Fehler, Einbildung, Gewohnheit? Nach ChatGPT soll auch Claude "dümmer" geworden sein

Sprachmodelle werden gefühlt schlechter, Nutzer:innen beschweren sich öffentlich, Hersteller widersprechen den Behauptungen - dieses Muster wiederholt sich. Und das wird sich wohl auch nicht ändern, wenn die Technologie so bleibt, wie sie ist.
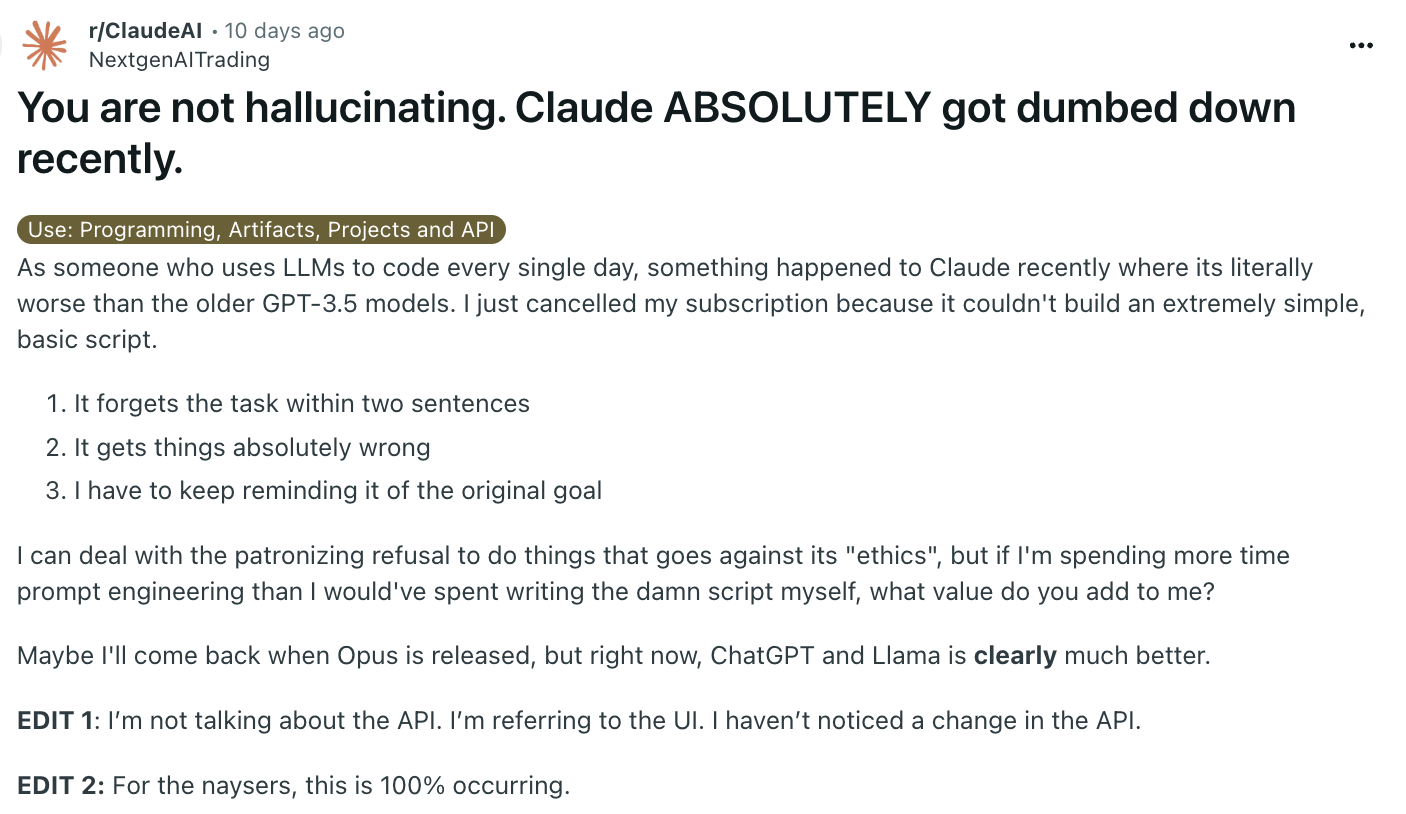
Berichten von Nutzer:innen zufolge ist Anthropics Chatbot Claude "in letzter Zeit absolut verdummt". Das behauptet zumindest ein Reddit-Poster, der sein Erlebnis in einem Beitrag recht emotional beschreibt.
Dafür erhielt er viel Zustimmung aus der Community, die offenbar ähnliche Erfahrungen machen musste. War die Ausgabe des Chatbots zuvor mehr als zufriedenstellend, haben die jüngsten Entwicklungen den Original-Poster sogar dazu gebracht, sein Abonnement zu kündigen.
