Im KI-Benchmark ARC-AGI-3 zeigen Menschen, was Maschinen noch fehlt
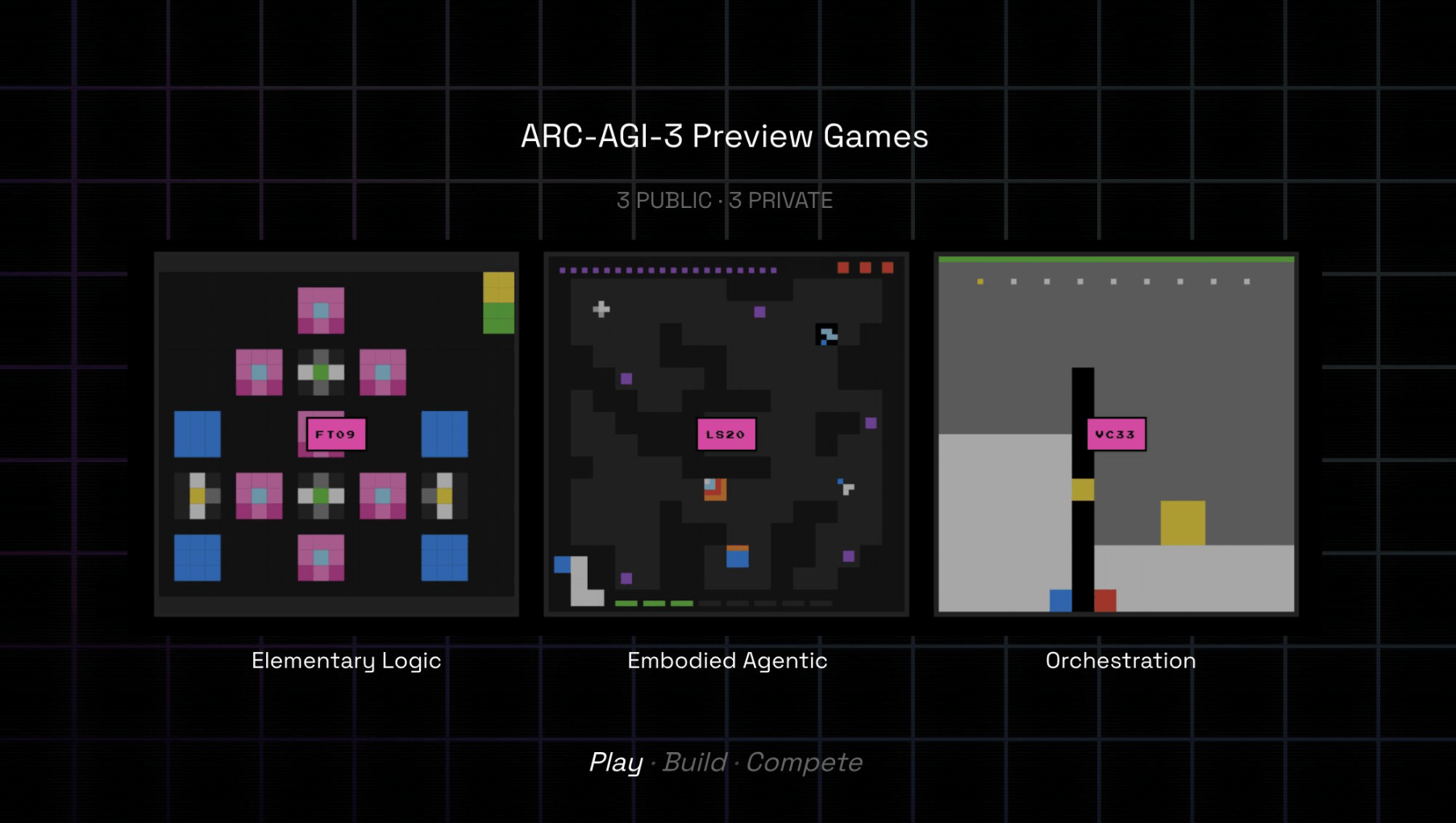
ARC-AGI-3 soll messen, wie gut KI-Systeme unbekannte Aufgaben verstehen und lösen können. Menschen kommen mit den Tests problemlos zurecht, die KI scheitert bisher vollständig.
Der KI-Forscher François Chollet und sein Team haben mit ARC-AGI-3 eine neue Version ihres Benchmarks zur Messung allgemeiner Intelligenz vorgestellt.
