Neuer Benchmark zeigt: OpenAIs o1-mini ist der beste KI-Selbstkritiker

Eine neue Studie zeigt, dass OpenAIs o1-mini-Modell deutlich besser als andere KI-Systeme darin ist, eigene Fehler zu erkennen und zu korrigieren. Die Forscher entwickelten dafür eine neue Evaluierungsmethode.
Laut der Studie der Chinese University of Hong Kong, Shenzhen, dem Qwen Team von Alibaba und des Shenzhen Research Institute of Big Data schneidet OpenAIs o1-mini-Modell in Tests zur Selbstkritik und Fehlerkorrektur deutlich besser ab als andere Sprachmodelle. Während die meisten Modelle ihre Leistung durch Selbstkritik sogar verschlechterten, konnte o1-mini seine Performance im Schnitt um 3,3 Prozent steigern.
Besonders deutlich zeigte sich der Vorsprung bei mathematischen Aufgaben: Bei College-Math-Problemen verbesserte sich o1-mini durch Selbstkritik um 24 Prozent, bei ARC-Aufgaben um 19,4 Prozent. Neben o1-mini traten GPT-4o, Modelle der Qwen2.5-Familie, Mistral Large und Llama 3.1 an. Das größere Modell o1 oder den o1-Pro-Modus testete das Team nicht, ebenso fehlen die Modelle der Claude-Reihe.
RealCritic: Konstruktive Selbstkritik gewünscht
Die Forscher entwickelten für die Tests eine neue Evaluierungsmethode namens RealCritic. Anders als bisherige Benchmarks prüft diese nicht nur, ob eine KI eigene Fehler erkennt, sondern ob sie diese auch tatsächlich korrigieren kann.
Konkret läuft der Test in einem "geschlossenen Kreislauf" ab: Die KI bekommt eine Aufgabe und eine Lösung, analysiert diese kritisch und muss dann eine verbesserte Lösung liefern. Nur wenn die neue Lösung nachweislich besser ist als die ursprüngliche, gilt die Kritik als erfolgreich.
Bisherige Tests arbeiteten laut dem Team dagegen in einem "offenen Kreislauf": Sie bewerteten nur, ob die KI Fehler erkennen und benennen konnte - nicht aber, ob sie diese auch beheben konnte. Nach Ansicht der Wissenschaftler ist eine Kritik aber nur dann hochwertig, wenn sie bedeutsam zur Selbstverbesserung der KI-Modelle beiträgt.
Klassische Modelle versagen bei Selbstkritik
Die Forscher untersuchten in ihrer Studie drei verschiedene Arten, wie KI-Modelle Kritik üben können. Bei der Selbstkritik (Self-Critique) muss das KI-Modell seine eigenen Lösungen analysieren und verbessern. Dies erwies sich als besonders schwierig: Die meisten Modelle verschlechterten ihre Ergebnisse sogar, wenn sie sich selbst kritisierten. Nur OpenAIs o1-mini konnte seine Leistung durch Selbstkritik im Schnitt um 3,3 Prozent steigern.
Bei der Fremdkritik (Cross-Critique) bewerten die Modelle Lösungen anderer KI-Systeme. Hier schnitten alle Modelle besser ab und konnten fehlerhafte Lösungen verbessern. O1-mini erreichte mit 15,6 Prozent die höchste durchschnittliche Verbesserungsrate.
