Google veröffentlicht Open-Source-Tool für KI-Modellvergleiche aller Anbieter
Mit LMEval stellt Google ein Framework zur standardisierten Evaluierung großer Sprach- und Multimodalmodelle vor. Es soll Benchmarks vereinfachen und Sicherheitsanalysen unterstützen.
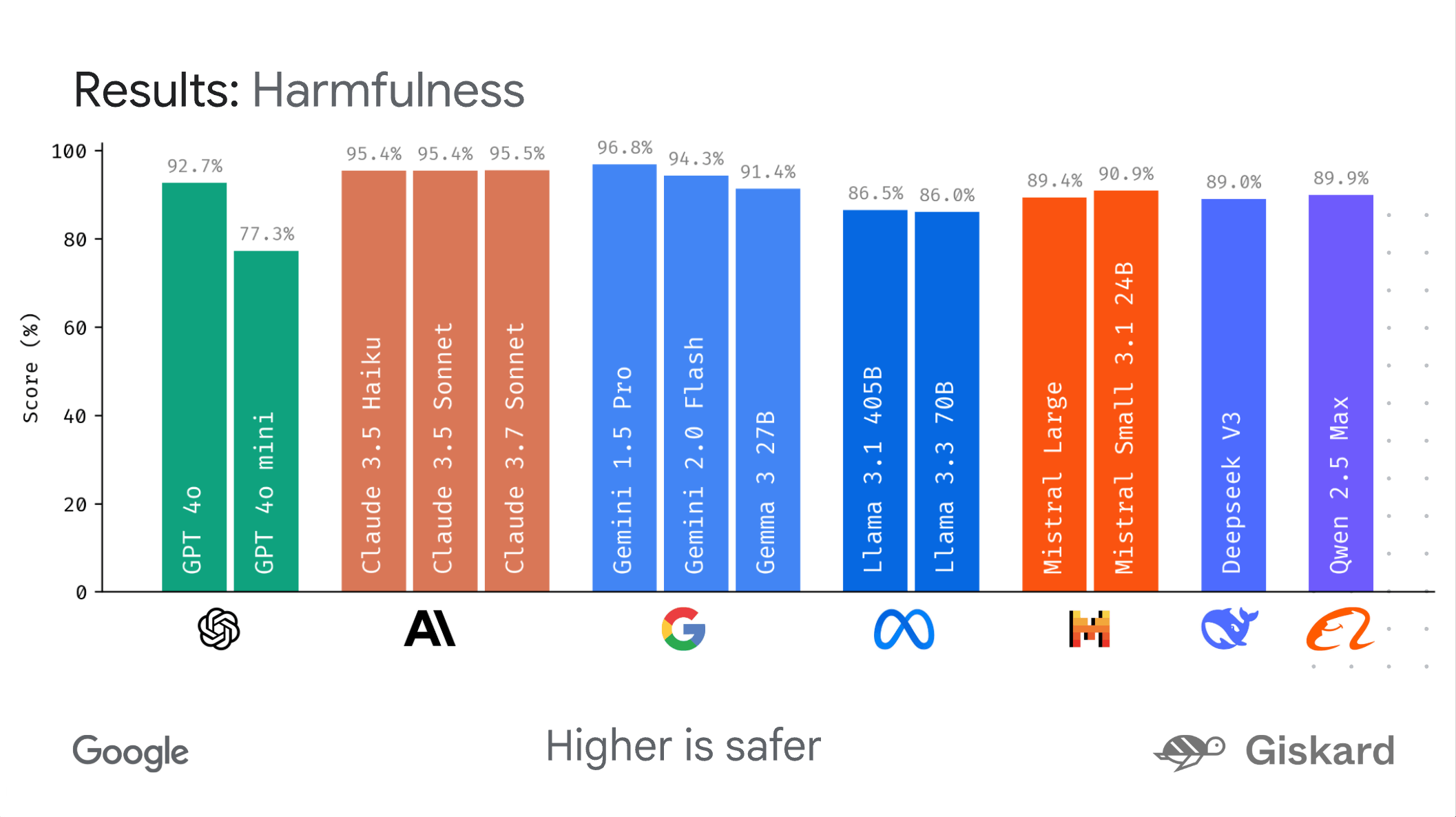
Google hat mit LMEval ein Open-Source-Framework veröffentlicht, das den Vergleich großer KI-Modelle unterschiedlicher Anbieter vereinfachen soll. Laut Google ermöglicht das Tool eine systematische und effiziente Evaluierung, etwa von Modellen wie GPT-4o, Claude 3.7 Sonnet, Gemini 2.0 Flash oder Llama-3.1-405B.
