OpenAI schlägt Deepseek überraschend deutlich in Googles neuestem Reasoning Benchmark

BIG-Bench wurde 2021 als eine Art universeller Benchmark für eine neue Generation großer Sprachmodelle entwickelt. Doch aktuelle Modelle stoßen an dessen Grenzen. Google DeepMind stellt nun BIG-Bench Extra Hard (BBEH) vor - und offenbart selbst bei den besten Modellen erhebliche Mängel.
BIG-Bench („Beyond the Imitation Game Benchmark”) und auch die härtere Version BIG-Bench Hard (BBH) stoßen an ihre Grenzen: Aktuelle Spitzenmodelle erreichen hier bereits eine Genauigkeit von über 90 Prozent. Um diesem Problem zu begegnen, hat Google DeepMind nun den neuen Benchmark BIG-Bench Extra Hard (BBEH) entwickelt.
BBEH baut auf dem bewährten BBH auf, indem jede der ursprünglich 23 Aufgaben durch eine deutlich anspruchsvollere Variante ersetzt wurde. Diese neuen Aufgaben erfordern ein breiteres Spektrum an Reasoning-Fähigkeiten.
Ein wesentlicher Unterschied zu BBH besteht darin, dass die Aufgaben in BBEH im Durchschnitt sechsmal länger sind und deutlich mehr Denkschritte erfordern. Das zeigt sich auch darin, dass die Antworten der Modelle im Durchschnitt siebenmal länger sind als bei BBH.
Zu den neuen Reasoning-Fähigkeiten, die in BBEH getestet werden, gehören etwa der Umgang mit und das Reasoning in sehr langen Kontextabhängigkeiten, das Lernen neuer Konzepte, die Unterscheidung zwischen relevanten und irrelevanten Informationen oder die Fehlersuche in vorgegebenen Reasoning-Ketten.
Ein Beispiel ist die Aufgabe "Spatial Reasoning", bei der sich ein Agent durch eine geometrische Struktur bewegt und Objekte an verschiedenen Positionen beobachtet. Um die Aufgabe zu lösen, müssen die Modelle verfolgen, welche Objekte sich an welchen Positionen befinden, und teilweise Rückschlüsse ziehen. Im Gegensatz dazu wird beim "Object Properties"-Test eine Sammlung von Objekten mit verschiedenen Eigenschaften (wie Farbe, Größe, Herkunft, Geruch und Material) präsentiert, die durch verschiedene Veränderungen aktualisiert werden.
Die Modelle müssen die Eigenschaften aller Objekte nach jeder Änderung verfolgen, wobei einige Aktualisierungen besonders knifflig sind, wie der Verlust eines nicht spezifizierten Objekts mit bestimmten Eigenschaften. Am Ende wird eine Frage gestellt, bei der gezählt werden muss, wie viele Objekte bestimmte Eigenschaften haben oder nicht haben.
o3-mini schlägt R1 unerwartet deutlich
Google DeepMind hat verschiedene Modelle getestet, darunter General-Purpose-Modelle wie Gemini 2.0 Flash und GPT-4o sowie spezialisierte Reasoning-Modelle wie o3-mini (high) und DeepSeek R1. Die Ergebnisse zeigen deutliche Schwächen: Das beste General-Purpose-Modell Gemini 2.0 Flash erreicht nur eine durchschnittliche Genauigkeit von 9,8 Prozent, das beste Reasoning-Modell o3-mini (high) nur 44,8 Prozent. GPT-4.5 wurde noch nicht getestet.
Die Analyse zeigt die erwarteten Unterschiede zwischen allgemeinen und auf Reasoning spezialisierten Modellen. Letztere schneiden besonders gut bei formalen Problemen ab, die Zählen, Planen, Arithmetik sowie Datenstrukturen und Algorithmen betreffen. Bei Aufgaben, die Common Sense, Humor, Sarkasmus und kausales Verständnis erfordern, ist der Vorsprung der spezialisierten Modelle dagegen deutlich geringer oder gar nicht vorhanden.
"Unsere Ergebnisse zeigen, dass Reasoning-Modelle die größten Fortschritte bei formalen Problemen machen, aber nur begrenzte Fortschritte bei den weicheren Reasoning-Fähigkeiten zeigen, die typischerweise in komplexen Szenarien der realen Welt benötigt werden", schlussfolgern die Forscher.