Laut Chollet soll ARC-AGI-3 die Fähigkeit von KI-Systemen messen, in völlig unbekannten Situationen selbstständig zu lernen – ohne Vorwissen, ohne Anleitung. Die Aufgaben basieren ausschließlich auf sogenannten "Core Knowledge Priors", also grundlegenden kognitiven Fähigkeiten wie Objektpermanenz oder Kausalität. Sprachliches Wissen, Trivia oder kulturelle Symbole sind ausgeschlossen.
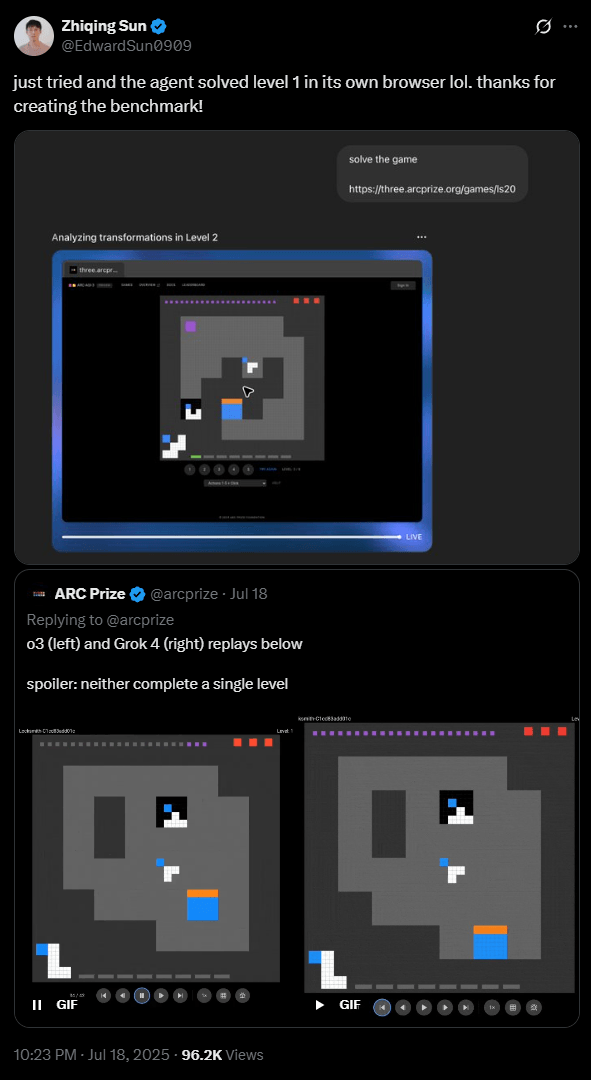
Die "Developer Preview" enthält drei interaktive Testspiele, die laut den Entwicklern von Menschen in wenigen Minuten gelöst werden können – aktuelle KI-Systeme erzielen jedoch durchweg null Punkte. OpenAI-Forscher Zhiqing Sun behauptet allerdings auf X, dass der neue ChatGPT Agent das erste Spiel bereits lösen kann.
Interaktive Spiele statt statischer Benchmarks
Die zentrale Neuerung gegenüber früheren ARC-Versionen ist der interaktive Aufbau: Statt statischer Aufgaben enthält ARC-AGI-3 neuartige Minispiele in einer sogenannten Grid-Welt. Um zu gewinnen, müssen KI-Agenten die Spielmechanik selbst entdecken, Ziele erkennen und durch Versuch und Irrtum lernen, wie sie diese erreichen können.
Die Entwickler vergleichen dieses Vorgehen mit menschlichem Lernen: Menschen erschließen sich neue Umgebungen durch Exploration, Planung und Anpassung – Fähigkeiten, die bisherige KI-Systeme kaum zeigen. "Solange wir diese Lücke haben, haben wir keine allgemeine KI", heißt es in der Projektbeschreibung auf arcprize.org.
Begleitend zur Vorschauversion startet ein Sprint-Wettbewerb mit einem Preisgeld von 10.000 US-Dollar, gesponsert von HuggingFace. Innerhalb von vier Wochen sollen Teilnehmende den bestperformenden Agenten entwickeln und einreichen. Die Teilnahme erfolgt über die bereitgestellte API.
Der vollständige Benchmark soll bis Anfang 2026 rund hundert verschiedene Spiele umfassen, aufgeteilt in öffentliche und private Testsets. Weitere Informationen zum Benchmark, zur Teilnahme und zur API finden sich auf der offiziellen Projektseite arcprize.org.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.