Alibaba entwickelt flexible Einheitslösung für KI-Videobearbeitung

Wissenschaftler:innen der Alibaba Group haben das universelle KI-Modell VACE entwickelt, das mehrere Videogenerierungs- und Editieraufgaben in einem Modell vereint.
Dafür erweiterten die Forschenden die bewährte Diffusion-Transformer-Architektur um das neue multimodale Eingabeformat "Video Condition Unit" (VCU). Es kodiert Texteingaben, Referenzbilder oder -videos sowie Masken einheitlich.
"Video Condition Unit" vereint Text, Bilder und Masken
Eine VCU besteht aus drei Teilen: Einer Textbeschreibung, einer Sequenz von Referenzbildern oder -videos und einer Sequenz von Masken. Die Forscher:innen entwickelten spezielle Mechanismen, um diese multimodalen Eingaben effizient miteinander zu kombinieren.
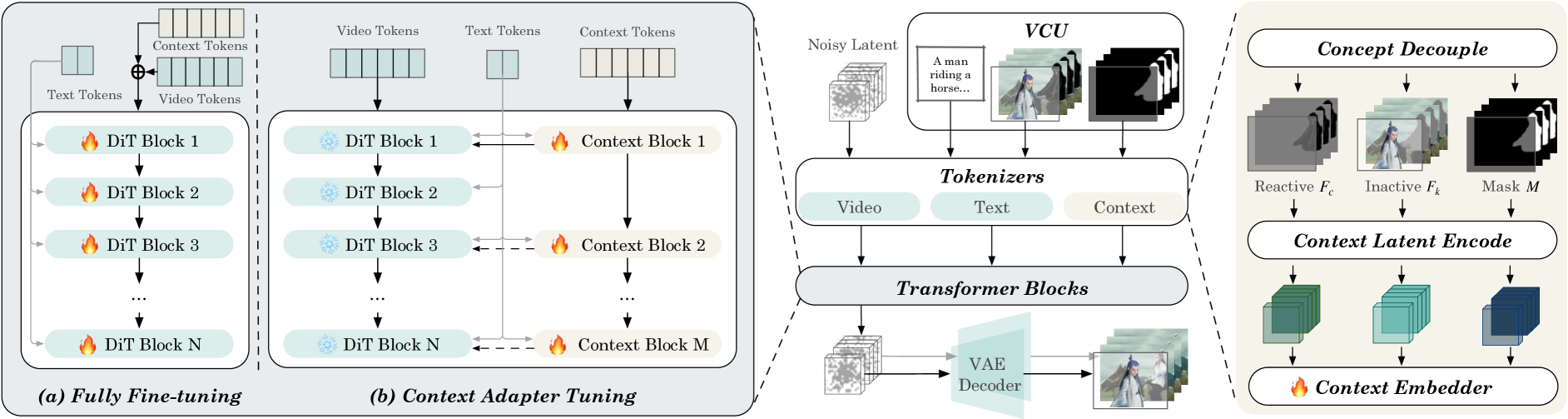
Zunächst trennen sie die Bildinformationen anhand der Masken in zwei Teile: Einen "reaktiven" Teil, der verändert werden soll, und einen "inaktiven" Teil, der unverändert bleibt. Dann werden die Bilder in einen gemeinsamen Merkmalsraum überführt und mit dem Text kombiniert.
Um die zeitliche Konsistenz zu gewährleisten, werden die Merkmale in einen Latenzraum projiziert, der die gleiche Struktur wie der des Diffusion-Transformers hat. Spezielle Zeit-Embedding-Schichten sorgen für eine konsistente Verarbeitung über die Zeit.
Schließlich kommt ein Aufmerksamkeitsmechanismus zum Einsatz, der die Merkmale der verschiedenen Modalitäten und Zeitschritte miteinander in Beziehung setzt. So kann das Modell die Eingaben ganzheitlich verarbeiten und daraus neue Videos generieren oder bestehende editieren.
