Qwen2.5-Max: Neues Alibaba-Modell schlägt DeepSeek-V3

Das chinesische Technologieunternehmen Alibaba hat mit Qwen2.5-Max ein neues Sprachmodell entwickelt, das mit einer enormen Menge an Trainingsdaten und starken Ergebnissen in Benchmark-Tests aufwartet.
Alibaba hat neben Qwen2.5-VL und Qwen2.5-1M auch das KI-Sprachmodell Qwen2.5-Max vorgestellt, das als Mixture-of-Expert-Modell (MoE) konzipiert ist und auf über 20 Billionen Trainingstoken basiert. Diese enorme Datenmenge stellt laut dem Team einen neuen Rekord für ein Foundation-Modell dar und soll maßgeblich zur Leistungsfähigkeit des Modells beitragen.
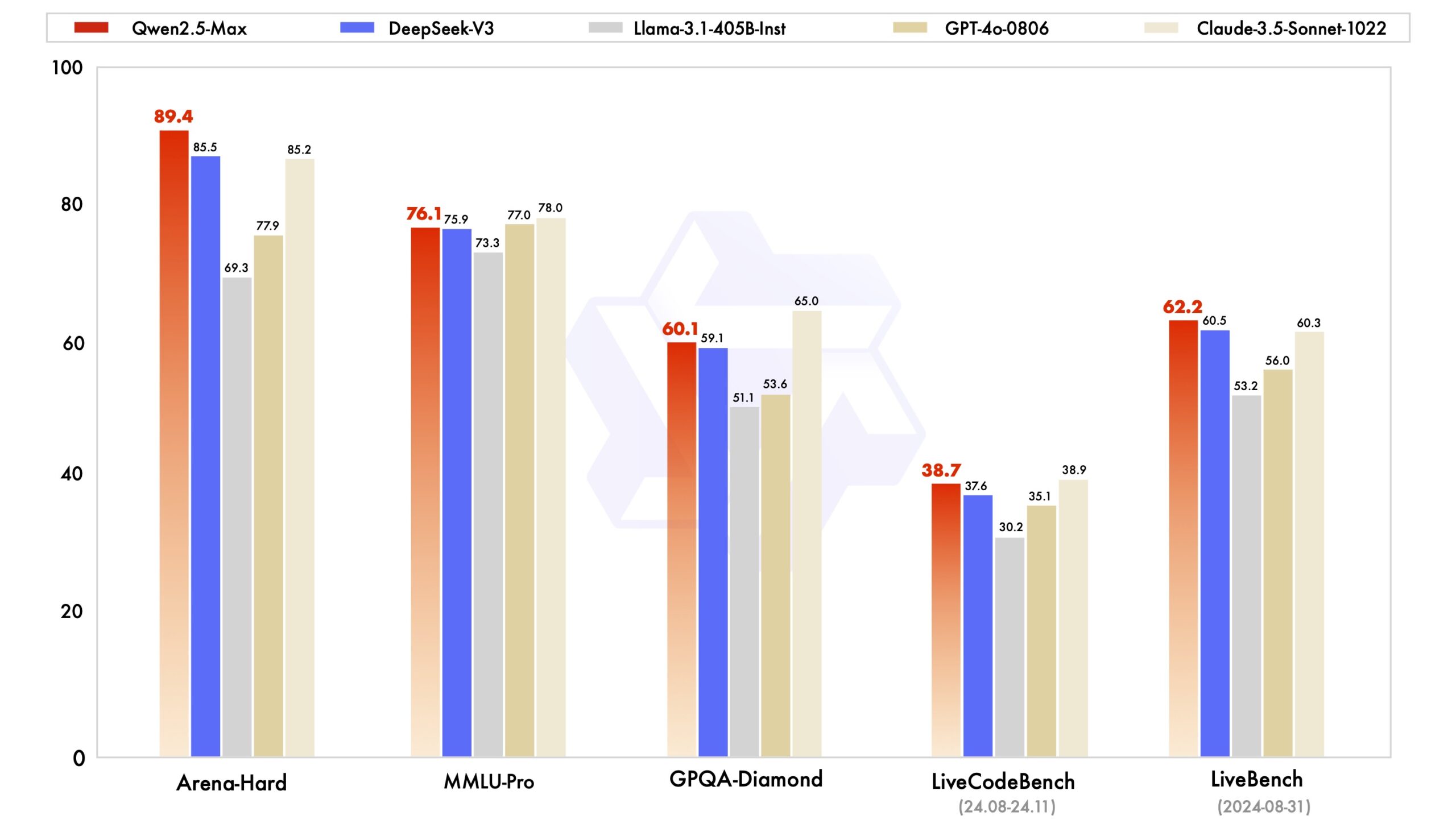
In verschiedenen Benchmark-Vergleichen mit anderen führenden offenen und geschlossenen KI-Modellen wie Deepseek-V3, GPT-4o, Claude 3.5 Sonnet und Llama-3.1-405B schneidet es in einigen Benchmarks besser ab und zeigt in anderen eine starke Performance.
Zu den beiden kommerziellen Modellen sind die genauen Mengen an Trainingsdaten unbekannt, Deepseek-V3 hatte 14,8 Billionen, Llama-3.1-405B rund 15 Billionen.
Alibaba hat bei der Entwicklung von Qwen2.5-Max neben dem Pretraining auf der gewaltigen Datenmenge auch bewährte Techniken wie Supervised Fine-Tuning (SFT) und Reinforcement Learning from Human Feedback (RLHF) eingesetzt.
Qwen2.5-Max über API und in Qwen Chat verfügbar
Interessierte Nutzer können ab sofort über die Alibaba Cloud per API auf Qwen2.5-Max zugreifen. Darüber hinaus steht Qwen2.5-Max auch in Alibabas Chatbot Qwen Chat zum Testen bereit, der ChatGPT-ähnliche Funktionen wie Websuche und Artefakte bietet.
Woher die große Datenmenge stammt, verraten die Forschenden in dem zugehörigen Blogbeitrag nicht. Es ist davon auszugehen, dass synthetische Daten, also von anderen Sprachmodellen produzierte Texte, eine wesentliche Rolle spielen.
Mit dem enormen Investment in Trainingsressourcen hat Qwen jedoch nur mäßigen Vorsprung im Benchmarkvergleich zur Konkurrenz erzielen können. Zuletzt hat sich in der KI-Szene angekündigt, dass der Weg zu besseren Sprachmodellen eher in der Vergrößerung der sogenannten Test-Time Compute liegt.
Die Max-Reihe wird voraussichtlich nur per API verfügbar bleiben und nicht wie andere Qwen2.5-Modelle als Open-Source freigegeben.
Mit der "OpenAI-kompatiblen Schnittstelle" und niedrigen Preisen will Alibaba es Entwickler:innen besonders leicht machen, ihre bestehenden Anwendungen auf die eigene Cloud umzuziehen. Wie andere chinesische Sprachmodelle auch unterliegt Qwen2.5-Max allerdings der Zensur der dortigen Regierung.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.