Internationales Forscherteam entwickelt "letzte Prüfung der Menschheit" für KI-Systeme

Ein internationales Forscherteam hat einen neuen KI-Test vorgestellt, der die Grenzen aktueller KI-Systeme aufzeigt. Selbst die fortschrittlichsten Modelle scheitern an 90 Prozent der Aufgaben - noch.
Ein internationales Forscherteam hat mit "Humanity's Last Exam" (HLE) einen neuen Maßstab für die Bewertung von KI-Systemen vorgestellt. Der Test umfasst 3.000 Fragen aus über hundert Fachgebieten und wurde von fast tausend Experten aus 500 Institutionen in 50 Ländern entwickelt. 42 Prozent der Fragen stammen aus dem mathematischen Bereich.
Die ausgewählten Fragen durchliefen einen zweistufigen Filterprozess: Zunächst wurden 70.000 Fragen führenden KI-Modellen vorgelegt. Konnten sie diese nicht lösen, was bei 13.000 Fragen der Fall war, wurden sie von menschlichen Prüfern verfeinert und verifiziert. Für qualitativ hochwertige Fragen erhielten die Experten zwischen 500 und 5.000 Dollar.
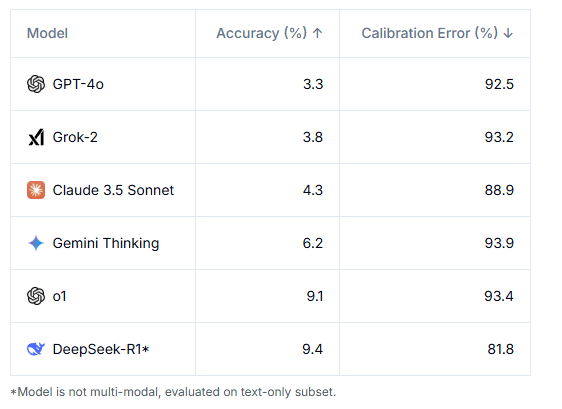
Selbst die fortschrittlichsten KI-Modelle wie GPT-4o, Claude 3.5 oder Gemini erreichen Trefferquoten von weniger als 10 Prozent. GPT-4o löst nur 3,3 Prozent der Aufgaben korrekt, OpenAIs o1 erreicht 9,1 Prozent und Gemini kommt auf 6,2 Prozent. Die Tatsache, dass nur Fragen in den Benchmark aufgenommen wurden, die die Modelle zunächst nicht lösen konnten, erschwert den Test insgesamt.
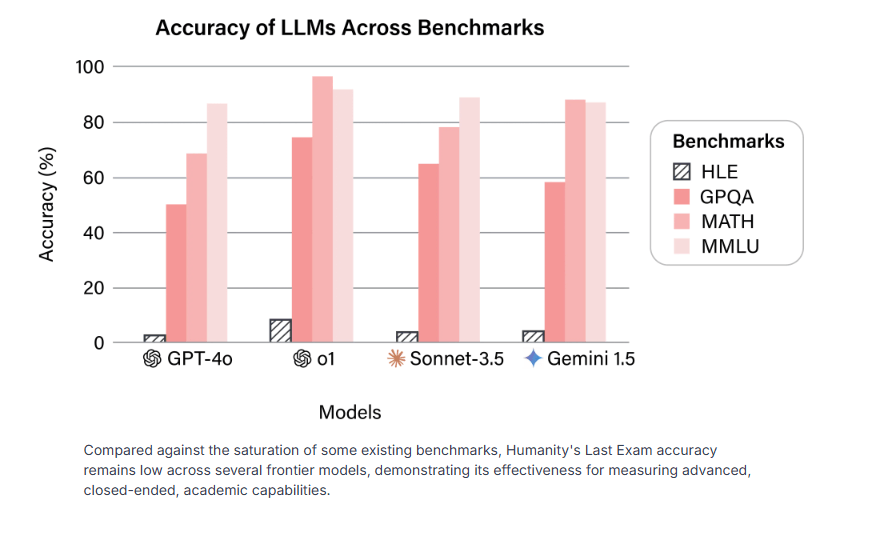
Besonders auffällig ist die Diskrepanz zwischen tatsächlicher Leistung und Selbsteinschätzung der KI-Systeme. Die Modelle zeigen eine extreme Überconfidence mit Kalibrierungsfehlern von über 80 Prozent. Das bedeutet, sie sind sich ihrer Antworten sehr sicher, liegen aber meist falsch. Diese Selbstsicherheit bei völlig falschen Antworten erschwert den Umgang mit generativen KI-Systemen.
