Beliebter KI-Benchmark bevorzugt angeblich systematisch große Anbieter

Firmen wie OpenAI, Google oder Meta werben damit, wenn ihre KI-Modelle in der "LMArena" weit oben in der Rangliste landen. Jetzt erhebt eine Forschungsgruppe deutliche Kritik an der Aussagekraft des Benchmarks – die Arena-Organisatoren widersprechen.
Die LMarena zählt derzeit zu den wichtigsten öffentlichen Bewertungsplattformen für große Sprachmodelle. Nutzerinnen und Nutzer vergleichen dort die Antworten zweier KI-Modelle und stimmen ab, welche besser ist. Daraus ergibt sich eine Rangliste, die in der KI-Branche viel Aufmerksamkeit bekommt.
Doch laut einer neuen Studie wird die Rangliste durch intransparente Prozesse und systematische Bevorzugung großer Anbieter verzerrt. Die Ergebnisse stammen aus einer Analyse von mehr als 2 Millionen (laut Studie) bzw. 2,8 Millionen (laut Mitautorin Hooker auf LinkedIn) Modellvergleichen zwischen Januar 2024 und April 2025.
Private Tests und selektive Veröffentlichung verzerren Bewertungen
Laut der Untersuchung von Forschenden unter anderem von Cohere Labs, Princeton und MIT dürfen große Unternehmen wie Meta, Google oder OpenAI zahlreiche Testversionen ihrer Modelle heimlich ausprobieren. Nur die Version mit dem besten Ergebnis wird dann öffentlich auf der Rangliste gezeigt. Andere, schwächere Varianten verschwinden.
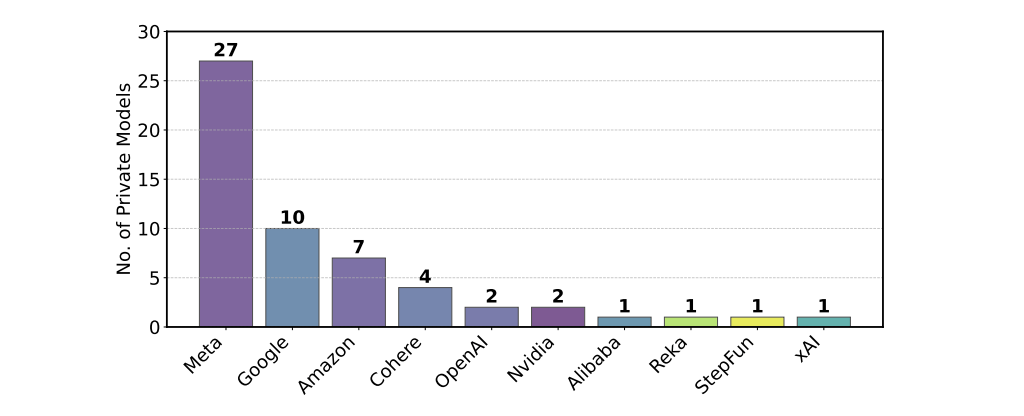
Das ermögliche gezieltes "Score-Gaming": Meta etwa testete vor der Veröffentlichung von Llama 4 mindestens 27 Varianten. Die Firma räumte ein nach reichlich Nutzerkritik ein, zwischenzeitlich einen für den Benchmark optimierten Chatbot ausgerollt zu haben. Das eigentliche KI-Modell "Maverick" ohne diese Optimierung performte dann im LMArena-Benchmark deutlich schlechter. Beide Modell-Varianten wurden von Endnutzern kritisch bewertet.
In eigenen Experimenten zeigen die Forschenden, dass solche Mehrfachtests die Bewertung stark beeinflussen können – auch wenn die Varianten sich kaum unterscheiden. Bereits bei zehn Tests kann ein Modell rund 100 Punkte mehr erzielen.
Mehr Daten für große Anbieter
Ein weiterer Kritikpunkt betrifft die Verteilung der Nutzerdaten. Die Anbieter erhalten via API-Schnittstellen Daten aus den "Kämpfen" zwischen den Modellen – also Eingaben von Nutzern und deren Bewertungen. Doch diese Daten sind ungleich verteilt: Modelle von OpenAI oder Google bekommen deutlich mehr Rückmeldungen als Modelle kleinerer Anbieter oder aus der Open-Source-Community.
