KI-Modell lernt mathematisches Denken durch Snake und Tetris-ähnliche Spiele
Forschende haben einen überraschenden Weg entdeckt, wie multimodale KI-Modelle komplexe mathematische Probleme lösen können: durch das Spielen einfacher Arcade-Games statt durch Training mit mathematischen Daten.
Normalerweise werden Modelle mit großen Mengen domänenspezifischer Daten gefüttert, um Expertise in einem bestimmten Bereich zu entwickeln. Ein neues Paper von Wissenschaftler:innen der Rice University, Johns Hopkins University und Nvidia haben jedoch einen spielerischen Ansatz gefunden, der dieser gängigen Praxis im KI-Training widerspricht. Das Forschungsteam nennt ihr Konzept "Visual Game Learning" (ViGaL) und nutzt Qwen2.5-VL-7B als Basis.
Spiele fördern übertragbare Fähigkeiten
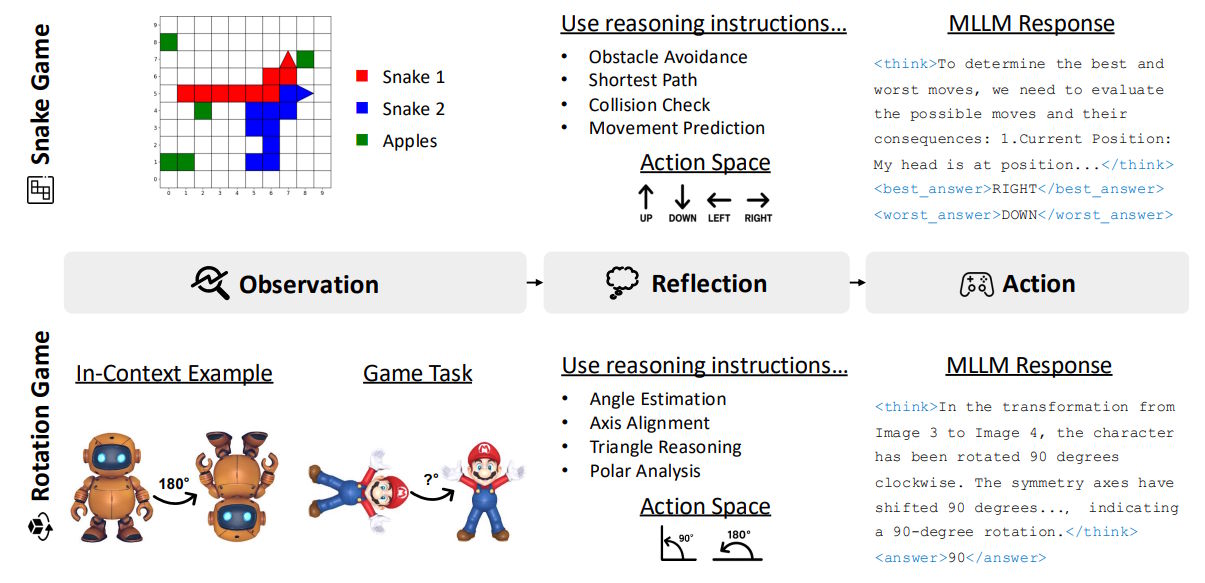
Der Ansatz basiert laut den Forschenden auf Erkenntnissen der Kognitionswissenschaft, die zeigen, dass Spiele übertragbare kognitive Fähigkeiten fördern. Für ihre Studie entwickelten die Wissenschaftler:innen zwei verschiedene Spielumgebungen angelehnt an Snake und Tetris, die jeweils unterschiedliche Aspekte des Denkens trainieren sollten.
Das Snake-Spiel wurde auf einem 10x10-Gitter implementiert, bei dem zwei Schlangen um Äpfel konkurrieren. Das Tetris-ähnliche Rotationsspiel präsentierte dem Modell 3D-Objekte in ursprünglicher und um 90 oder 180 Grad rotierter Ansicht.
Die Forschenden generierten dafür je 36.000 Trainingsbeispiele mit kontrollierbaren Schwierigkeitsgraden und verwendeten Hunyuan3D für die 3D-Objektgenerierung. Snake verbesserte die Leistung bei 2D-Koordinaten- und Ausdrucksproblemen, während Rotation die Winkel- und Längenberechnung stärkte.
Snake-Training statt Mathe-Daten
Das kombinierte Training auf Snake- und Rotationsproblemen brachte das Basismodell im Vergleich zu MM-Eureka-Qwen-7B, das explizit auf mathematischen Datensätzen trainiert wurde, mit 50,6 Prozent gegenüber 50,1 Prozent in mathematischen Benchmarks auf ein leicht höheres Niveau.
Bei geometrischen Problemen verdoppelte sich die Leistung hingegen. Das liegt mit daran, dass MM-Eureka bei einem der Geometrie-Benchmarks (Geo3K) auffällig schlecht wegkommt. Im Vergleich zu anderen Spezial-Modellen ist der Abstand kleiner, aber ebenfalls vorhanden.