Bisher war es für Entwickler:innen und Forschende schwierig, neue Modelle schnell und zuverlässig zu bewerten. Unterschiedliche Schnittstellen, Datenformate und Benchmarkstrukturen erschwerten die Vergleichbarkeit. LMEval soll diesen Prozess vereinheitlichen: Ein einmal definierter Benchmark kann mit geringem Aufwand auf verschiedene Modelle angewendet werden – unabhängig vom Anbieter.
Multimodale Benchmarks und Sicherheitsmetriken
LMEval ist nicht auf Text beschränkt, sondern unterstützt auch Benchmarks mit Bild- und Codeinhalten. Neue Eingabeformate lassen sich laut Google leicht ergänzen. Die Bewertungsmetriken sind flexibel: Ja/Nein-Fragen, Multiple-Choice-Antworten und freie Textgenerierung sind möglich. Zudem erkennt LMEval sogenannte Punting-Strategien – Fälle, in denen Modelle bewusst ausweichend antworten, um problematische Aussagen zu vermeiden.
Die Ergebnisse werden in einer selbstverschlüsselnden SQLite-Datenbank gespeichert. Diese schützt die Daten vor unbeabsichtigtem Zugriff durch Suchmaschinen und bleibt dennoch lokal zugänglich.
Vergleichbarkeit ohne API-Hürden
LMEval nutzt das LiteLLM-Framework als technische Basis. Dieses abstrahiert die Schnittstellen verschiedener Modellanbieter und unterstützt unter anderem Schnittstellen von Google, OpenAI, Anthropic, Ollama und Hugging Face. Ein definierter Test kann dadurch ohne größere Anpassungen auf unterschiedlichen Plattformen ausgeführt werden.
Ein zentrales Merkmal ist die sogenannte inkrementelle Evaluierung: Statt bei jedem neuen Modell oder jeder neuen Fragestellung die gesamte Testsuite erneut auszuführen, führt LMEval nur die zusätzlich notwendigen Tests durch. Das spart Zeit und Rechenleistung. Zusätzlich kommt eine sogenannte Multithreaded-Engine zum Einsatz – eine Technik, bei der mehrere Rechenschritte gleichzeitig auf verschiedenen Prozessorkernen ausgeführt werden, um den Ablauf ebenfalls zu beschleunigen.
Dashboard ermöglicht detaillierte Analyse
Zur Auswertung der Ergebnisse bietet Google das Visualisierungstool LMEvalboard an. Es ermöglicht unter anderem Radarcharts, um die Leistung eines Modells in verschiedenen Kategorien grafisch darzustellen. Einzelne Modelle lassen sich im Detail analysieren.
Video: Google
LMEvalboard unterstützt auch sogenannte Drilldown-Ansichten: Nutzer:innen können von der Übersichtsebene gezielt in einzelne Aufgaben hineinzoomen, um konkrete Fehler eines Modells nachzuvollziehen. Ebenso lassen sich zwei Modelle direkt miteinander vergleichen, inklusive grafischer Darstellung der Unterschiede bei bestimmten Fragestellungen.
Der Quellcode sowie Beispiel-Notebooks stehen auf GitHub zur Verfügung.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.