Weltmodelle statt Prompts: KI-Modelle sollen künftig aus Erfahrung lernen statt nur aus Text
Die "Bitter Lesson" von Richard Sutton formuliert eine zentrale Lehre der modernen KI-Forschung: Nicht der Einbau menschlichen Wissens, sondern skalierbare Lern- und Suchverfahren bringen langfristig den größten Fortschritt. Eine neue Veröffentlichung von Sutton und David Silver knüpft an diese These an – und entwirft eine weitreichende Vision für KI-Agenten, die sich allein durch Handeln und Feedback weiterentwickeln.
2019 formulierte Richard Sutton in einem kurzen Essay eine der einflussreichsten Einsichten der aktuellen KI-Forschung. Die zentrale These: Der größte Fortschritt in der KI wurde nicht durch menschliche Einsichten erzielt, sondern durch Maschinen, die mit viel Rechenleistung und wenig Vorwissen lernten, sich selbst zu verbessern. Der Mensch, so Sutton, neige dazu, seine Intuition in Algorithmen zu pressen – doch langfristig seien es die systematischen, datengetriebenen Ansätze, die gewännen.
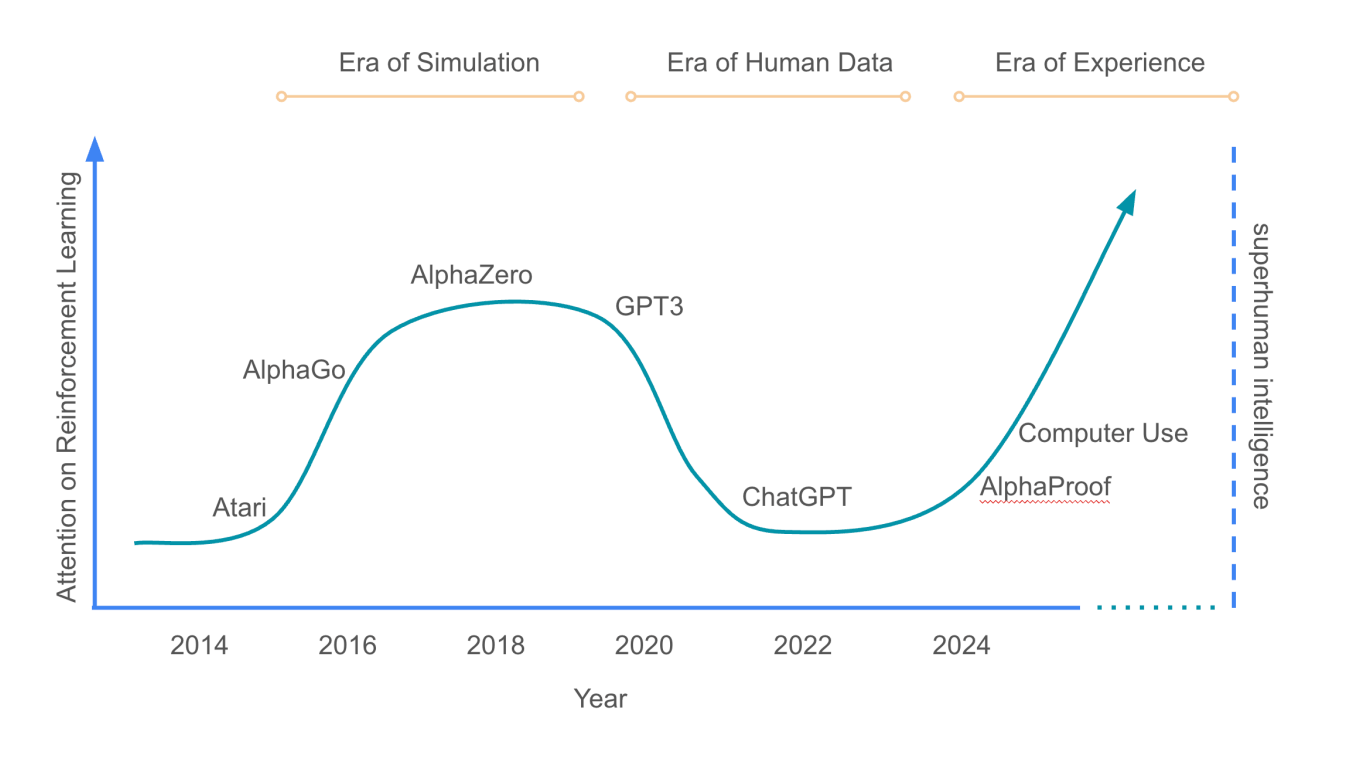
Dieses als "Bitter Lesson" bekannte Prinzip gilt inzwischen als Grundpfeiler des Reinforcement Learnings (verstärkendes Lernen, RL), das etwa hinter der bekannten Brettspiel-KI AlphaGo steckt und auch bei den neuesten Fortschritten sogenannter "Reasoning-Sprachmodellen" zum Einsatz kommt.
