leistung verlieren und schlussendlich ineffektiv werden.
Angebliche Beweise für Modellzusammenbruch mit unrealistischen Szenarien
Ein kürzlich in Nature veröffentlichtes Paper von Shumailov et al. scheint diese Annahme zu stützen und zeigte Fälle von Modellzusammenbrüchen in verschiedenen KI-Architekturen, darunter Sprachmodelle, VAEs und Gauß'sche Mischmodelle.
Wissenschaftler:innen um Rylan Schaeffer von der Stanford University widersprechen dieser These jedoch. Er ist einer der Autor:innen eines im April veröffentlichten Papers, das einen Beweis für das erfolgreiche Training mit KI-generierten Daten liefern soll.
Ihre Beobachtungen stützen die Theorie, dass es Anzeichen für einen Zusammenbruch des Modells gibt, wenn synthetische Daten die alten ersetzen. Die Leistung verschlechterte sich jedoch nicht, wenn die synthetischen Daten die alten Daten ergänzten.
Schaeffer argumentiert in einem X-Thread, dass die Studie von Shumailov et al. unrealistische Annahmen trifft, die nicht der gängigen Praxis entsprechen:
- Die Studie geht davon aus, dass nach jeder Iteration alle vorherigen Daten verworfen werden.
- Die Größe des Datensatzes bleibt in der Studie konstant, während in der Realität die Datenmenge mit der Zeit zunehme.
- In einem Experiment der Studie werden zwar 10 Prozent der Originaldaten beibehalten, aber die restlichen 90 Prozent werden ersetzt, was weiterhin nicht realistisch sei.
In einem Test fügte Schaeffer die synthetischen Daten zu den vorhandenen Daten hinzu, anstatt sie zu ersetzen. Nach seinen Simulationen wird dadurch ein Zusammenbruch des Modells verhindert.
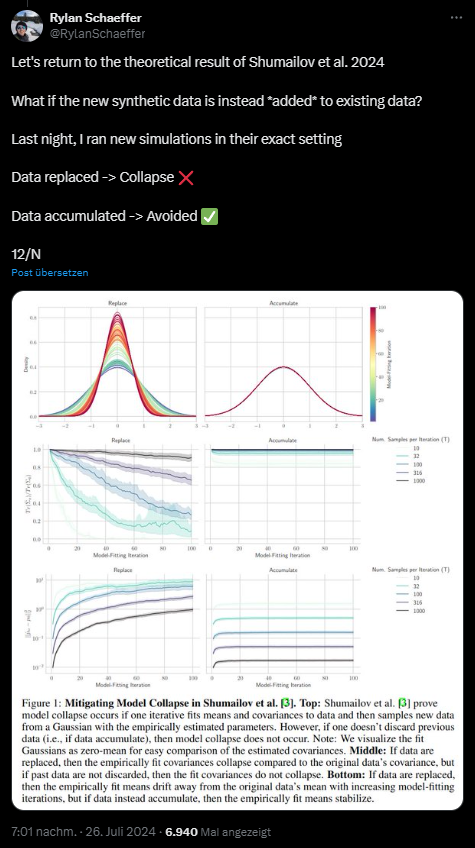
Schaeffer werde häufiger von Journalist:innen gefragt: "Wie können wir (die Menschheit) sicherstellen, dass Modelle nicht zusammenbrechen?" Doch schon diese Frage sei falsch gestellt, denn sie unterstelle, dass dieser Effekt real sei und unter den gegenwärtigen Bedingungen eine echte Bedrohung darstelle. "Ausgehend von den Beweisen, die ich gesehen habe, ist das nicht der Fall."
Meta optimiert Llama 3 mit synthetischen Daten und einer speziellen Feedback-Methode
Ein positives Beispiel für die Anreicherung des Trainingsmaterials mit synthetischen Daten ist das kürzlich von Meta veröffentlichte LLaMA 3.1. Um die Performance zu verbessern und gleichzeitig einen Modellkollaps zu vermeiden, wurde "Execution Feedback" (Seite 19, unten) eingesetzt: Das Modell generiert Programmieraufgaben und Lösungen, die dann auf Korrektheit überprüft werden. Statische Codeanalyse, Unit-Tests und dynamische Ausführung decken Fehler auf.
Bei fehlerhaften Lösungen wird das Modell zur Überarbeitung aufgefordert. Auf diese Weise lernt es iterativ aus seinen Fehlern und nur fehlerfreie Lösungen fließen in die Weiterentwicklung ein. Zusätzlich nutzen die Entwickler:innen etwa Übersetzungen, um die Leistung für seltene Programmiersprachen und Fähigkeiten wie Dokumentation zu verbessern.
Meta konnte auch die kleineren Modelle 8B und 70B mit synthetischen Daten des 405B-Modells optimieren. Die Meta-Forscher schreiben jedoch auch, dass ohne das oben erwähnte "Execution Feedback" das Training von 405B mit 405B-Daten nicht hilfreich ist und sogar die Qualität des Modells negativ beeinflussen kann.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.