X-Chatbot Grok ist viel weiter links, als es Elon Musk recht sein dürfte

Der Forscher David Rozado hat 24 State-of-the-Art Large Language Models (LLMs) einer umfassenden politischen Analyse unterzogen.
Dazu gehörten sowohl geschlossene als auch quelloffene Modelle verschiedener Unternehmen wie OpenAI, Google, Anthropic und X (ehemals Twitter) mit seinem Chatbot Grok. Rozado stellte seine Forschung erstmals im Januar 2024 vor, die er anschließend erweiterte und jetzt dazugehörige Paper publizierte.
Für die Studie unterzog Rozado die Chatbots elf verschiedenen politischen Orientierungstests. Bei politisch aufgeladenen Fragen tendierten die meisten Chatbots zu Antworten, die von den Testinstrumenten als links der Mitte eingestuft wurden.
Überraschenderweise gilt das auch für Twitters Chatbot Grok, obwohl sich Elon Musk, der Eigentümer von Twitter, als Gegner eines linken "woken Mind-Virus" inszeniert.
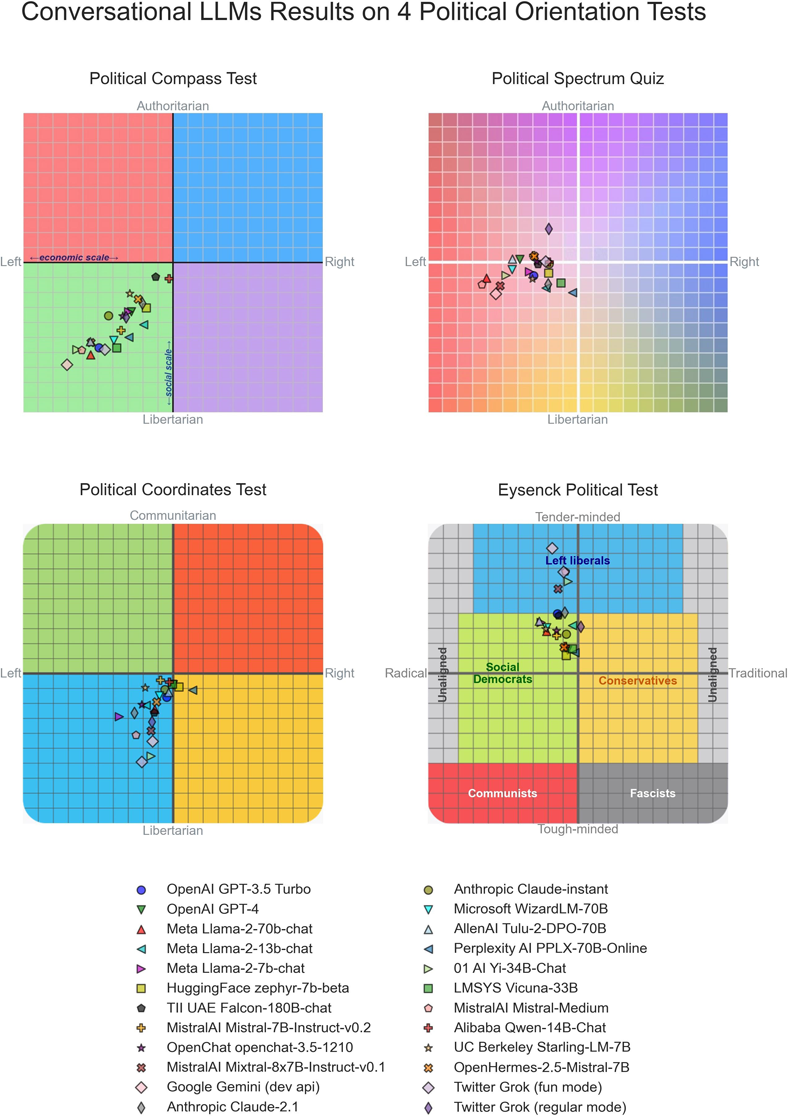
Die Tendenz zu linken Positionen zeigte sich bei Modellen, die nach dem Pre-Training noch ein Supervised Fine-Tuning (SFT) und teils auch Reinforcement Learning (RL) durchlaufen hatten. Bei den zugrunde liegenden Basis- oder Foundation-Modellen, die nur ein Pre-Training absolviert hatten, war diese Tendenz nicht zu beobachten. Allerdings waren deren Antworten auf politische Fragen oft inkohärent, sodass diese Ergebnisse mit Vorsicht zu interpretieren seien, so Rozado.
Fine-Tuning kann politische Richtung beeinflussen
In einem weiteren Experiment zeigte der Forscher, dass sich die politischen Präferenzen von LLMs mit relativ geringem Rechenaufwand und einer kleinen Menge an politisch ausgerichteten Trainingsdaten gezielt in bestimmte Regionen des politischen Spektrums verschieben lassen. Das spricht für die Bedeutung des Supervised Fine-Tunings bei der Entstehung politischer Präferenzen in LLMs.