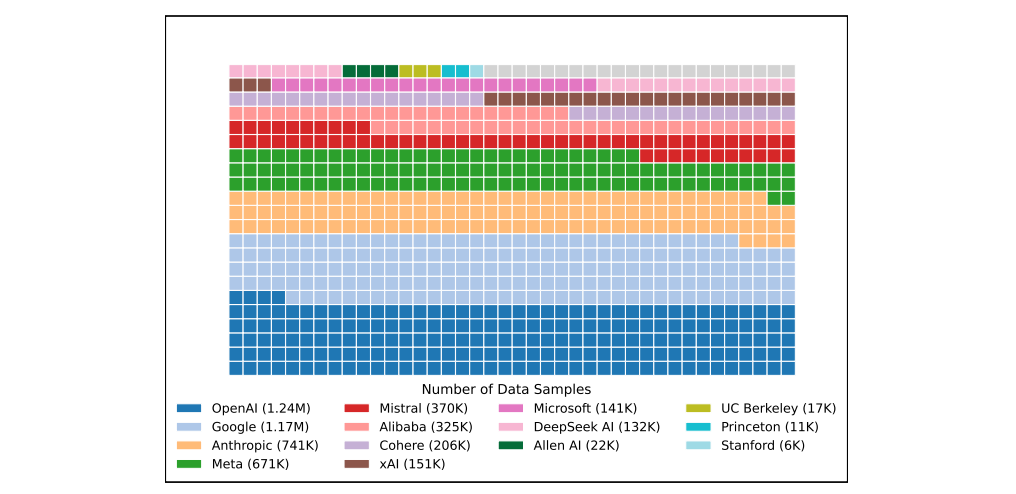
Das hat Folgen: In einem Experiment trainierten die Forschenden ein Modell mit verschiedenen Mengen an Arena-Daten. Je mehr Arena-Daten verwendet wurden, desto besser schnitt das Modell in der Arena ab – obwohl es auf anderen Tests sogar etwas schlechter wurde. Das deutet auf gezieltes "Anpassen" an die Arena hin, ohne dass die allgemeine Qualität steigt.
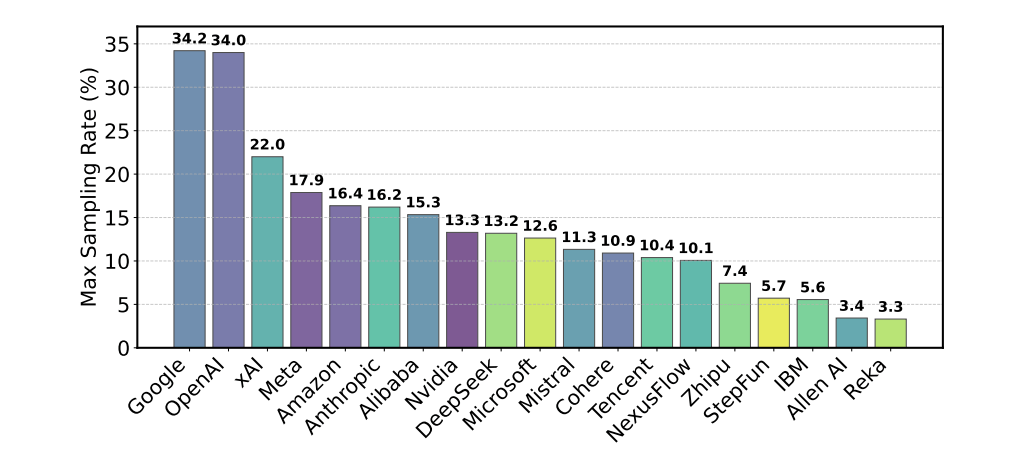
Die Forscher kritisieren auch, dass viele Modelle aus der Arena entfernt werden, ohne dass die Öffentlichkeit davon erfährt. Betroffen sind vor allem offene Modelle. Von 243 untersuchten Modellen wurden 205 stillschweigend deaktiviert. Nur 47 waren offiziell als "veraltet" gekennzeichnet. Wenn solche Modelle aus dem Vergleich verschwinden, kann das laut des Forschungsteams die Rangliste verfälschen – besonders wenn sie vorher wichtige Vergleichswerte geliefert haben.
