Infinity-MM: Chinesische KI-Forscher entwickeln leistungsstarkes Open-Source-Bildsprachmodell
Ein Team von Forschenden verschiedener chinesischer Institutionen hat mit Infinity-MM einen der größten öffentlich verfügbaren Datensätze für multimodale KI-Modelle erstellt und darauf ein neues Modell trainiert, das Spitzenleistungen erreicht.
Der Datensatz Infinity-MM setzt sich aus vier Hauptkategorien zusammen: 10 Millionen Bildbeschreibungen, 24,4 Millionen allgemeine visuelle Anweisungsdaten, 6 Millionen ausgewählte hochwertige Anweisungsdaten sowie 3 Millionen von GPT-4 und anderen KI-Modellen generierte Daten.
Bei der Datenerstellung nutzte das Team bestehende Open-Source-KI-Modelle: Das RAM++-Modell analysiert zunächst die Bilder und extrahiert wichtige Informationen. Auf dieser Basis werden dann passende Fragen generiert und die entsprechenden Antworten erstellt. Ein spezielles Klassifizierungssystem mit sechs Hauptkategorien soll dabei die Qualität und Vielfalt der generierten Daten sicherstellen.
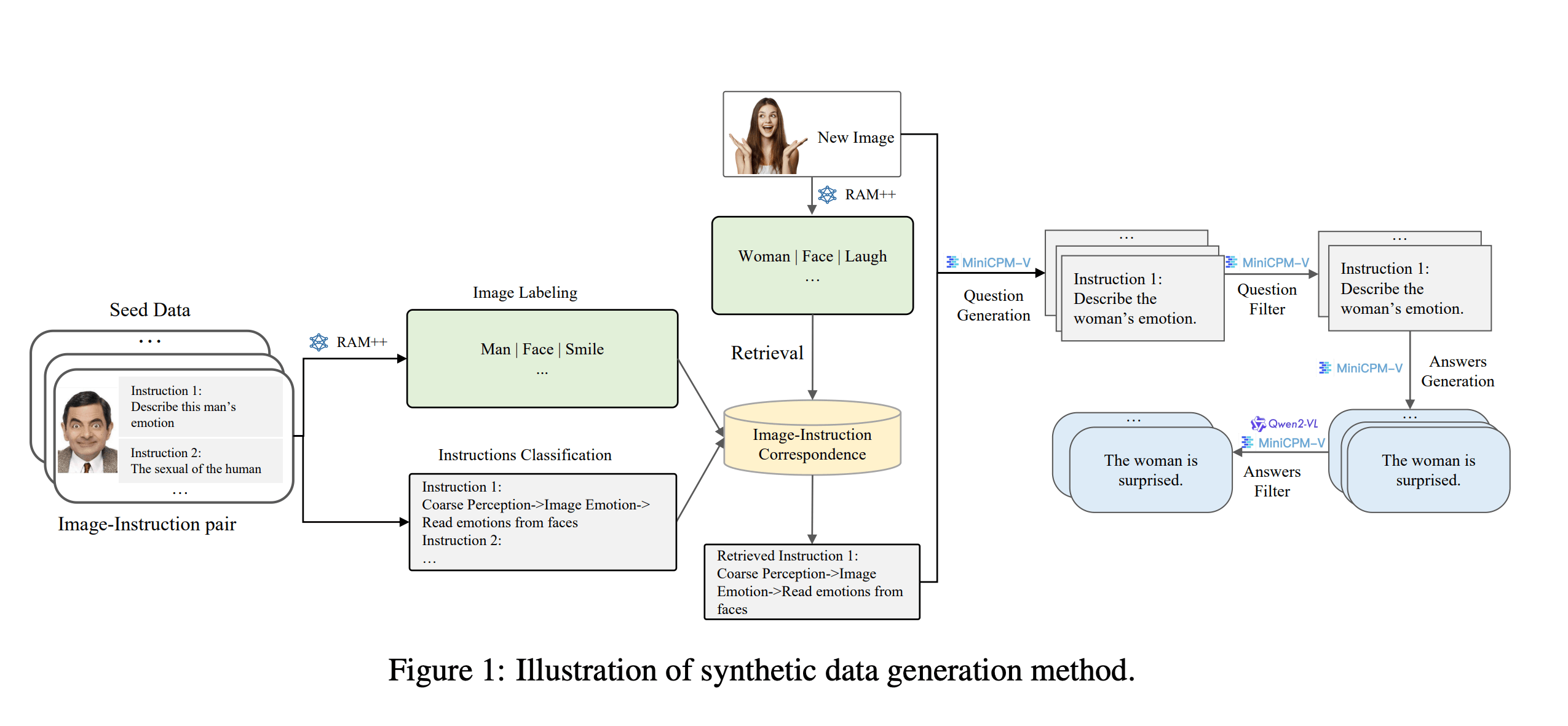
Vierstufiges Training für bessere Leistung
Das darauf trainierte Modell Aquila-VL-2B basiert auf der LLaVA-OneVision-Architektur und nutzt Qwen-2.5 als Sprachmodell sowie SigLIP für die Bildverarbeitung. Das Training erfolgte in vier aufeinander aufbauenden Phasen mit steigender Komplexität.
