Meta stellt KI-Modell für personalisierte Bildgenerierung vor

Das neue KI-Modell "Imagine yourself" von Meta kann aus einem einzigen Referenzbild vielfältige personalisierte Bilder erzeugen - ohne zusätzliches Training.
Meta hat ein neues KI-Modell für personalisierte Bildgenerierung namens "Imagine yourself" vorgestellt. Das Modell kann aus einem einzigen Referenzbild einer Person vielfältige neue Bilder dieser Person in unterschiedlichen Posen, Stilen und Umgebungen erzeugen.
Im Gegensatz zu früheren Ansätzen, die für jede Person neu trainiert werden mussten, funktioniert "Imagine yourself" ohne personenspezifisches Training. Das Modell verarbeitet das Referenzbild und die Textanweisung parallel und kann so flexibel auf neue Personen und Anweisungen reagieren.

Meta setzt auf synthetische Trainingsdaten
Um diese Verbesserungen zu erreichen, setzt Meta auf mehrere neue Techniken: Erstens nutzt "Imagine yourself" synthetische Trainingspaare. Dabei werden zu echten Referenzbildern passende synthetische Varianten erzeugt. So lernt das Modell, Personen in verschiedenen Posen und Stilen darzustellen, ohne sich zu sehr am Referenzbild zu orientieren.
Zweitens verwendet das Modell eine neue Architektur mit drei parallelen Textverarbeitungsmodulen und einem trainierbaren Bildverarbeitungsmodul. Diese verarbeiten Bild und Text gleichzeitig und ermöglichen so eine bessere Abstimmung zwischen beiden. Außerdem nutzt Meta ein mehrstufiges Feintuning. Dabei wird das Modell abwechselnd mit echten und synthetischen Daten trainiert, um Identitätserhaltung und Anweisungsbefolgung zu optimieren.
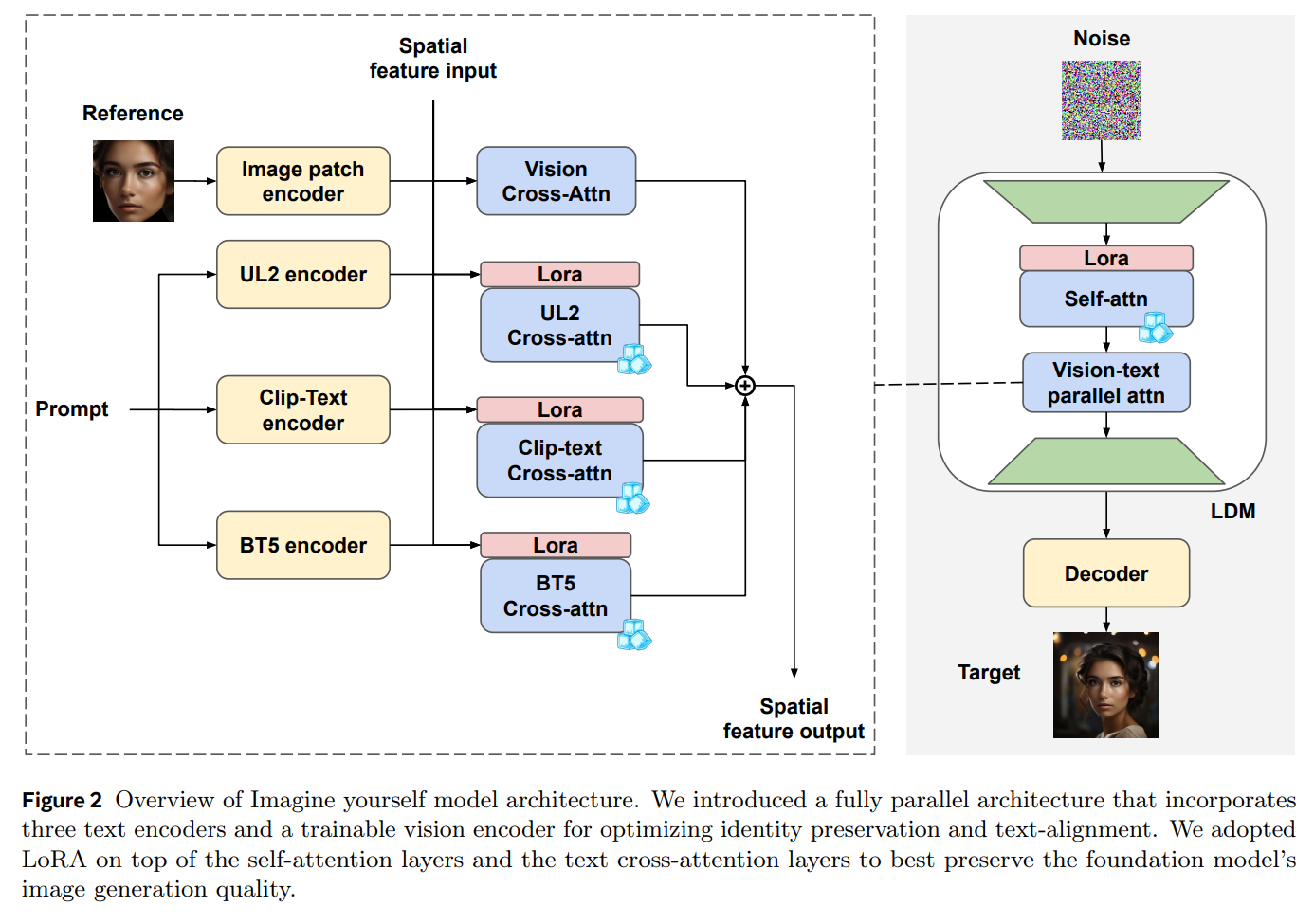
Im Vergleich zu bestehenden Ansätzen wie InstantID oder IP-Adapter kann "Imagine yourself" laut Meta deutlich besser komplexe Anweisungen umsetzen, die starke Änderungen am Referenzbild erfordern. Beispielsweise kann das Modell den Gesichtsausdruck oder die Kopfhaltung einer Person verändern und sie in völlig neue Umgebungen versetzen.
"Imagine yourself" hat noch Schwächen und ist bisher nicht verfügbar
Allerdings zeigt die Studie auch, dass konkurrierende Modelle bei der Identitätserhaltung teilweise noch besser abschneiden. Meta erklärt dies damit, dass diese Modelle oft einfach Teile des Referenzbildes kopieren, was aber zu unnatürlich wirkenden Ergebnissen führen kann.
"Imagine yourself" kann auch für die Generierung von Bildern mit mehreren Personen erweitert werden. Dazu werden die Bildinformationen mehrerer Referenzbilder parallel verarbeitet. So können Gruppenfotos mit bekannten Personen in neuen Posen und Umgebungen erzeugt werden.
Meta plant, die Forschung an "Imagine yourself" fortzusetzen. Zukünftige Schwerpunkte sind die Erweiterung auf Videogenerierung sowie die Verbesserung bei sehr komplexen Posen wie Sprüngen. Bisher sind das Modell oder der Code nicht verfügbar.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.