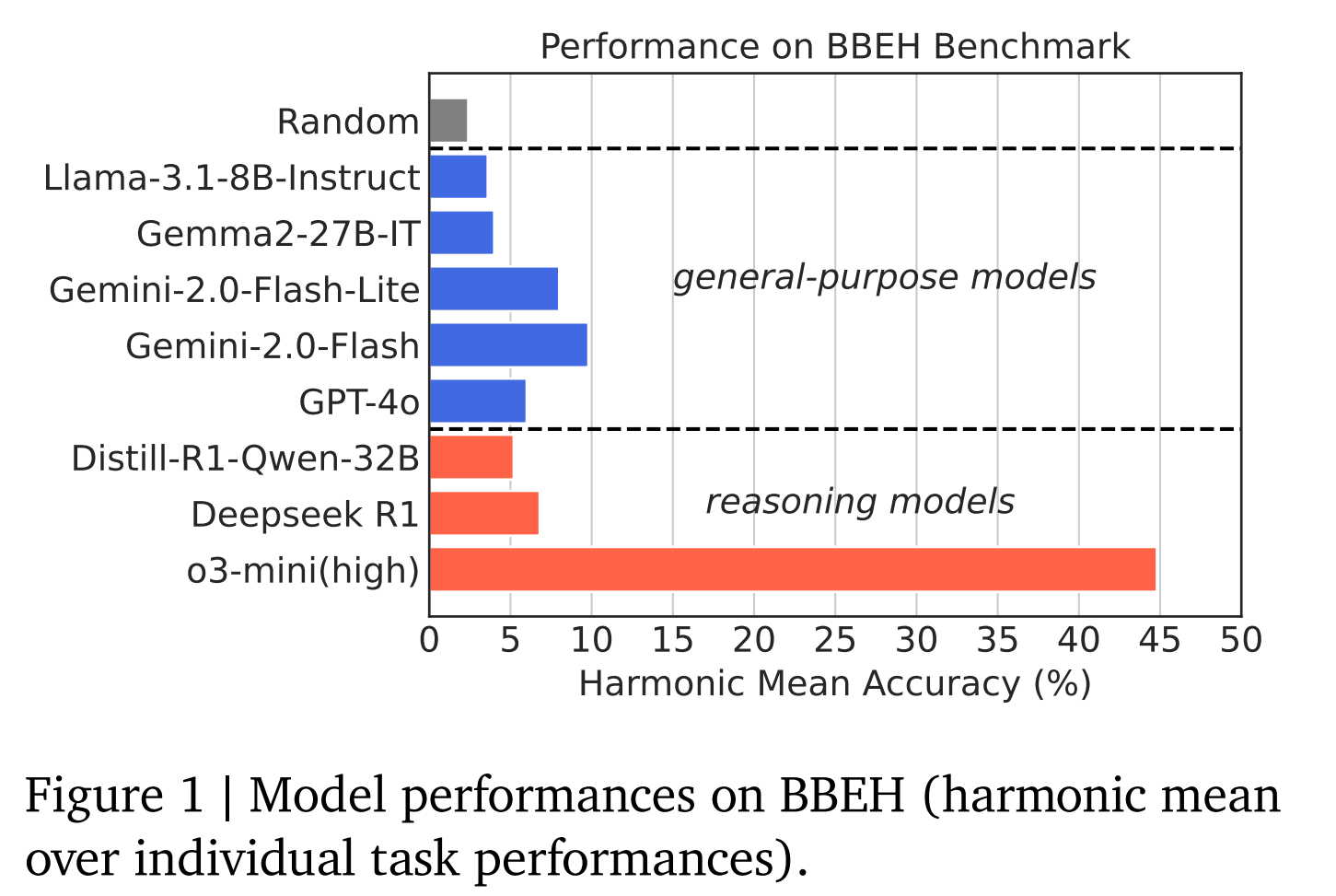
Besonders auffällig ist der große Abstand des Reasoning-Modells o3-mini (high) von OpenAI zum viel diskutierten Deepseek R1. In einigen Benchmarks, wie dem "Object-Properties"-Test, kann das chinesische Modell die Aufgabe gar nicht lösen, in anderen liegt es deutlich hinter dem OpenAI-Modell. Dies liegt nach Ansicht der Autoren in den meisten Fällen daran, dass das Modell das Problem nicht in seiner effektiven Output-Token-Länge lösen konnte und dann den Faden verlor. Lediglich im Test "BoardgameQA" schlägt R1 o3-mini mit deutlichem Abstand. Insgesamt erreicht R1 nur eine durchschnittliche Genauigkeit von 6,8 Prozent und liegt damit drei Prozentpunkte hinter Gemini 2.o Flash.
Reasoning-Modelle und größere Modelle schneiden - meistens - besser ab
Die Forscher untersuchten auch, wie sich die Kontextlänge und die erforderliche "Denkmenge" (gemessen an der Ausgabelänge) auf die Leistung der Modelle auswirken. Sie stellten fest, dass spezialisierte Reasoning-Modelle wie o3-mini (high) gegenüber allgemeinen Modellen wie GPT-4o mit zunehmender Kontextlänge und zunehmender Komplexität der erforderlichen Denkprozesse einen größeren Vorsprung haben.
Für größere vs. kleinere allgemeine Modelle (Gemini 2.0 Flash vs. Flash-Lite) zeigte sich ein ähnlicher Vorteil bei längeren Kontexten.
BBEH zeigt, dass moderne LLMs zwar große Fortschritte gemacht haben, aber noch weit davon entfernt sind, allgemeine Denkfähigkeit zu erreichen. Die Autoren betonen, dass noch erhebliche Forschungsanstrengungen erforderlich seien, um diese Lücken zu schließen und vielseitigere KI-Systeme zu entwickeln.
Der Benchmark ist öffentlich verfügbar unter: https://github.com/google-deepmind/bbeh
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.