Irgendetwas geht in der Web-UI vor sich, und ich habe es satt, dass man mich immer wieder gaslightet und mir sagt, dass es nicht so ist. Jemand von Anthropic muss das untersuchen, weil zu viele Leute in den Kommentaren mit mir übereinstimmen.
u/NextgenAITrading auf Reddit
Konkret beschwert er sich darüber, dass Claude sein eigentliches Ziel innerhalb von zwei Sätzen vergesse und selbst simple Coding-Aufgaben nicht bewältigen könne.
Mittlerweile ist die Feedbackwelle bei Anthropic angekommen. Alex Albert, verantwortlich für die Beziehungen zu Entwickler:innen, antwortet mit einem weiteren Reddit-Beitrag. Darin widerspricht er der These, dass sie Änderungen an den Modellen vorgenommen haben.
Wir haben auch gehört, dass einige Nutzer die Antworten von Claude weniger hilfreich finden als sonst. Unsere erste Untersuchung hat keine weit verbreiteten Probleme ergeben. Wir möchten außerdem bestätigen, dass wir keine Änderungen am 3.5-Sonnet-Modell oder an der Inferenzpipeline vorgenommen haben.
Alex Albert, Developer Relations bei Anthropic
Anthropic dokumentiert jetzt Systemprompt
Gründe für die "gefühlte Verdummung" könnten unter anderem in Änderungen am Systemprompt liegen. Diese Nachricht wird jeder Nutzer:innenanfrage bei Zugriff per Chatbot über die Website (und nicht per API) vorangestellt.
Anthropic hat in seinem Bestreben für mehr Transparenz auf seiner Website nun einen Bereich eingerichtet, in dem sie die (seit dem 12. Juli 2024) aktuellen Systemprompts für Claude 3.5 Sonnet, Claude 3 Opus und Claude 3 Haiku veröffentlichen. Zumindest seit diesem Zeitpunkt kann der Systemprompt also nicht für eine Leistungsabnahme verantwortlich gemacht werden.
Bereits zahlreiche Beschwerden über Claude im April
Tatsächlich ist das nicht das erste Mal, dass Stimmen über die angeblich abnehmende Leistung von Claude laut werden. Bereits im April 2024 sammelte ein Reddit-Nutzer zahlreiche Beschwerden, in denen Nutzer:innen unzufriedenstellende Momente beschreiben.
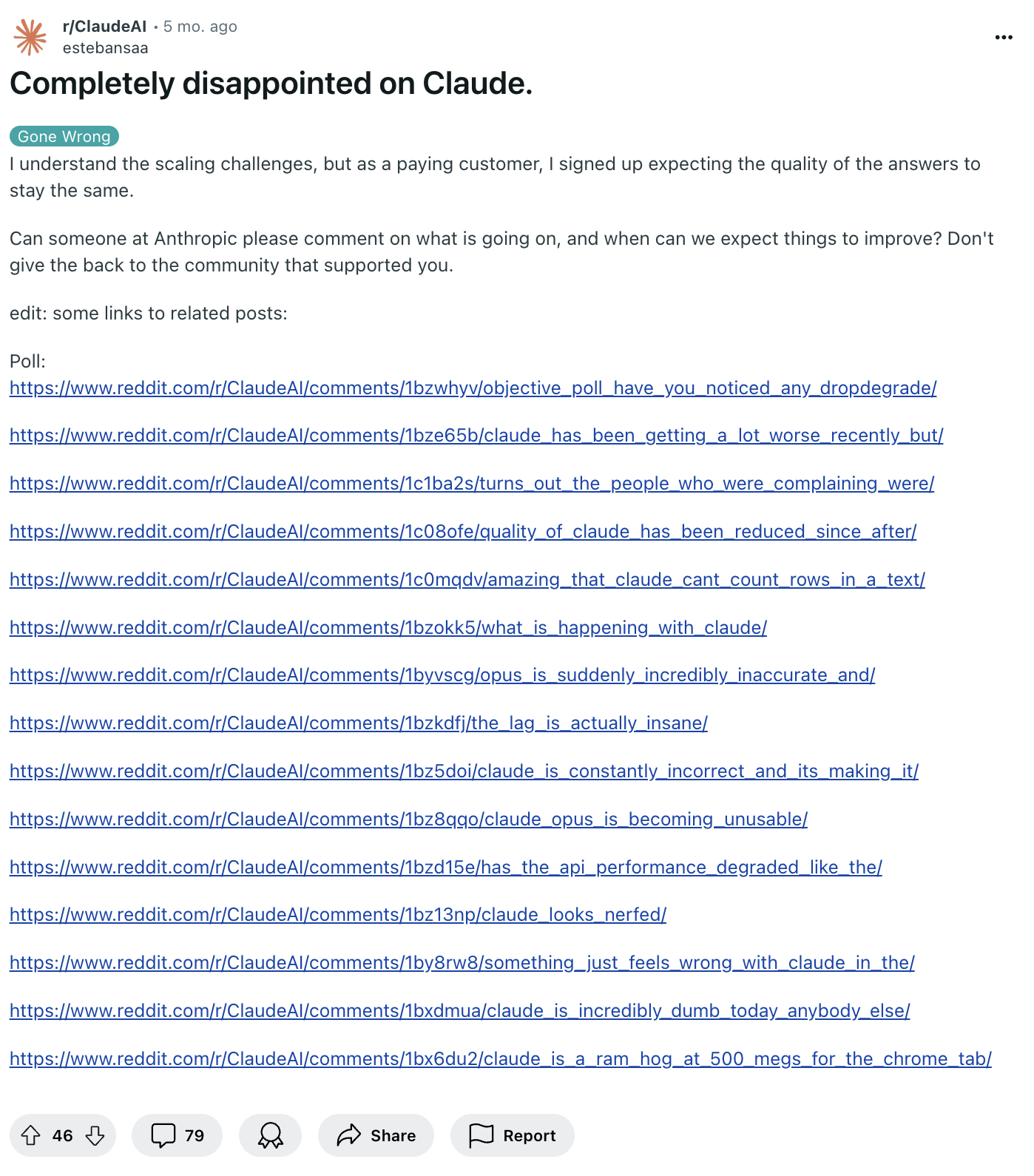
Auch damals reagierte Anthropic, jedoch ähnlich vorsichtig: Modelländerungen habe es keine gegeben und die identische Software laufe gleichzeitig auf Tausenden Servern, um die verschiedenen Instanzen von Claude anzubieten. Wer "fehlerhafte Antworten" erhalte, solle diese per Daumen-Voting als schlecht bewerten.
