Google veröffentlicht ein neues KI-Bildmodell mit deutlich verbesserter Bildbearbeitung

Google Deepmind integriert ein neues Bildbearbeitungsmodell in die Gemini-App. Die Software verändert Bilder auf Wunsch radikal und sorgt dennoch dafür, dass Personen und Tiere erkennbar bleiben.
Google hat das neue Bild- und Editiermodell "Gemini 2.5 Flash Image Generation" veröffentlicht. Es baut auf der bisherigen nativen Gemini-Sprachmodell-Bildgenerierung auf und verhält sich bei der Prompt-Umsetzung daher ziemlich genau, ähnlich wie GPT-4o von ChatGPT, gerade im Vergleich zu reinen Bildmodellen mit geringerem Textverständnis.
Ein zentrales Merkmal von Gemini 2.5 Flash ist die sogenannte Charakterkonsistenz: Nutzer können eine Person, ein Objekt oder ein Tier über verschiedene Bilder hinweg visuell konsistent darstellen – etwa in unterschiedlichen Posen, Umgebungen oder Lichtverhältnissen.

Damit lassen sich etwa Bildreihen oder Produktabbildungen aus unterschiedlichen Perspektiven erstellen. Auch für einheitliche Markenbilder, Produktkataloge oder Mitarbeiterausweise ist das Modell laut Google einsetzbar.