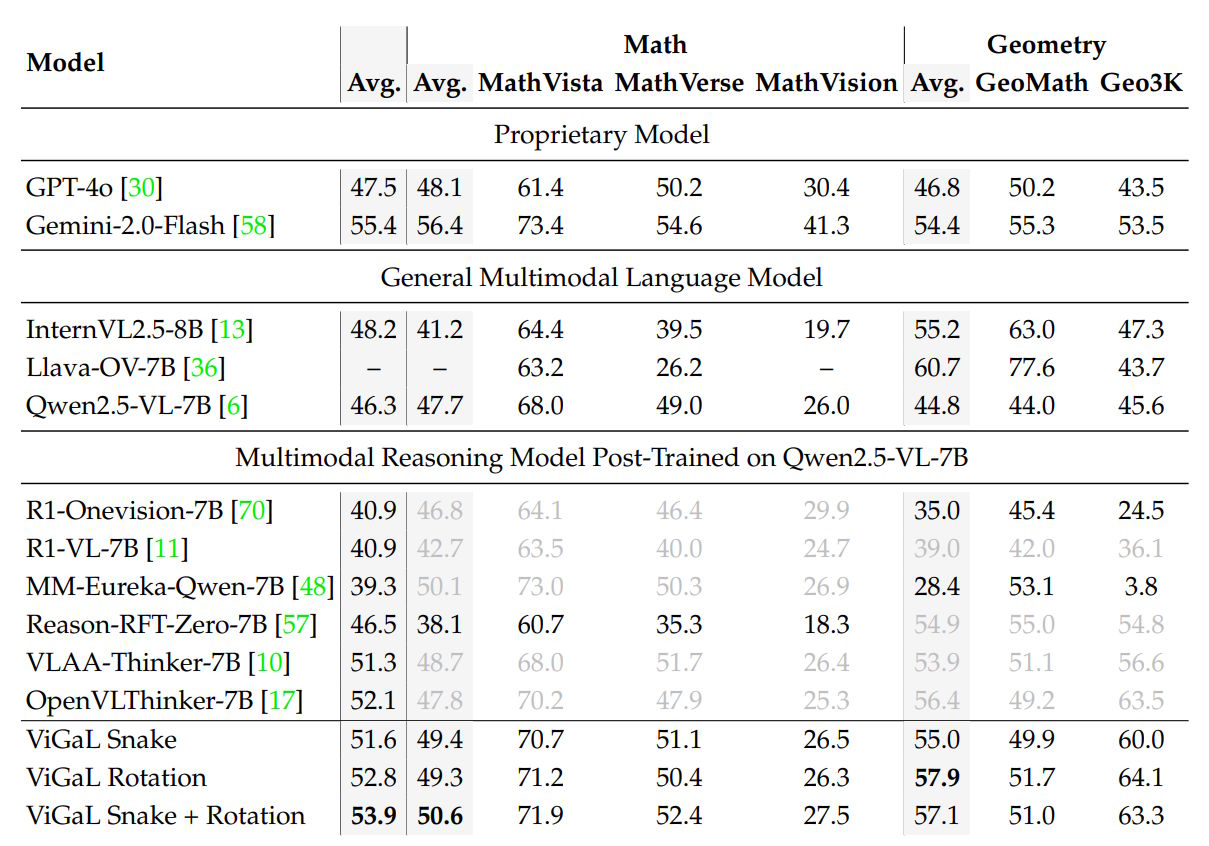
Auch gegenüber proprietären Systemen schnitt ViGaL gut ab: Es erreichte 53,9 Prozent durchschnittliche Genauigkeit über alle Benchmarks hinweg und lag damit über GPT-4o (47,5 Prozent), aber knapp unter Gemini 2.0 Flash (55,4 Prozent).
Bei komplexeren, mathematischen Aufgaben schlug das kleine nachtrainierte Modell mit durchschnittlichen 64,7 Prozent das wesentlich größere GPT-4o (55,9 Prozent) noch deutlicher. Bei allgemeiner angelegten Tests lag das ViGaL-Modell jedoch knapp unter dem Basismodell und einige Prozentpunkte hinter GPT-4o.

Abschließend prüften die Forschenden die Fähigkeiten von ViGaL auf Atari-Spielen, die sich erheblich von den Trainingsspielen unterscheiden. Hier erreichte ViGaL fast doppelt so hohe Punktzahlen wie das Basismodell.
Verstärkungslernen deutlich besser als Finetuning
Spezielle Anweisungen zum schrittweisen Denken erwiesen sich als entscheidend: Mathematische Denkanleitungen wie "finde den nächsten Apfel durch Berechnung von Manhattan-Distanzen" für Snake und räumliche Anweisungen wie "identifiziere wichtige Symmetrieachsen" für Rotation verbesserten die Leistung um 1,9 Prozentpunkte.
Ein weiterer Schlüsselaspekt war das Design der Belohnungsfunktion: Das Modell musste sowohl den besten als auch den schlechtesten Zug identifizieren. Diese kontrastive Entscheidungsfindung brachte weitere 1,8 Prozentpunkte Verbesserung. Die Kontrolle der Spielschwierigkeit - bei Snake über die Schlangenlänge zwischen 1 und 5 Segmenten - stabilisierte das Training zusätzlich.
Insgesamt steigerte Belohnungslernen die Leistung um 12,3 Prozent, während überwachtes Training (Supervised Finetuning) mit denselben Daten sie um 1,9 Prozent verschlechterte. Die Forschenden zeigten auch, dass sich der Ansatz begrenzt skalieren lässt: Eine Verdopplung der Trainingsdaten verbesserte die Ergebnisse um weitere 1,3 Prozentpunkte.
Neues Paradigma für KI-Training?
Die Ergebnisse deuten laut den Forschenden auf ein neues Training-Paradigma hin: Statt teure, von Menschen annotierte Datensätze zu benötigen, könnten synthetische Spiele als skalierbare Trainingsaufgaben dienen, die generalisierbare Denkfähigkeiten freisetzen. Zukünftige Arbeiten könnten eine breitere Palette von spielbasierten Lernansätzen für robuste KI erkunden.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.