Fünf Jahre später erscheint mit "Welcome to the Era of Experience" ein neuer Aufsatz, der diese Idee weiterführt. Sutton – Turing-Preisträger und Leiter des Deepmind-Labors in Alberta – verfasst ihn gemeinsam mit David Silver, seinem ehemaligen Doktoranden und heute führender Reinforcement-Learning-Forscher bei Deepmind.
Gemeinsam fordern sie darin einen Paradigmenwechsel: Weg vom Training mit menschlichem Wissen, hin zu Systemen, die aus eigener Erfahrung lernen – mit dem Ziel, KI-Systeme zu entwickeln, die eigene Erkenntnisse schaffen, statt nur vorhandenes menschliches Wissen zu imitieren.
Erfahrung statt Nachahmung
Laut Silver und Sutton sind die bestehenden generativen KI-Systeme – etwa große Sprachmodelle – stark von menschlichen Daten geprägt. Sie basieren auf Milliarden von Wörtern aus menschlichen Quellen – Bücher, Webseiten, Foren.
Obwohl diese Modelle ein beeindruckendes Spektrum an Aufgaben bewältigen können, stoßen sie doch an Grenzen: Die Menge an qualitativ hochwertigen Daten ist endlich, und viele wissenschaftliche oder technische Durchbrüche liegen jenseits des heutigen menschlichen Wissens. KI-Modelle würden durch Nachahmung zwar kompetent, aber nicht kreativ.
Ein neuer Ansatz sei notwendig: Agenten, die kontinuierlich aus ihren eigenen Handlungen und Beobachtungen lernen. Statt einmalig trainiert zu werden, sollen sie in einem permanenten Strom von Erfahrungen leben und sich über Monate oder Jahre hinweg an ihre Umwelt anpassen – ähnlich wie Menschen oder Tiere. Jeder neue Versuch, jede neue Handlung in einer Umgebung sei eine neue Datenquelle. Erfahrung sei – im Gegensatz zu menschlichen Daten – unerschöpflich.
Die Autoren sehen darin einen grundlegenden Wechsel: von statischen Datensätzen zu dynamischen Interaktionen, von überwachtem Lernen zu selbstbestimmter Exploration. Die zentrale Einheit der Intelligenz sei nicht mehr der Prompt, sondern die Handlung. Ein solcher Durchbruch könnte eine exponentielle Entwicklung von KI-Systemen ermöglichen.
KI trainieren mit Weltmodellen
Das Paper verbindet klassische Methoden des Reinforcement Learnings mit neuen Konzepten. Dabei verweisen die Autoren auf AlphaProof, ein KI-System, das mit formaler Mathematik trainiert wurde: Nach einer initialen Phase mit menschlichen Beweisen generierte das System mehr als 100 Millionen zusätzliche Beweisschritte durch autonome Interaktion – und erreichte damit ein Leistungsniveau, das bisherige, menschlich trainierte Systeme übertraf.
Diese Prinzipien sollen nun auf reale Umgebungen übertragen werden: Gesundheitsassistenten, die Schlafdaten analysieren und Empfehlungen anpassen; Bildungsagenten, die Lernverläufe über Jahre hinweg verfolgen; oder wissenschaftliche Systeme, die eigene Experimente durchführen.
Entscheidend ist dabei: Die Belohnung der Agenten erfolgt nicht mehr allein durch menschliche Bewertungen, sondern durch messbare Signale aus der Umwelt – etwa Ruhepuls, CO₂-Werte oder Testergebnisse. Auch menschliches Feedback könne als "geerdetes" Signal dienen, wenn es die Konsequenz einer Handlung misst – etwa wie gut ein Kuchen schmeckt, wie erschöpft man nach einem Training ist oder wie stark Kopfschmerzen nach einer Medikamentenempfehlung noch sind.
Beim maschinellen Denken fordern die Autoren einen Bruch mit bisherigen Praktiken. Sprachmodelle imitieren menschliche Denkprozesse, etwa in Form von "Chain-of-Thought"-Prompting. Doch diese Methode vererbe auch menschliche Fehler, Annahmen und historische Irrtümer.
Stattdessen sollen Agenten eigene Denkstrategien entwickeln, gestützt auf sogenannte Weltmodelle: interne Simulationen, mit denen sie die Konsequenzen ihrer Handlungen vorhersagen. Dies ermöglicht echte Planung, jenseits von rein sprachlicher Argumentation. Der Weg zu autonomeren Agenten führt laut den Autoren auch über Zwischenschritte wie das Aufrufen von APIs und die Nutzung von Ausführungs-Feedback ("Execution Feedback"), bei dem der Agent Code ausführt und die Ergebnisse beobachtet.