Arena-Betreiber widersprechen den Vorwürfen
Die Betreiber der LMArena weisen die Vorwürfe der Studie zurück. In einer Stellungnahme bei X betonen sie, dass das Bewertungssystem auf Millionen echter Nutzerurteile basiert – und dass Vorabtests ein legitimes Mittel seien, um herauszufinden, welche Modellvariante den menschlichen Vorlieben am besten entspricht.
Dass manche Anbieter mehr Varianten testen als andere, sei deren eigene Entscheidung. Alle Anbieter seien eingeladen, ihre Modelle einzureichen. Man bemühe sich, alle Anfragen zu berücksichtigen. Die Unterstützung von Meta beim Test von Llama 4 sei kein Einzelfall – man habe dies auch für viele andere Anbieter getan.
Zudem betont das Arena-Team, dass nur die Punktzahl des letztlich veröffentlichten Modells in die Rangliste einfließe – nicht etwa die besten Ergebnisse aus internen Tests. Auch die Plattform selbst sei offen gestaltet: Der Quellcode sei öffentlich zugänglich, ebenso wie Millionen von Nutzerkonversationen.
Einige Kritikpunkte der Studie – etwa die Einführung gerechterer Verfahren zur Auswahl der Modelle, die Nutzern angezeigt werden – wolle man prüfen. Andere Aussagen hält man jedoch für sachlich falsch oder irreführend.
Besonders widerspricht das Team der Darstellung, Anbieter erhielten allein durch das Einreichen mehrerer Modellvarianten automatisch einen Vorteil. Die in der Studie durchgeführten Simulationen vermittelten ein verzerrtes Bild: Sie gingen davon aus, dass alle getesteten Varianten im Wesentlichen gleich stark seien und sich die beste nur durch Zufall abheben.
Forderungen nach Transparenz und Fairness
Die Autorinnen und Autoren der Studie fordern dennoch grundlegende Reformen. Alle getesteten Varianten sollen dauerhaft sichtbar bleiben – auch wenn sie schlecht abschneiden. Anbieter sollen nur noch eine begrenzte Zahl an Testversionen gleichzeitig einreichen dürfen. Die Häufigkeit, mit der ein Modell Nutzern gezeigt wird, soll fairer verteilt werden. Zudem müsse offen gelegt werden, welche Modelle entfernt wurden und warum.
Die LMArena sei ein wichtiger Teil der KI-Forschung, schreiben die Forschenden. Doch ihre zunehmende Bedeutung erfordere klare Regeln und faire Bedingungen. Sonst werde der Eindruck erweckt, dass Fortschritt bei KI nur durch geschicktes Taktieren auf der Rangliste entsteht – und nicht durch tatsächliche Verbesserungen.
Sara Hooker, Leiterin von Cohere Labs und Mitautorin der Studie, betont, wie wichtig wissenschaftlich belastbare Bewertungssysteme für den Fortschritt in der KI-Forschung sind. Die LMarena habe sich zu einem zentralen Maßstab entwickelt – umso wichtiger sei es, dass ihre Bewertungen fair und nachvollziehbar seien.
"Die Arena ist mächtig, und ihr übergroßer Einfluss erfordert wissenschaftliche Integrität", schreibt Hooker. Cohere ist ein im Vergleich zu den US-Konzernen kleinerer kanadischer Entwickler von KI-Modellen für Unternehmen, der sich durch den Benchmark benachteiligt fühlen dürfte, und hat die Forschung angeleitet.
Auch der frühere Tesla- und OpenAI-KI-Entwickler Andrej Karpathy äußert sich kritisch über den Arena-Benchmark. Ihm sei aufgefallen, dass ein Google-Modell (Gemini) zeitweise weit oben auf der Rangliste stand – in der Nutzung habe es ihn aber weniger überzeugt. Umgekehrt habe das Modell Claude 3.5 bei ihm im Alltag sehr gut funktioniert, auf der Arena-Rangliste aber schlecht abgeschnitten. Auch kleinere, wenig bekannte Modelle ohne viel Weltwissen hätten überraschend hohe Platzierungen erreicht.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.