KI-Chatbots werden in längeren Gesprächen dramatisch unzuverlässiger

Eine neue Studie von Microsoft und Salesforce zeigt: Selbst moderne KI-Sprachmodelle verlieren in mehrstufigen Gesprächen drastisch an Zuverlässigkeit, wenn Nutzer:innen ihre Anforderungen erst allmählich präzisieren. Die Leistung der Systeme brach dabei im Durchschnitt um 39 Prozent ein.
Um typische Mehrfachrunden-Gespräche nachzustellen, haben die Forschenden eine spezielle Simulationsmethode namens "Sharding" entwickelt. Diese zerlegt eine vollständige Aufgabe in mehrere Teilinformationen, die dem KI-Modell schrittweise mitgeteilt werden, angelehnt daran, wie Menschen ihre Anforderungen oft erst im Laufe eines Gesprächs konkretisieren.
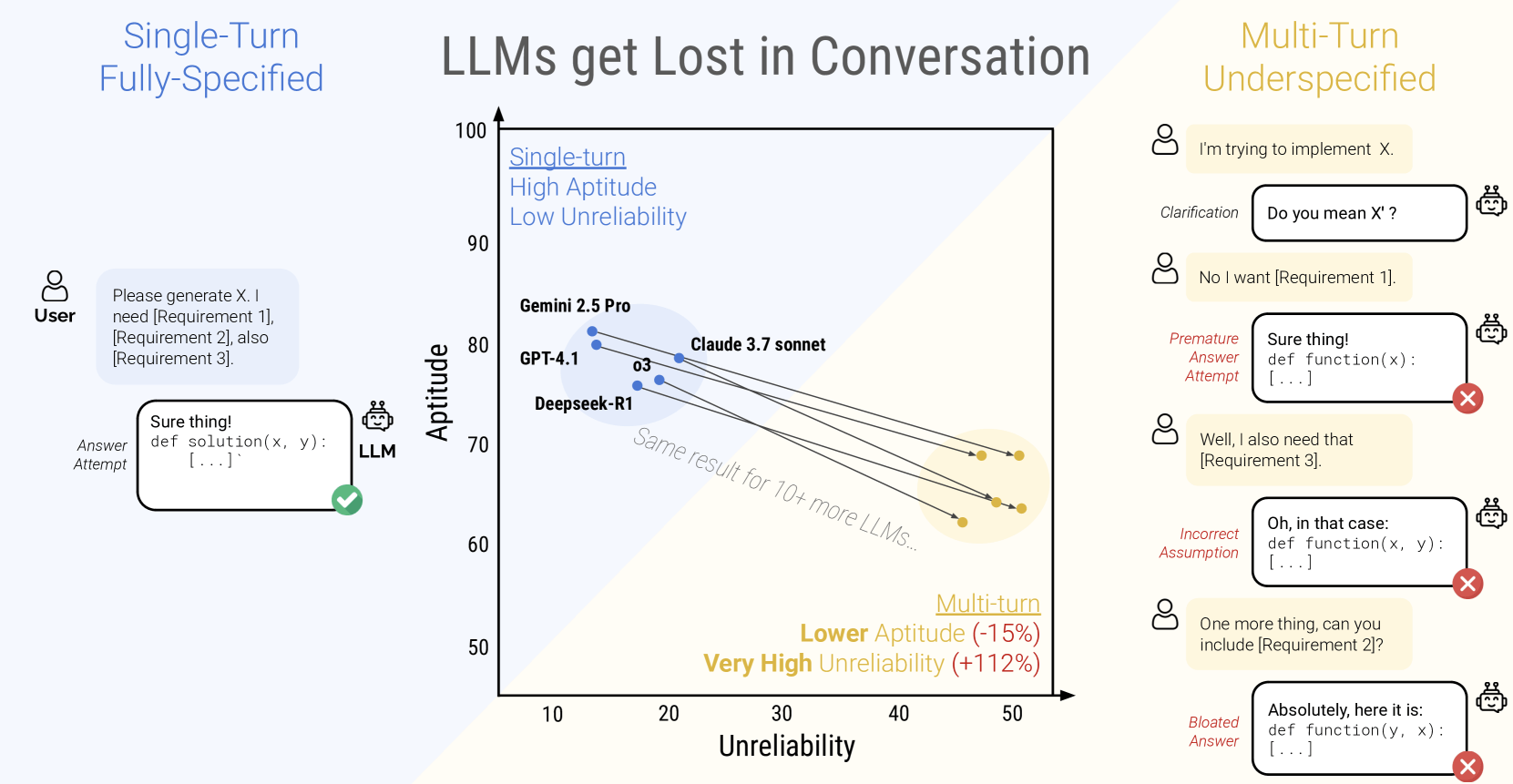
Wenn die KI-Modelle nicht von Anfang an alle Informationen enthielten, sank ihre Erfolgsquote von etwa 90 Prozent auf nur noch rund 51 Prozent. Dieser dramatische Leistungseinbruch betraf alle 15 getesteten Modelle, von kleinen Open-Source-Varianten wie Llama-3.1-8B bis zu kommerziellen Systemen wie GPT-4o.
