KI schlägt Neurowissenschaftler bei der Vorhersage von Forschungsergebnissen

Eine Studie des University College London zeigt: Große Sprachmodelle können die Ergebnisse wissenschaftlicher Studien besser vorhersagen als menschliche Experten.
Die in der Fachzeitschrift Nature veröffentlichte Studie ergab, dass KI-Modelle bei der Vorhersage, ob wissenschaftliche Hypothesen durch experimentelle Daten gestützt werden, eine Genauigkeit von 81,4 Prozent erreichten, verglichen mit 63,4 Prozent bei menschlichen Experten.
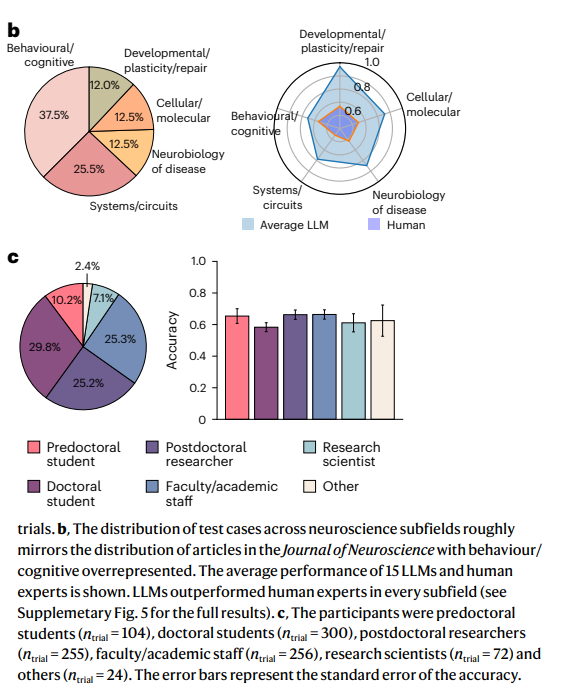
Für die als "BrainBench" bezeichnete Untersuchung rekrutierten die Forscher 171 Neurowissenschaftler, darunter Doktoranden, Postdoktoranden und Professoren mit durchschnittlich 10,1 Jahren Erfahrung.
Jeder Teilnehmer untersuchte neun Forschungsszenarien aus verschiedenen Bereichen der Neurowissenschaften und überprüfte die Methodik und Hypothesen, um vorherzusagen, ob die Experimente die Erwartungen der Forscher erfüllen würden. Die LLMs mussten sich einem umfangreicheren Test unterziehen: 200 von Experten erstellte Fälle plus 100 von GPT-4 erstellte Szenarien.
Selbst die besten 20 Prozent der menschlichen Experten lagen mit einer Trefferquote von 66,2 Prozent deutlich unter der Leistung der KI-Modelle. Dabei wurden nicht einmal die derzeit besten Modelle von OpenAI und Co. verwendet, sondern ältere Open-Source-Modelle, die zum Zeitpunkt der Studie aktueller waren und unter dem Niveau von GPT-4 liegen dürften.
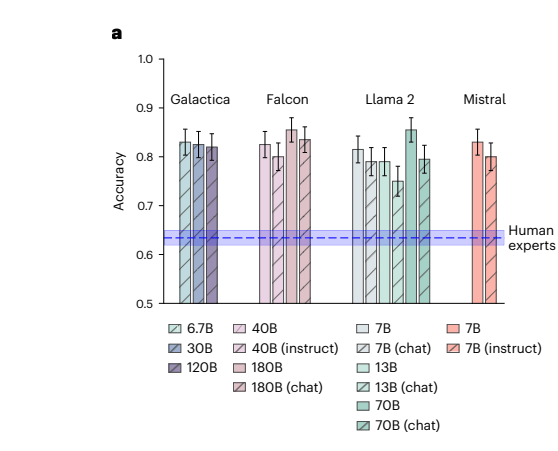
Metas Galactica, eines der getesteten Modelle, wurde speziell für wissenschaftliche Aufgaben entwickelt, stieß jedoch bei seiner Markteinführung im Jahr 2022 auf erhebliche Kritik von Wissenschaftlern.
Mehr als auswendig gelernt
Laut der Studie waren die KI-Modelle den menschlichen Experten in allen getesteten Teilgebieten der Neurowissenschaft überlegen. Besonders erfolgreich waren die Modelle, wenn sie Informationen über den Abstrakt hinaus integrieren konnten - also etwa Methodik und Hintergrund mit den Ergebnissen in Verbindung brachten.
Die Forscher testeten auch, dass die besseren Ergebnisse nicht auf reines Auswendiglernen zurückzuführen sind. Mit einem speziellen Messverfahren überprüften sie, ob die Modelle die Testfälle bereits aus dem Training kannten. Zum Vergleich analysierten sie Daten, die mit hoher Wahrscheinlichkeit zu den Trainingsdaten gehörten.
Die Forscher vermuten, dass KI-Modelle wissenschaftliche Artikel eher als allgemeine Muster abspeichern - ähnlich wie Menschen Schemata bilden - anstatt sie auswendig zu lernen. "Wir fragen uns, ob die Forschenden ausreichend innovativ und explorativ arbeiten", sagt Dr. Ken Luo, Hauptautor der Studie.
Auch kleine KI-Modelle schlagen sich gut
Bemerkenswert ist laut den Forschern, dass auch kleinere Modelle wie Llama2-7B und Mistral-7B mit nur 7 Milliarden Parametern ähnlich gute Ergebnisse erzielten wie deutlich größere Modelle. Allerdings waren für Chats optimierte Versionen weniger erfolgreich bei der Vorhersage als ihre Basis-Varianten. Die Forscher vermuten, dass die Optimierung der Chat-Modelle auf Konversationen ihre Fähigkeit, wissenschaftliche Schlussfolgerungen zu ziehen, einschränkt.
Die Wissenschaftler entwickelten auch eine spezialisierte Version namens "BrainGPT", die auf Mistral 7B basiert. Dieses Modell wurde mit 1,3 Milliarden neurowissenschaftlichen Texten optimiert und konnte die Ergebnisse nochmals um 3 Prozentpunkte verbessern.
Wie die menschlichen Experten zeigten auch die KI-Modelle eine gute Kalibrierung: Wenn sie sich einer Vorhersage besonders sicher waren, lag ihre Trefferquote höher. Das sei wichtig für den praktischen Einsatz solcher Systeme, so die Forscher.
Chancen und Risiken für die Wissenschaft
Die Ergebnisse deuten darauf hin, dass KI-Systeme künftig eine wichtige Rolle bei der Planung und Durchführung von Forschung spielen könnten.
Luo sieht darin potenziellen Fortschritt für die Wissenschaft insgesamt: "Wir sehen eine Zukunft vor uns, in der Forscher ihre geplanten Experimente und erwarteten Ergebnisse eingeben können und die KI Vorhersagen über die Wahrscheinlichkeit verschiedener Outcomes macht. Das würde schnellere Iterationen und besser informierte Entscheidungen beim Experimentdesign ermöglichen."
Allerdings warnen die Forscher auch davor, dass Wissenschaftler möglicherweise zögern könnten, Studien durchzuführen, deren Ergebnisse von der KI anders vorhergesagt wurden - selbst wenn gerade diese unerwarteten Ergebnisse zu wichtigen Durchbrüchen führen könnten. Umgekehrt könnten Ergebnisse, die von der KI mit hoher Sicherheit vorhergesagt wurden, als weniger innovativ wahrgenommen werden.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.