Text-zu-Video, Referenz-zu-Video und Videobearbeitung
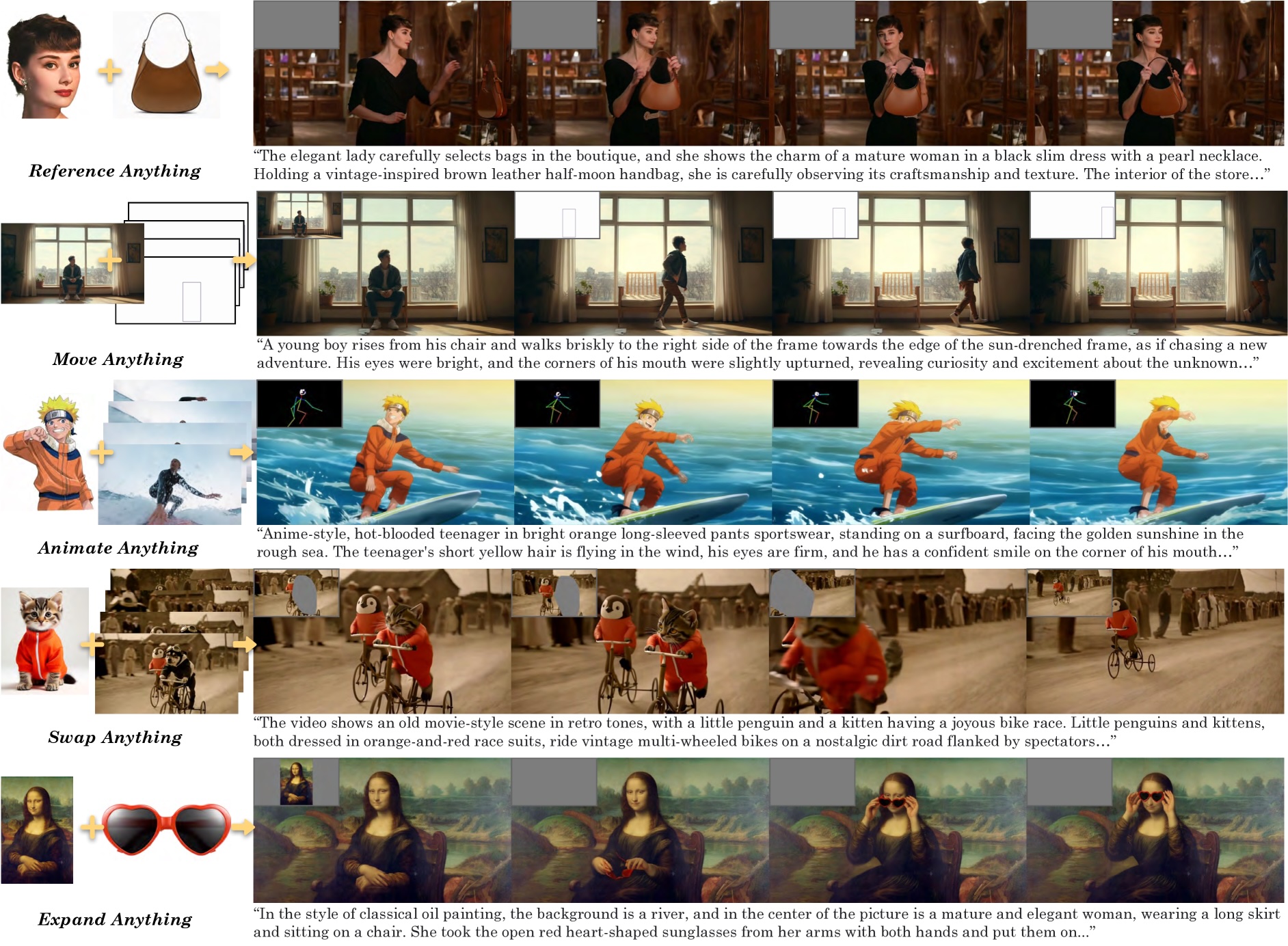
VACE beherrscht vier Basis-Aufgaben: Text-zu-Video, Referenz-zu-Video, Video-zu-Video-Bearbeitung und maskierte Video-Editierung. Durch ihre Kombination ermöglicht es vielfältige Anwendungen.
Die Alibaba-Forscher:innen demonstrieren beispielsweise, wie VACE eine Person in einem Video zum Bildrand laufen lässt, ein Anime-Charakter auf einem Surfbrett animiert oder Objekte wie Pinguine und Kätzchen in einer Szene austauscht. Auch Hintergründe lassen sich passend zur Handlung erweitern. Weitere Beispiele in Bewegtbild sind auf der Projektseite.
Für das Training nutzten sie zunächst Basis-Aufgaben wie Inpainting und Erweiterung, um das Text-zu-Video-Modell zu ergänzen. Später fügten sie Referenzbilder und komplexere Aufgaben hinzu. Die Trainingsdaten stammen aus Internet-Videos, die sie automatisch filterten, segmentierten und mit Tiefen- und Poseninformationen anreicherten.
VACE-Benchmark mit 480 Beispielen zeigt Stärken des Modells
Mit dem VACE-Benchmark wollen die Forscher die Leistung von VACE und anderen Modellen vergleichbar machen. Er enthält 480 Beispiele für zwölf verschiedene Aufgaben, darunter Inpainting, Outpainting, Stilisierung, Tiefenkontrolle und Referenzbilder.
Im Benchmark erzielte VACE durchweg bessere Ergebnisse als spezialisierte Open-Source-Modelle. In Nutzerstudien schneidet es ebenfalls besser ab. Nur bei der Referenz-zu-Video-Generierung liegt es noch hinter kommerziellen Lösungen wie Vidu oder Kling.
Die Alibaba-Forschenden sehen VACE als wichtigen Schritt hin zu universellen, multimodalen Videomodellen. Sie wollen es weiter verbessern und mit mehr Daten und Rechenleistung trainieren, um noch realistischere Videos zu ermöglichen, und Teile von VACE als Open-Source-Projekt veröffentlichen.
VACE ist nur eines von vielen KI-Projekten des chinesischen Konzerns, der in jüngster Zeit vor allem in der Qwen-Reihe zahlreiche leistungsfähige Sprachmodelle veröffentlicht hat. Andere chinesische Tech-Unternehmen wie ByteDance experimentieren ebenfalls mit Video-KI und scheinen mindestens eine ähnliche, wenn nicht sogar bessere Qualität zu bieten als westliche Angebote wie das kürzlich in Europa eingeführte Sora von OpenAI.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.