Neue Sprache für Bild-KI soll kompakter und genauer sein

Ein neuer Ansatz von Forschenden aus Hongkong und Großbritannien zur Umwandlung von Bildern in digitale Repräsentationen (Tokens) soll es ermöglichen, die wesentlichen Informationen in einer hierarchischen Struktur zu erfassen.
Die Besonderheit des neuen Ansatzes liegt darin, wie diese Token angeordnet sind. Anstatt alle Bildinformationen gleichmäßig auf die Token zu verteilen, werden sie in einer hierarchischen Struktur organisiert.
Dabei erfassen die ersten Token die wichtigsten visuellen Merkmale des Bildes, wie etwa grobe Formen und Strukturen. Nachfolgende Token fügen dann schrittweise immer feinere Details hinzu, bis das Bild vollständig repräsentiert ist.

Dieses Prinzip ähnelt einem Verfahren aus der Statistik, der sogenannten Hauptkomponentenanalyse. Hierbei werden Daten in Komponenten zerlegt, die in absteigender Reihenfolge zur Erklärung der Unterschiede (Varianz) in den Daten beitragen. Die Forscher:innen haben dieses Konzept nun auf die Tokenisierung von Bildern übertragen und so eine neuartige Bilddarstellung geschaffen, die kompakt und besser verständlich ist.

