Forschende haben womöglich eine Leiter für die "Datenmauer" gefunden

Eine MIT-Forschungsgruppe hat ein Framework namens SEAL entwickelt, mit dem LLMs eigenständig synthetische Trainingsdaten generieren und sich damit selbst optimieren können.
SEAL basiert auf einem zweistufigen Verfahren. In der ersten Stufe lernt das Modell durch Belohnungslernen, effektive "Selbstbearbeitungen" zu generieren. Diese bestehen aus Anweisungen in natürlicher Sprache, die sowohl neue Trainingsdaten als auch Optimierungsparameter festlegen. In der zweiten Stufe wendet das System diese Anweisungen an und aktualisiert seine eigenen Gewichte durch maschinelle Lernverfahren.

Das System nutzt eine spezielle Trainingsmethode namens ReST^EM-Algorithmus. Dieser funktioniert wie ein Filter, der nur erfolgreiche Selbstbearbeitungen zur Verstärkung auswählt. Konkret sammelt der Algorithmus verschiedene Selbstbearbeitungen, testet deren Wirksamkeit und trainiert das Modell dann nur auf jenen Varianten, die tatsächlich zu besseren Ergebnissen führen. Für effiziente Updates verwendet SEAL Low-Rank Adapters (LoRA), die leichtgewichtige Anpassungen ermöglichen, ohne das gesamte Modell neu zu trainieren.
Die Wissenschaftler:innen testeten SEAL in zwei verschiedenen Szenarien. Bei der Integration neuen Wissens verwendeten sie einen Textverständnis-Test mit Qwen2.5-7B. Das Modell generierte logische Schlussfolgerungen aus gegebenen Textabschnitten und trainierte dann auf diesen selbst erstellten Inhalten.

