Meta MILS: Reine Sprachmodelle sollen ohne spezielles Training sehen und hören lernen

Ein neuer Ansatz ermöglicht es großen Sprachmodellen, Fähigkeiten wie Bild-, Video- und Audioverständnis sowie Bildgenerierung und -bearbeitung zu erwerben - ohne spezielles Training.
Forschende von Meta AI, der University of Texas at Austin und der UC Berkeley haben dazu ein System namens MILS (Multimodal Iterative LLM Solver) entwickelt. Anstelle von speziellem Training für die jeweiligen Aufgaben baut es auf die Fähigkeit der LLMs, Probleme zur Inferenz zu lösen.
MILS verwendet ein LLM als "Generator", um Lösungsvorschläge für eine gegebene Aufgabe zu erstellen. Ein vortrainiertes Modell, das bereits mit verschiedenen Datentypen arbeiten kann, dient als "Scorer", um die Qualität jedes Vorschlags zu bewerten.
Das Feedback des Scorers wird an den Generator zurückgegeben, um schrittweise bessere Lösungen zu generieren, bis der Prozess ein zufriedenstellendes Ergebnis liefert oder eine bestimmte Anzahl von Schritten erreicht ist.
Vielseitige Fähigkeiten ohne spezielles Training
Die Forschenden zeigen, dass sich MILS problemlos an neue Aufgaben und Datentypen anpassen lässt, indem Generator- und Scorer-Module ausgetauscht werden, und demonstrieren dies für Bilder, Videos und Audio sowie für Aufgaben wie Beschreibung, Generierung und Bearbeitung.
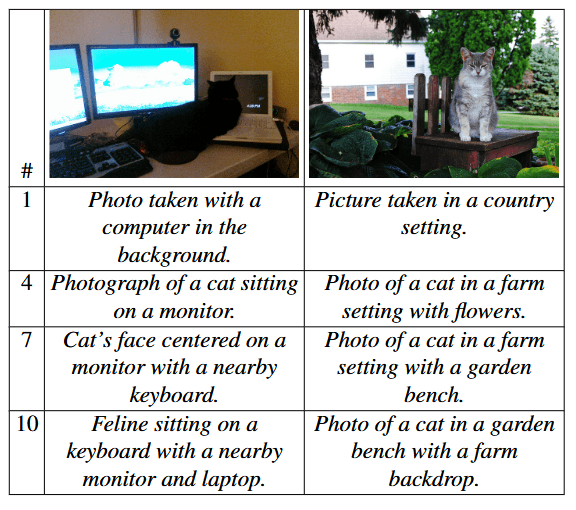
Vor allem bei der Bildbeschreibung erzielt MILS beeindruckende Ergebnisse. Es verwendet Llama-3.1-8B als Generator und das bewährte CLIP-Modell, das Bilder und Texte zuordnen kann, als Scorer.
Obwohl CLIP keine perfekten Bildbeschreibungen kennt, wie sie normalerweise zum Training von Bilduntertitelungsmodellen verwendet werden, ermöglicht es MILS, aussagekräftige Beschreibungen zu erstellen. Dabei ist es sogar genauer als bestehende State-of-the-Art-Methoden.
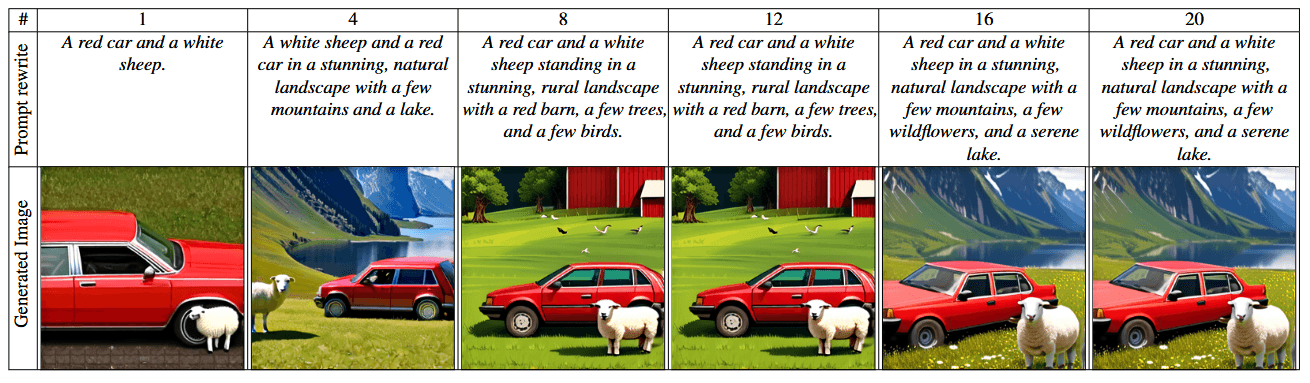
Bei der Bildgenerierung verbessert MILS Text-zu-Bild-Modelle, indem es die Textprompts optimiert. Auch Bildbearbeitungsaufgaben wie die Stilübertragung beherrscht MILS, indem es vom LLM generierte Prompts mit einem Bildbearbeitungsmodell kombiniert.
Der Ansatz funktioniert auch für Video- und Audiodaten. So erzielt MILS etwa eine starke Leistung bei der Videobeschreibung auf dem Testdatensatz MSR-VTT und übertrifft dabei bestehende Modelle.
Kombination von Daten durch Umwandlung in Text
Da MILS ohne Gradienten, also ohne Anpassung der Modellparameter, funktioniert, kann es die internen Repräsentationen verschiedener Datentypen in lesbaren Text umwandeln. Das ermöglicht neuartige Anwendungen wie die Kombination von Informationen aus verschiedenen Quellen (z. B. Bild und Audio), indem diese zunächst in Text umgewandelt, dann kombiniert und schließlich wieder in Bilder übersetzt werden.
Untersuchungen zeigen, dass größere Generator- und Scorer-Modelle sowie umfangreichere Ausgangsmengen an Lösungsvorschlägen in der Regel zu besseren Ergebnissen führen. Insbesondere die Verwendung größerer LLMs zeige vielversprechende Verbesserungen.
Viele Sprachmodelle haben über die letzten Monate immer mehr multimodale Fähigkeiten bekommen, nach OpenAIs GPT-4o haben auch Open-Source-Anwärter nachgezogen. Metas Llama-Reihe versteht Bilder etwa seit Llama 3.2, Mistral seit Pixtral und DeepSeek seit Janus Pro. Diese Kompetenz ist essenziell für vielseitige KI-Assistenten für den Alltag.
Inwieweit MILS jedoch die Entwicklung vorantreibt, bleibt abzuwarten – schließlich wird das Training nicht gänzlich eliminiert, sondern auf ein anderes, bereits vortrainiertes Modell als Scorer ausgelagert. Gleichwohl passt die Methode gut in die aktuellen Bestrebungen der Szene, Sprachmodelle nicht mit immer mehr Trainingsdaten, sondern mehr Ressourcen bei der Inferenz zu verbessern. Einen sinnvollen Einsatz von MILS sehen die Forschenden auch bei Aufgaben mit 3D-Daten.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.