Auch die fortschrittlichsten getesteten Modelle wie Claude 3.7 Sonnet, Gemini 2.5 Pro und GPT-4.1 schnitten in Mehrfachrunden-Gesprächen um 30-40 Prozent schlechter ab als in Einzelrunden. Zudem verdoppelte sich die Unzuverlässigkeit der Modelle im Durchschnitt, wobei die Ergebnisse deutlich stärker schwanken als bei Einzelrunden-Gesprächen.
Die Forschenden identifizierten vier zentrale Probleme:
- Die Modelle schlagen zu früh Lösungen vor, ohne alle Details abzuwarten.
- Sie stützen sich zu stark auf ihre früheren - oft fehlerhaften - Antwortversuche.
- Sie vernachlässigen Informationen aus der Mitte des Gesprächs.
- Sie formulieren zu ausführlich und treffen dadurch falsche Annahmen über fehlende Details.
Technische Verbesserungsversuche scheitern
Die Forscher:innen testeten verschiedene technische Anpassungen, um zuverlässigere Ergebnisse zu erzielen. Weder ein niedrigerer Temperaturwert, der die Zufälligkeit der Antworten steuert, noch das Wiederholen von Nutzerinformationen durch einen Agenten konnte die Leistungseinbrüche merklich abmildern.
Auch die Detailgenauigkeit der schrittweise übermittelten Informationen beeinflusste die Ergebnisse kaum. Als einzige effektive Methode erwies es sich, wenn die KI bereits zu Beginn des Gesprächs alle Informationen erhielt.
Die Forscher:innen haben die Verschlechterung in zwei Komponenten zerlegt: Die grundsätzliche Fähigkeit der Modelle (Aptitude) nahm nur leicht ab - im Durchschnitt um 16 Prozent. Die Unzuverlässigkeit (Unreliability) stieg dagegen drastisch um 112 Prozent.
In Einzelrunden-Gesprächen arbeiteten Modelle mit höherer Grundfähigkeit meist auch zuverlässiger. Bei Mehrfachrunden-Gesprächen zeigten jedoch alle getesteten Modelle eine ähnlich hohe Unzuverlässigkeit, unabhängig von ihrer Grundfähigkeit. Für eine bestimmte Aufgabe schwankte die Leistung im Durchschnitt um 50 Prozentpunkte zwischen dem besten und schlechtesten Durchlauf.
Was Nutzer und Entwickler tun können
Aus diesen Erkenntnissen haben die Forschenden zwei pragmatische Strategien abgeleitet. Bei Problemen sollten Nutzer:innen lieber ein neues Gespräch beginnen, statt ein festgefahrenes fortzusetzen. Am Ende eines Gesprächs sollten sie außerdem alle Anforderungen zusammenfassen lassen und diese gebündelt in einem neuen Dialog verwenden.
An die KI-Entwickler:innen appellieren die Forschenden, mehr Wert auf die Zuverlässigkeit in Mehrfachrunden-Gesprächen zu legen. Künftige Modelle müssen auch mit unvollständigen Anweisungen konstant gute Ergebnisse liefern - ohne spezielle Prompts oder Temperaturanpassungen.
Die Studie zeigt: Bei der KI-Entwicklung muss neben der reinen Leistungsfähigkeit auch die Zuverlässigkeit in den Fokus rücken. Diese Erkenntnis ist besonders wichtig für den praktischen Einsatz von KI-Assistenten, da mehrstufige Gespräche mit schrittweise präzisierten Anforderungen dort die Regel sind.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.