SEAL erreichte hier eine Genauigkeit von 47 Prozent gegenüber 33,5 Prozent bei der Vergleichsmethode. Die Qualität der selbst generierten Daten übertraf sogar die von OpenAIs GPT-4.1, obwohl das verwendete Modell deutlich kleiner war.
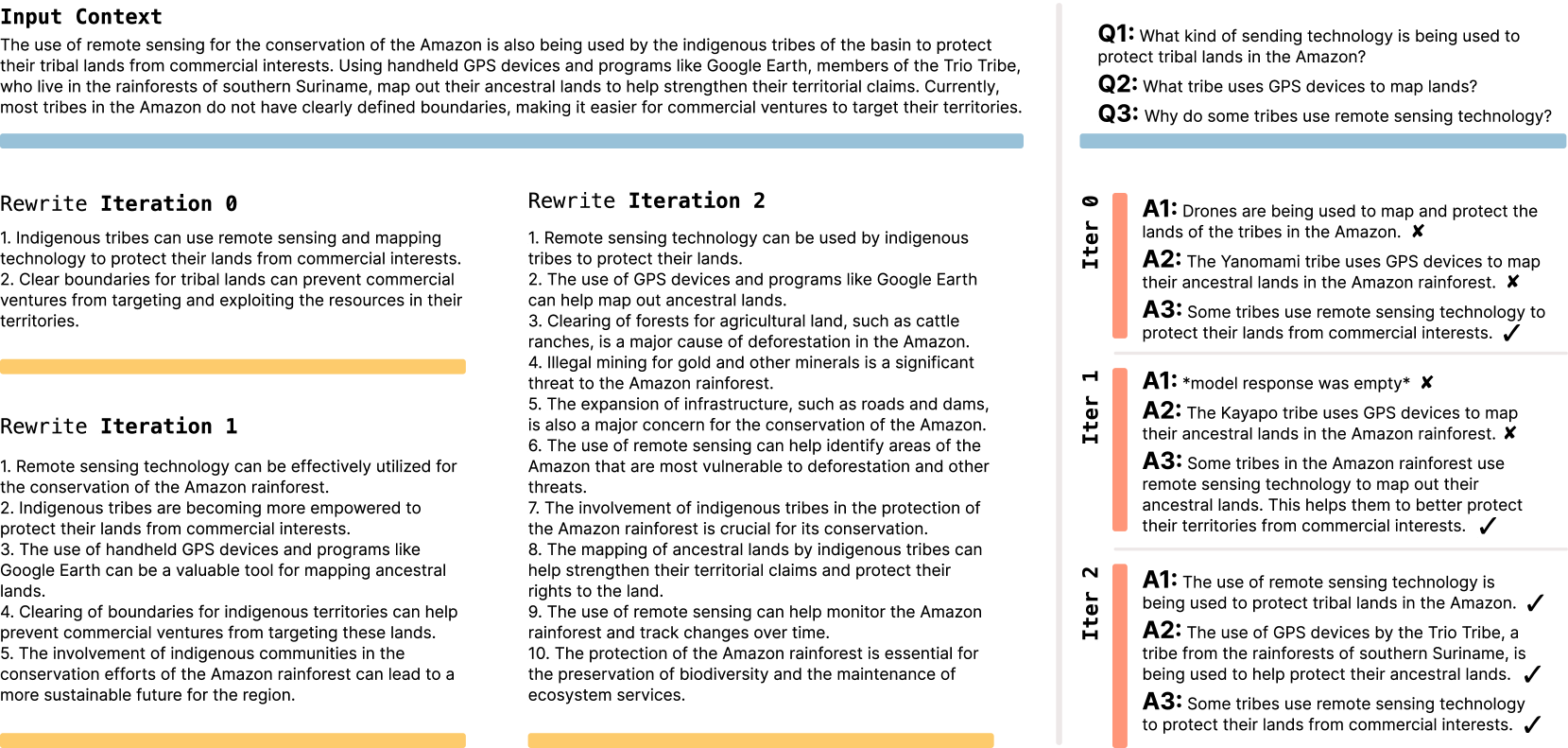
Im zweiten Test untersuchten die Forschenden Few-Shot Prompting, also Prompts mit Lösungsbeispielen, anhand eines vereinfachten Reasoning-Tests mit Llama 3.2-1B. Hier wählte das Modell automatisch verschiedene Datenverarbeitungstechniken und Trainingsparameter aus einem vordefinierten Werkzeugsatz aus. SEAL erreichte eine Erfolgsrate von 72,5 Prozent verglichen mit 20 Prozent ohne vorheriges Training.
"Katastrophales Vergessen" bleibt ein Problem
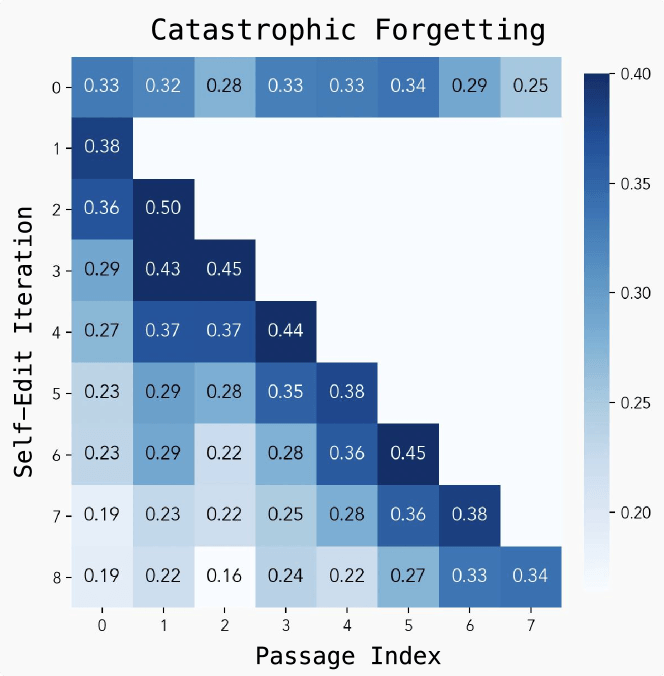
Trotz der vielversprechenden Ergebnisse identifizierten die Forschenden mehrere Einschränkungen. Das größte Problem ist das sogenannte "Katastrophale Vergessen". Die Leistung bei früheren Aufgaben nimmt ab, wenn neue Updates hinzugefügt werden. Zudem verursacht das Training erheblichen Rechenaufwand, da jede Bewertung einer Selbstbearbeitung etwa 30 bis 45 Sekunden benötigt.
Antwort auf die drohende Datenmauer
Die Wissenschaftler:innen sehen in SEAL einen wichtigen Schritt zur Bewältigung der prognostizierten "Datenmauer". Damit bezeichnen sie den Punkt, an dem alle verfügbaren menschlich generierten Textdaten für das Training von Spitzenmodellen erschöpft sein werden – in diesem Zusammenhang warnten Forschende bereits vor dem "Modellkollaps". Das Framework könnte den Weg für kontinuierliches Lernen und autonome KI-Systeme ebnen, die sich dynamisch an verändernde Ziele anpassen.
Vielversprechend ist die Aussicht auf selbstlernende Systeme, die neue Informationen wie wissenschaftliche Arbeiten aufnehmen und große Mengen an Erklärungen und Implikationen für sich selbst generieren können. Diese iterative Schleife aus Selbstausdruck und Selbstverfeinerung könnte es Modellen ermöglichen, sich auch bei seltenen oder unterrepräsentierten Themen kontinuierlich zu verbessern.
Den Quellcode haben die Forschenden auf GitHub zur Verfügung gestellt.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.