Ein weiterer Vorteil der neuen Methode ist die Trennung von bedeutungstragenden (semantischen) Informationen und reinen Bilddetails. In früheren Ansätzen waren diese oft miteinander vermischt, was die Interpretation der erlernten Repräsentationen erschwerte.
Die Forschenden lösten dieses Problem, indem sie einen diffusionsbasierten Decoder einsetzten, der die Bilder schrittweise von groben Strukturen zu feinen Details rekonstruiert. Dadurch konzentrieren sich die Tokens auf die semantisch bedeutsamen Informationen, während die Bilddetails separat behandelt werden.
Ansatz verbessert die Rekonstruktionsqualität
Experimente zeigen, dass die neue Methode die Rekonstruktionsqualität, also die Ähnlichkeit zwischen dem ursprünglichen Bild und seiner tokenisierten Darstellung, im Vergleich zum bisherigen Stand der Technik um fast zehn Prozent verbessert.
Zudem benötigt sie nur einen Bruchteil der Token, um vergleichbare Ergebnisse zu erzielen. Auch bei der Verwendung der erlernten Repräsentationen für weiterführende Aufgaben, wie die Klassifizierung von Bildern, zeigte der neue Ansatz bessere Ergebnisse als bisherige Verfahren.
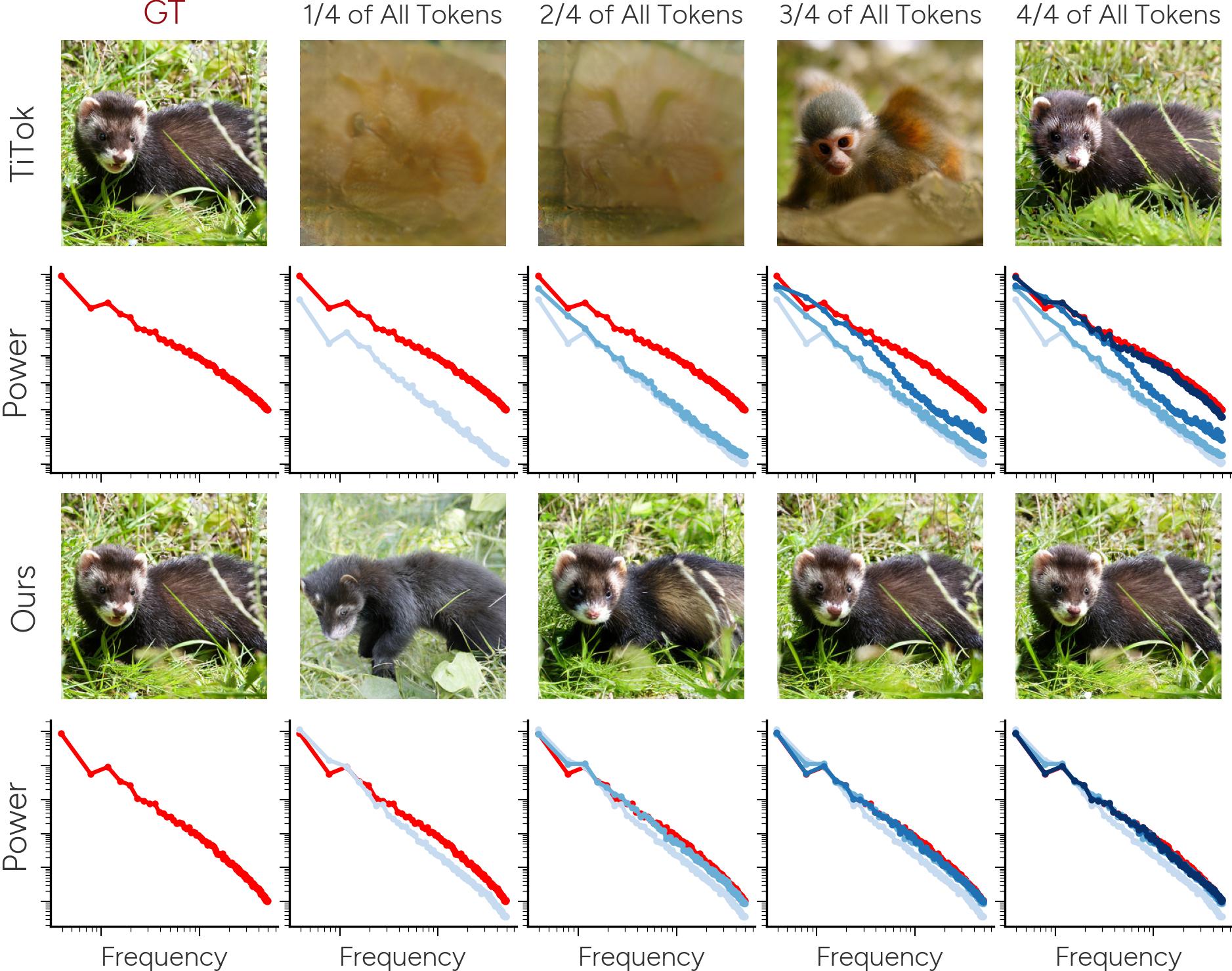
Die hierarchische Struktur der Token spiegelt die Art und Weise wider, wie das menschliche Gehirn visuelle Informationen verarbeitet: von groben Formen und Strukturen hin zu immer feineren Details. Diese Erkenntnisse eröffnen laut der Untersuchung neue Möglichkeiten für die Entwicklung von KI-Systemen zur Bildanalyse und -generierung, die sich stärker an der menschlichen Wahrnehmung orientieren.
Potenzial für verständlichere und effizientere KI-Systeme
Durch die verbesserte Interpretierbarkeit der erlernten Repräsentationen könnte es in Zukunft leichter werden, die Entscheidungen von KI-Systemen nachzuvollziehen und zu erklären. Gleichzeitig ermöglicht die kompaktere Darstellung der Bildinformationen eine effizientere Verarbeitung und Speicherung.
Die Forschenden betonen, dass dies ein wichtiger Schritt in Richtung einer stärker an der menschlichen Wahrnehmung orientierten Bildverarbeitung ist, sehen aber auch noch Raum für Verbesserungen. In zukünftigen Arbeiten gelte es, den Ansatz weiter zu verfeinern und auf eine breitere Palette von Anwendungen zu übertragen.
Die Tokenisierung stellt sowohl bei Bild- als auch Sprachmodellen einen wichtigen Bestandteil der Leistungsfähigkeit dar. Auch bei der digitalen Repräsentation von Textbausteinen gibt es immer wieder neue Ansätze, die in Zukunft zu besseren Modellen führen könnten.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.