Mit dieser simplen Methode machen Forscher aus einem LLM ein effizientes Reasoning-Modell

Forschende haben einen ressourcensparenden Ansatz entwickelt, um KI-Modelle mit sorgfältig ausgewählten Trainingsdaten und einer flexiblen Steuerung der Rechenzeit fit für anspruchsvolle Schlussfolgerungen zu machen.
Aus einem Pool von fast 60.000 Frage-Antwort-Paaren wählten die Wissenschaftler:innen 1.000 Frage- und Antwortpaare inklusive der mit Gemini 2.0 Flash Thinking generierten Denkschritte aus, die drei Kriterien erfüllten: Sie sollten anspruchsvoll sein, aus möglichst verschiedenen Bereichen stammen und eine hohe Qualität aufweisen, etwa in Bezug auf Verständlichkeit und Formatierung.

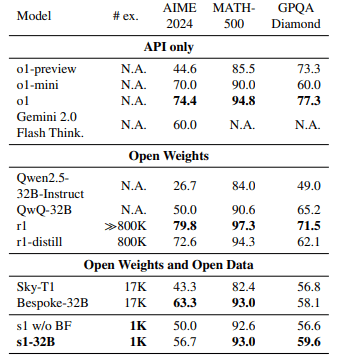
Mit diesem kompakten, aber hochwertigen Datensatz trainierten die unter anderem bei der Stanford University und dem Allen Institute for AI beschäftigten Forschenden ein Sprachmodell mittlerer Größe auf Basis von Qwen2.5 mit 32 Milliarden Parametern namens s1-32B.
"Budget Forcing" verlängert Denkprozess
Das Modell lernte anhand von Musterlösungen, welche Zwischenschritte und Erklärungen zu einer korrekten Antwort führen. Dank der fokussierten Datenauswahl waren dafür lediglich 26 Minuten Rechenzeit auf 16 Nvidia-H100-GPUs nötig, was rund 25 GPU-Stunden entspricht. Genaue Angaben zu ähnlichen Modellen wie OpenAI o1 oder DeepSeek-R1 sind nicht bekannt, liegen aber vermutlich mindestens im vierstelligen Bereich.
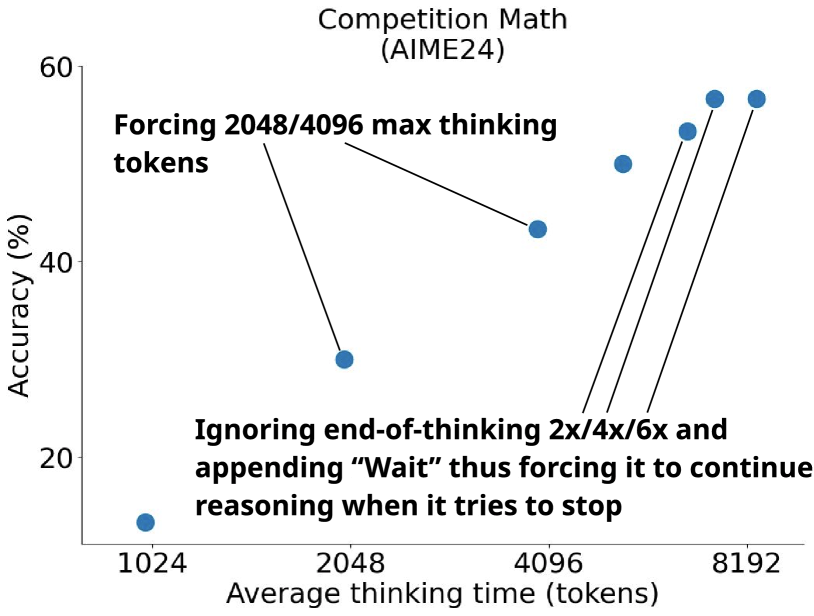
Die zweite Komponente ist eine Methode zur Steuerung des Denkprozesses bei der Inferenz namens Budget Forcing. Wenn das Modell ein vorgegebenes Budget an Rechenschritten überschreitet, wird die Berechnung abgebrochen und das Modell muss eine Antwort geben. Benötigt das Modell dagegen mehr Zeit, wird es durch die Einfügung des Wortes "Wait" veranlasst, seine bisherige Antwort zu hinterfragen und nach Fehlern in der Argumentation zu suchen.

Das Budget Forcing ermöglicht eine bedarfsgerechte Steuerung der "Gründlichkeit" des Modells. In Experimenten führte ein höheres Budget, erzwungen durch ein häufigeres Einfügen von "Wait" in die Ausgabe, zu deutlich besseren Ergebnissen. So übertraf das trainierte Modell in Benchmarks zur Mathematik sogar die Leistung von OpenAIs deutlich datenintensiveren o1-preview und o1-mini.
Qualität schlägt Quantität
In weiteren Experimenten zeigte das Team, dass nur die Kombination aller drei Kriterien bei der Datenauswahl - Schwierigkeit, Vielfalt und Qualität - die volle Leistung bringt. Beschränkungen auf einzelne Kriterien oder eine zufällige Auswahl führten zu bis zu 30 Prozent schlechteren Ergebnissen.
Überraschenderweise brachte selbst der 59-fach größere Gesamtdatensatz keine Verbesserung gegenüber den sorgfältig ausgewählten 1.000 Beispielen. Deutlich wichtiger ist dagegen die Budgetkontrolle: Sie ermöglicht eine genaue Kontrolle der Rechenzeit und führt zu einem klaren Zusammenhang zwischen investierter Zeit und Leistung.
Die Studie demonstriert, dass bereits ein relativ kleiner, aber hochwertiger Trainingsdatensatz ausreicht, um Sprachmodelle auf anspruchsvolle Denkaufgaben vorzubereiten. In Kombination mit dem flexiblen Test-Time Compute können sie dann je nach Bedarf gründlicher arbeiten, ohne dass die Modellgröße angepasst werden muss.
Generell zeigt s1-32B einen spannenden Ansatz in Kombination mit dem Budget Forcing. Die Aussagekraft der Benchmarkergebnisse halten sich jedoch in Grenzen, weil sie nur einen eng abgesteckten Kompetenzbereich beleuchten.
Die Forschenden haben ihren Code und die Trainingsdaten auf GitHub veröffentlicht, um die Weiterentwicklung der Methode zu fördern.
Über die letzten Jahre haben zahlreiche Forschungsgruppen versucht, mit wachsendem Aufwand und teils enormen Datenmengen die Leistung führender KI-Modelle bei komplexen Schlussfolgerungen zu erreichen. Gerade erst hat OpenAI sein neuestes Reasoningmodell o3-mini in ChatGPT implementiert.
Zuletzt hat jedoch das chinesische DeepSeek unter Beweis gestellt, dass konkurrenzfähige Modelle vor allem durch effizienten Ressourcenumgang und guten Ideen entstehen - und Budget Forcing könnte eine davon sein.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.