In der ersten Phase lernte das Modell grundlegende Bild-Text-Zuordnungen. In den weiteren Phasen folgten allgemeine visuelle Aufgaben, spezifische Anweisungen und schließlich die Integration der synthetisch generierten Daten. Dabei wurde auch die maximale Bildauflösung schrittweise erhöht.
Neue Maßstäbe bei Benchmark-Tests
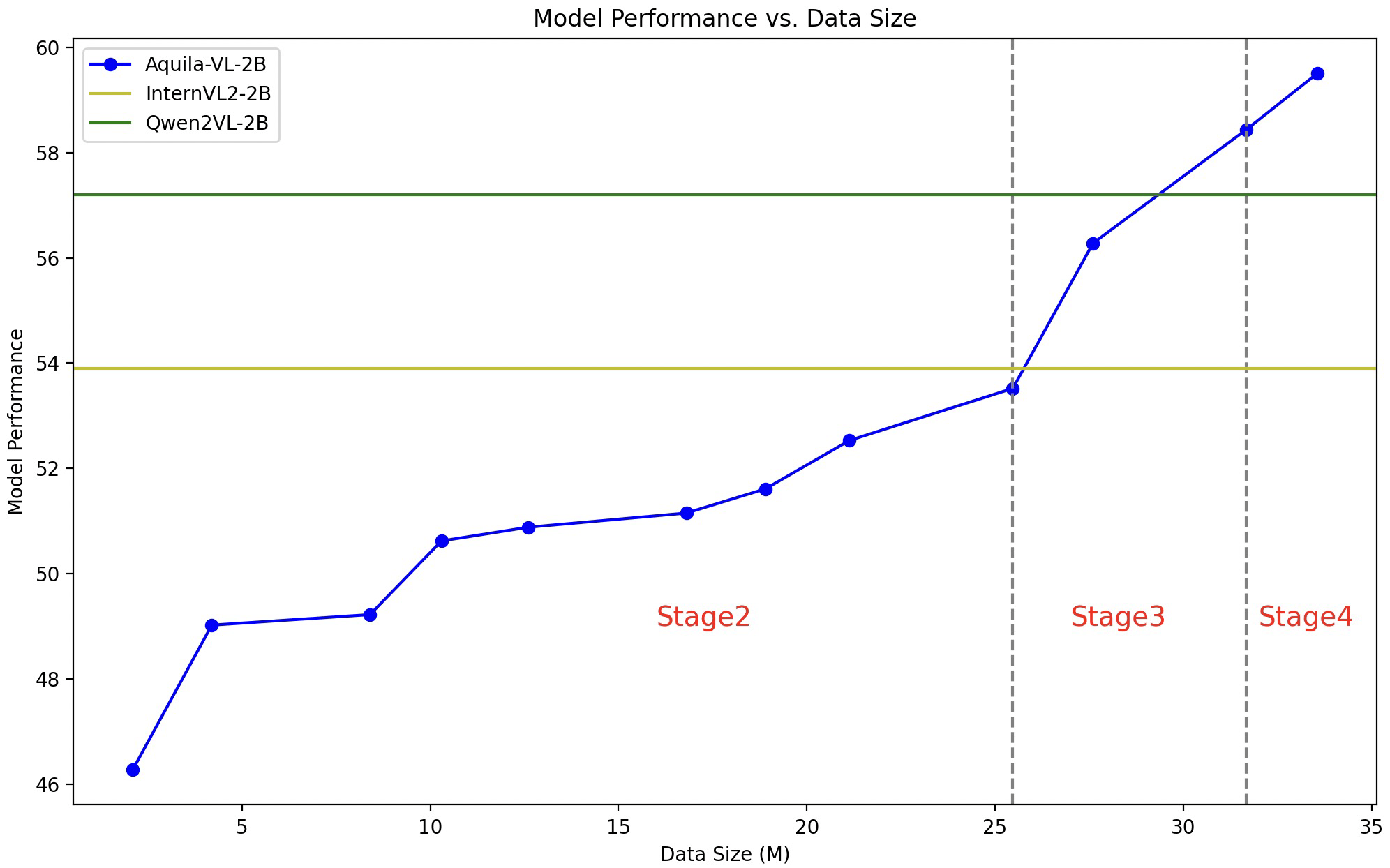
In umfangreichen Tests erreichte Aquila-VL-2B trotz seiner vergleichsweise geringen Größe von nur zwei Milliarden Parametern Spitzenwerte. Beim MMStar-Benchmark für multimodales Verständnis erzielte es 54,9 Prozent - der beste Wert für ein Modell dieser Größenordnung.
Besonders beeindruckend sind die Ergebnisse bei mathematischen Aufgaben: Im MathVista-Test erreichte das Modell 59 Prozent und übertraf damit deutlich vergleichbare Systeme. Auch bei Tests zum allgemeinen Bildverständnis wie HallusionBench (43 Prozent) oder dem MMBench (75,2 Prozent) zeigte das Modell hervorragende Leistungen.
Die Forscher:innen konnten zudem nachweisen, dass die Integration der synthetisch generierten Daten die Leistung deutlich verbessert. Tests ohne diese zusätzlichen Daten führten zu einem Leistungsabfall von durchschnittlich 2,4 Prozentpunkten.
Das Team stellt sowohl den Datensatz als auch das Modell der Forschungsgemeinschaft zur Verfügung. Das Modell wurde auf Nvidia-A100-GPUs sowie chinesischen Chips trainiert.
Vision Language Models im Aufschwung
Die Entwicklung von Aquila-VL-2B fügt sich in einen breiteren Trend der KI-Forschung ein. Während geschlossene kommerzielle Systeme wie GPT-4o bisher oft bessere Leistungen zeigen, holen Open-Source-Modelle auf. Besonders die Nutzung synthetischer Trainingsdaten erweist sich als vielversprechend.
So konnte etwa das Open-Source-Modell Llava-1.5-7B durch das Training mit über 62.000 synthetisch generierten Beispielen bei bestimmten Aufgaben sogar GPT-4V übertreffen. Auch Meta setzt mit Llama-Modellen stark auf synthetische Daten.
Dennoch zeigen aktuelle Tests auch die Grenzen heutiger Vision Language Models auf. Die Bildverarbeitung ist in vielen Bereichen noch unzureichend, besonders beim Filtern spezifischer visueller Informationen aus großen Datenmengen. Auch die begrenzte Auflösung der visuellen Encoder stellt eine technische Beschränkung dar.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.