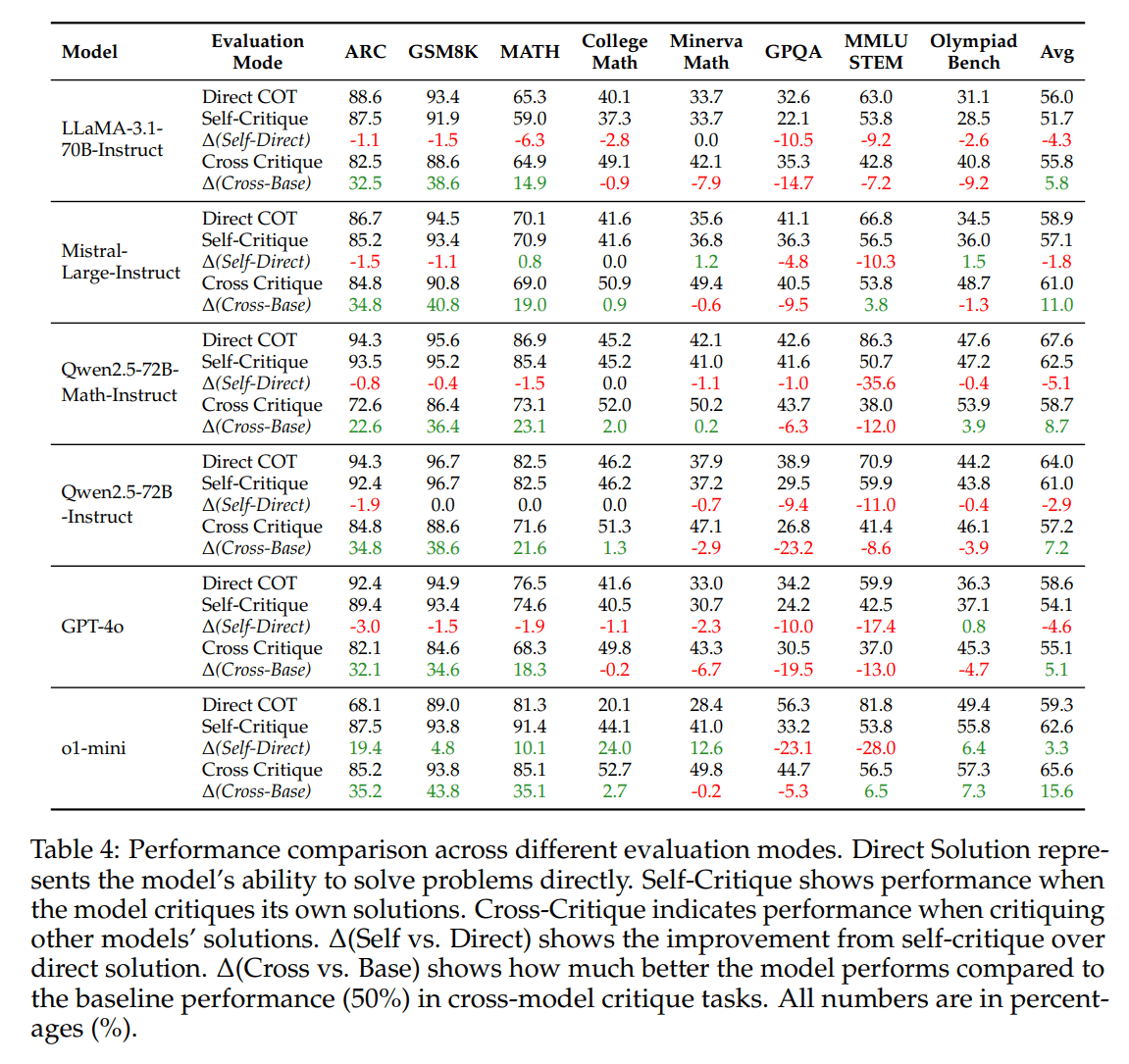
Die iterative Kritik testet dagegen, wie gut sich die Modelle über mehrere Kritik-Runden hinweg verbessern können. Die Studie zeigt, dass die meisten Modelle wie LLaMA und Mistral bereits nach der ersten Runde keine Verbesserungen mehr erzielten oder sich sogar verschlechterten. O1-mini konnte seine Leistung zwar über drei Runden steigern, erreichte dann aber ebenfalls eine Grenze bei etwa 67 Prozent Genauigkeit.
Qwen2.5-72B-Instruct fiel dabei durch besondere Konstanz auf: Als einziges klassisches Modell konnte es sein Verbesserungsniveau über mehrere Runden stabil halten, wenn auch auf niedrigerem Niveau als o1-mini.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.