Inzwischen berichten manche Nutzer:innen, dass sich die Leistung wieder auf dem alten Niveau eingependelt habe. Mögliche Erklärung für die negativen Erlebnisse könnte auch technischer Natur gewesen sein. Anfang August verzeichnete Google Cloud im Zusammenhang mit Claude 3.5 Sonnet und Claude 3 Opus Ausfälle bei seiner KI-Plattform Vertex AI.
Geschichte wiederholt sich
Claude ist nicht der einzige Chatbot, dem vorgeworfen wurde, immer schlechtere Ergebnisse zu liefern. Ein ähnliches Schicksal ereilte auch ChatGPT in der zweiten Jahreshälfte 2023, damals hauptsächlich von GPT-4 und GPT-4 Turbo angetrieben. Auch heute noch tauchen solche Beschwerden immer wieder mal auf, etwa für GPT-4o.
Insgesamt ist es ein wiederkehrendes Muster, dass Nutzer:innen einige Zeit nach der Veröffentlichung eines Modells über Performanceeinbußen klagen und die Hersteller kurz darauf die Berichte dementieren. Es ist davon auszugehen, dass sich dies auch in Zukunft und bei anderen Modellen wiederholen wird.
Ein möglicher Grund dafür könnte auch sein, dass sich die Menschen an die Fähigkeiten des Sprachmodells gewöhnen, die Erwartungen jedoch größer werden als das Modell zum jeweiligen Zeitpunkt liefern kann.
Als ChatGPT im November 2022 auf Basis von GPT-3.5 an den Start ging, beeindruckte das viele in den ersten Momenten. Mittlerweile sieht GPT-3.5 verglichen mit GPT-40 und anderen Modellen auf dem Niveau wortwörtlich alt aus.
Weitere mögliche Gründe sind schlicht die der Technologie zugrunde liegende Variabilität in der Generierung, eventuell temporäre Engpässe in der Rechenleistung oder schlicht fehlerhafte Verarbeitung.
Auch wir machen in unserer täglichen Arbeit immer wieder die Erfahrung, dass ein Prompt, der zuverlässig funktioniert, in einem von zehn Fällen ein Ergebnis liefert, das weit unter dem normalen Leistungsniveau liegt. Eine erneute Generierung reicht dann meist aus, um die gewohnte Qualität zu erreichen.
OpenAI kommentierte die Faulheitsvorwürfe gegen GPT-4 seinerzeit damit, dass das Verhalten von KI-Modellen unvorhersehbar sein könne. Das Training der KI, die Abstimmung der Modelle und die Evaluierung seien "handwerkliche Teamarbeit" und kein "sauberer industrieller Prozess". Zudem könne ein Modellupdate die Leistung in einigen Bereichen verbessern, in anderen aber verschlechtern.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.