Das Projekt ist eine Kooperation zwischen dem gemeinnützigen Center for AI Safety und dem Start-up Scale AI. Initiiert wurde der Test von Dan Hendrycks, Direktor des Center for AI Safety (CAIS) und Berater des xAI-Startups von Elon Musk.
Die Entwickler gehen davon aus, dass KI-Systeme bis Ende 2025 mehr als 50 Prozent der Fragen korrekt beantworten könnten. Dann wären sie "Weltklasse-Orakel", die Expertenfragen in jedem Bereich präziser als Menschen beantworten könnten.
Kritik am Konzept des "letzten Tests"
Subbarao Kambhampati weist auf die grundlegenden Grenzen solcher Leistungstests hin. Der ehemalige Präsident der Association for the Advancement of Artificial Intelligence (AAAI) betont: "Die Essenz der Menschheit liegt nicht in einem statischen Test."
Das eigentlich Menschliche sei vielmehr die Fähigkeit, sich kontinuierlich weiterzuentwickeln und Fragen zu stellen und zu beantworten, die frühere Generationen sich nicht einmal hätten vorstellen können.
Kritisch äußert sich auch KI-Experte Niels Rogge. Er hält Benchmarks dieser Art für den falschen Ansatz: "Ich will keine KI, die nutzlose Fragen über Sehnenknochen in ihren Gewichten speichert. Ich will einen 'Praktikanten', wie Andrej Karpathy es vorschlägt."
Der ehemalige OpenAI-Entwickler Andrej Karpathy schreibt, dass solche Tests beliebt seien, weil sie einfach zu erstellen, zu bewerten und zu verbessern seien. Im Gegensatz dazu seien Tests für die wirklich wichtigen KI-Fähigkeiten - wie das Lösen komplexer, kohärenter Aufgaben, selbst auf Praktikantenniveau - erstaunlich schwer zu entwickeln. Der Name "Humanity's Last Exam" sei übertrieben und irreführend.
Karpathy sieht in den Ergebnissen akademisch anspruchsvoller Benchmarks eine neue Facette des Moravec-Paradoxons: Während KI-Systeme bei komplexen Aufgaben mit klaren Regeln - wie Schach - brillieren können, scheitern sie oft an einfachen Problemen, die Menschen mühelos bewältigen.

Auch die Entwickler des Benchmarks warnen vor vorschnellen Interpretationen: Selbst wenn, wie prognostiziert, KI-Modelle bis Ende 2025 mehr als 50 Prozent der HLE-Fragen richtig beantworten könnten, sei dies noch kein Beweis für "künstliche allgemeine Intelligenz".
Der Test bewerte zwar Expertenwissen und wissenschaftliches Verständnis, aber nur in Form strukturierter akademischer Probleme. Offene Forschungsfragen oder kreative Problemlösungen sind nicht Teil der Prüfung. "Humanity's Last Exam" könne zwar die letzte akademische Prüfung dieser Art sein, aber längst nicht der letzte Maßstab für KI-Fähigkeiten.
"Es gibt eine große Kluft zwischen dem Bestehen einer Prüfung und der Arbeit als praktizierender Physiker und Forscher. Selbst eine KI, die diese Fragen beantworten kann, ist möglicherweise nicht bereit, bei der Forschung zu helfen, die von Natur aus weniger strukturiert ist", sagt Kevin Zhou von der UC Berkeley gegenüber der New York Times.
Der Test soll Wissenschaftlern und politischen Entscheidungsträgern als Referenzpunkt dienen, um KI-Fähigkeiten besser einschätzen zu können. Dies sei wichtig für fundierte Diskussionen über Entwicklungspfade, potenzielle Risiken und notwendige Regulierungsmaßnahmen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.