Die Autoren sehen in der "Era of Experience" eine Rückbesinnung auf klassische RL-Konzepte, die im Zuge des Erfolgs großer Sprachmodelle in den Hintergrund geraten seien. Techniken wie temporale Abstraktion, exploratives Verhalten oder dynamische Wertfunktionen seien essenziell für Agenten, die langfristig lernen und planen.
Dabei betonen sie, dass der Übergang zur Erfahrungsära bereits begonnen habe – durch Agenten, die über allgemeine digitale Schnittstellen mit der Welt interagieren, durch leistungsfähige Reinforcement-Learning-Methoden für offene Probleme und durch die zunehmende Kopplung von Agenten an reale Umweltsignale.
Mehr Autonomie, mehr Verantwortung
Die Autoren sehen in dieser Entwicklung sowohl Potenzial als auch Risiko. Agenten könnten Fähigkeiten entwickeln, die bisher dem Menschen vorbehalten waren – etwa langfristige Problemlösung, Innovation oder Umweltanpassung. Gleichzeitig steigt die Herausforderung, solche Systeme kontrollierbar und sicher zu gestalten.
Allerdings könne gerade die kontinuierliche Interaktion mit der Umwelt zu mehr Sicherheit beitragen: Agenten erkennen unerwünschte Effekte und passen ihr Verhalten an. Belohnungsfunktionen lassen sich durch Nutzerfeedback iterativ verbessern. Und reale Prozesse – etwa medizinische Studien – setzten natürliche Grenzen für zu schnellen Fortschritt.
Sutton und Silver betonen, dass die technischen Voraussetzungen – Rechenleistung, Simulationsumgebungen, Algorithmen für verstärkendes Lernen – für solche KI-Systeme grundsätzlich vorhanden seien, auch wenn das Thema "Erfahrungsintelligenz" noch am Anfang steht. Jetzt benötige es die Bereitschaft der KI-Gemeinschaft, das Paradigma zu wechseln.
Die Erfahrung, so ihr Fazit, soll nicht länger Beiwerk sein, sondern Ausgangspunkt aller KI. Die nächste Welle der künstlichen Intelligenz werde durch Maschinen entstehen, die lernen, selbst zu denken, anstatt nur menschliche Gedanken zu wiederholen. Im folgenden Google-Deempind-Podcast erklärt David Silver die im Paper formulierten Ansätze im Detail.
Sprache allein reicht nicht – neue Architekturansätze im Fokus
Dass reine Sprachmodellierung nicht ausreicht, um verlässlich übermenschliche KI-Systeme zu entwickeln, hat sich zuletzt branchenweit als neuer Konsens durchgesetzt. Die Fähigkeit, sowohl komplexe als auch alltägliche Aufgaben mit gesundem Menschenverstand zu bewältigen, lässt sich offenbar nicht allein durch das Training auf Textdaten erreichen.
Prominente Stimmen der Branche schlagen ähnliche Richtungen ein. Ilya Sutskever, Mitgründer und ehemaliger Chefwissenschaftler von OpenAI, forscht mit seinem neuen Start-up "SSI" an alternativen Methoden für superintelligente Systeme. Sutskever sprach Ende 2024 von "Peak Data" und forderte die Entwicklung neuer Ansätze.
Auch Meta-KI-Chef Yann LeCun arbeitet an neuen Architekturkonzepten jenseits klassischer Sprachmodelle. OpenAI-CEO Sam Altman hatte bereits 2023 erklärt, dass Sprache allein nicht ausreiche, um fortgeschrittene KI zu entwickeln.
Ein vielversprechender Ansatz sind die zuvor erwähnten Weltmodelle – Systeme, die nicht nur Sprache, sondern auch sensorische und motorische Erfahrungen verarbeiten und intern abbilden können. Ziel ist es, KI-Systemen ein grundlegendes Verständnis von Kausalität, Raum, Zeit und Handlung zu vermitteln. Bislang blieben große Durchbrüche in diesem Bereich jedoch aus.
Eine große Herausforderung speziell beim Reinforcement Learning bleibt die Generalisierbarkeit der Methode, insbesondere für Aufgaben, bei denen es kein eindeutig richtiges oder falsches Ergebnis gibt. Beispielsweise sind die neuen Reasoning-Sprachmodelle in Mathematik wesentlich leistungsfähiger als herkömmliche Sprachmodelle, übertreffen diese aber nicht generell bei Wissens- oder kreativen Aufgaben.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.