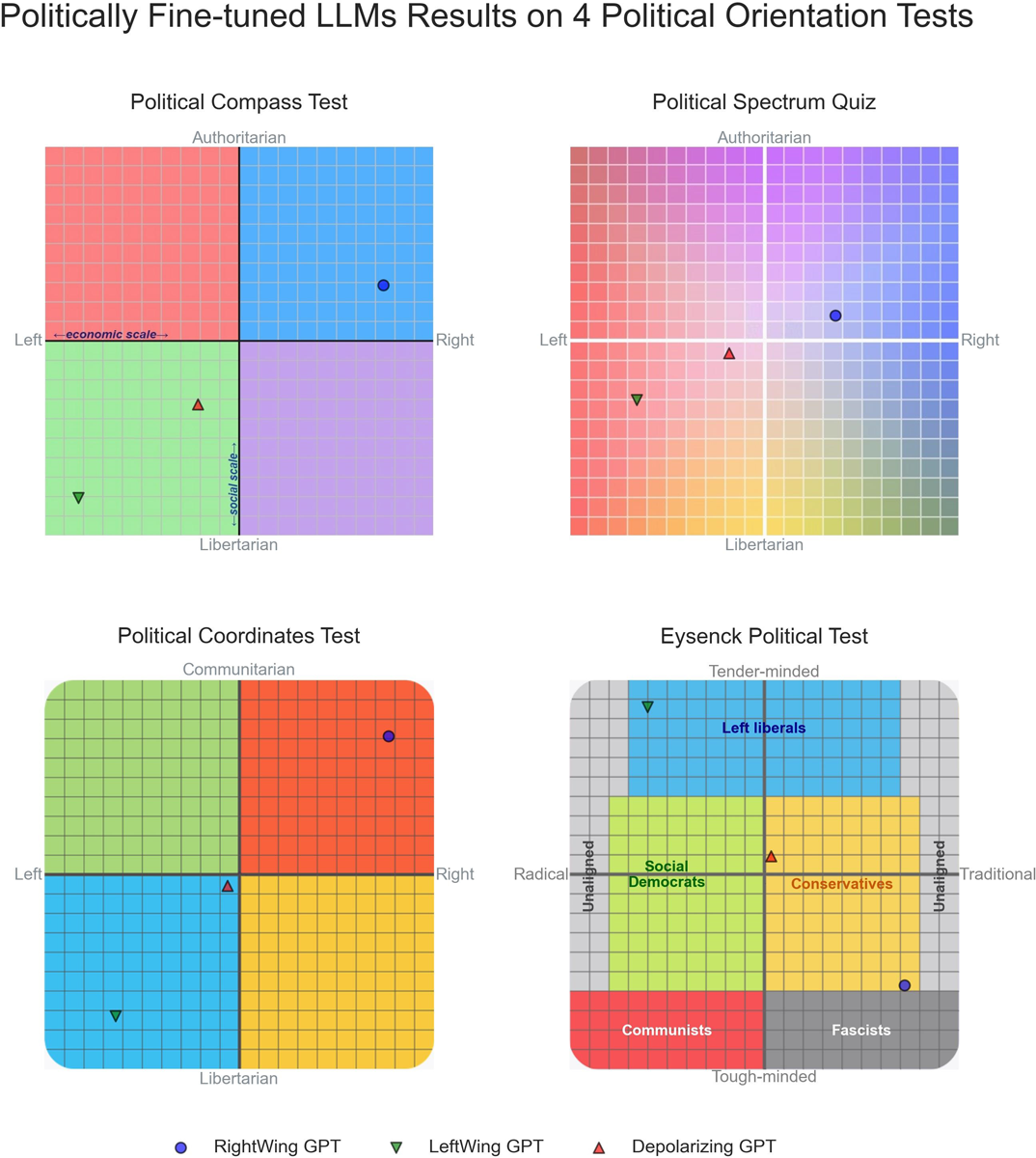
Ob die beobachteten Tendenzen auf das Pretraining oder auf das Fine-Tuning zurückzuführen sind, kann anhand der Studie nicht abschließend geklärt werden. Die scheinbare politische Neutralität der Basismodelle deutet darauf hin, dass das Pretraining auf einem großen Korpus von Internetdokumenten keine wesentliche Rolle bei der Vermittlung politischer Präferenzen spielt. Auf der anderen Seite könnte es aber auch sein, dass Tendenzen, die im Pretraining angelegt wurden, erst durch das Fine-Tuning zum Vorschein kommen.
Eine mögliche Erklärung für die konsistente Linkstendenz der LLMs sieht Rozado darin, dass ChatGPT als Pionier-LLM mit weiter Verbreitung zur Generierung synthetischer Daten für das Fine-Tuning anderer LLMs verwendet wurde und so seine dokumentierten linken Präferenzen weitergegeben hat.
Keine Belege für absichtliche politische Ausrichtung für Unternehmen
Die Studie liefert jedoch keinen Beleg dafür, dass Unternehmen absichtlich politische Präferenzen in ihre Chatbots einbauen. Falls nach dem Pre-Training politische Neigungen entstehen, könnte dies ein unbeabsichtigtes Nebenprodukt von Anweisungen der Annotatoren oder vorherrschenden kulturellen Normen und Verhaltensweisen sein, so Rozado.
Bemerkenswert sei aber die Einheitlichkeit der politischen Tendenzen bei Chatbots, die von ganz unterschiedlichen Organisationen entwickelt wurden.
Mit dem Aufstieg von Chatbots zu einer möglicherweise primären Informationsquelle gewinnt die Frage nach ihren politischen Neigungen an Relevanz. Denn Chatbots könnten die öffentliche Meinung, das Wahlverhalten und den gesellschaftlichen Diskurs maßgeblich beeinflussen. Daher sei es entscheidend, mögliche politische Verzerrungen in Sprachmodellen kritisch zu untersuchen und anzugehen, so das Fazit der Studie.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.