Laut Google übertrifft die neue Gemini-Bildgenerierung bei verschiedenen Bildbearbeitungsaufgaben bisher verfügbare vergleichbare Bildsysteme teils deutlich.
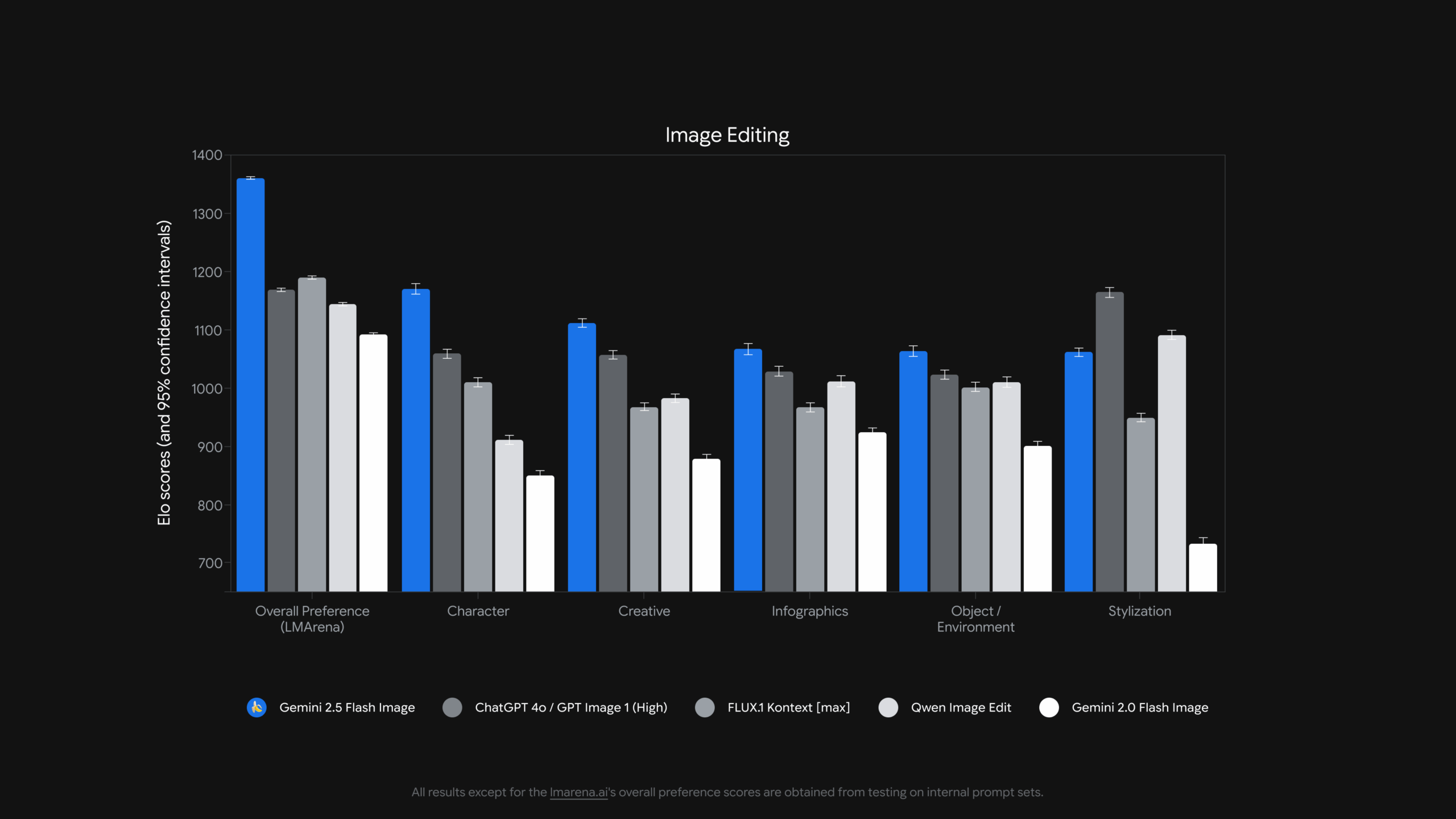
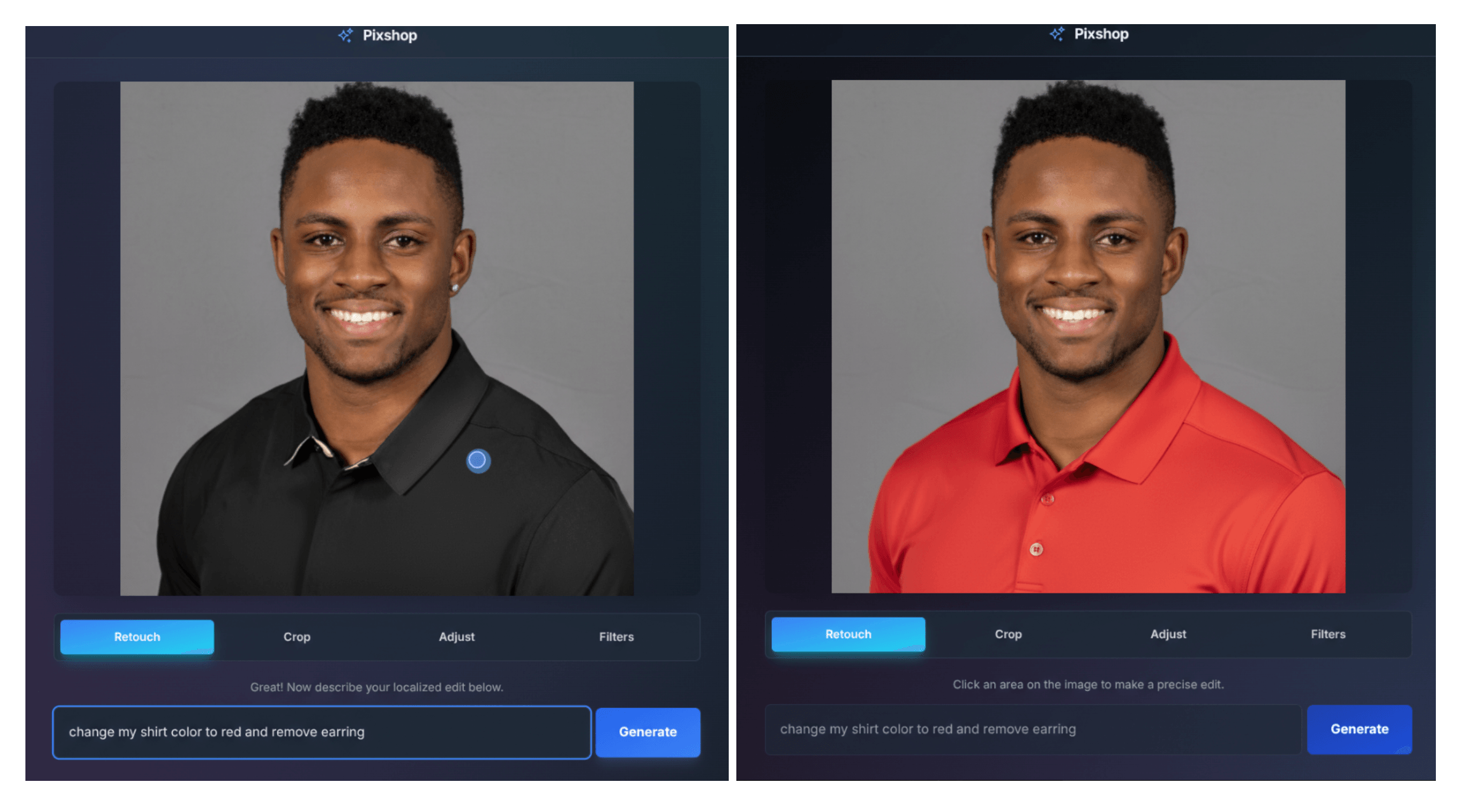
Zudem ermöglicht das Modell präzise, lokal begrenzte Bearbeitungen per Texteingabe: Nutzer können ohne manuelle Auswahlwerkzeuge mit einem einfachen Prompt etwa den Hintergrund eines Fotos unscharf machen, Flecken entfernen, Farben hinzufügen oder komplette Objekte löschen. Eine weitere Vorlagen-App namens "PixShop" zeigt diese Bearbeitungsfunktionen mit UI- und Prompt-Steuerung.
Bildkomposition, Stiltransfer und Weltwissen
Gemini 2.5 Flash erlaubt es, bis zu drei Bilder miteinander zu verschmelzen. Dabei können Nutzer etwa ein Produktfoto und ein Raumfoto kombinieren, um fotorealistische Interior-Visualisierungen zu generieren. Auch komplexe Kompositionen mit mehreren Elementen lassen sich mit nur einem Prompt erzeugen. Für diese "Multi-Image Fusion" stellt Google ein interaktives Canvas-Tool zur Verfügung.

Darüber hinaus beherrscht das Modell stilistische Transformationen: Farbgebung, Textur oder Design eines Objekts lassen sich auf ein anderes übertragen, wobei dessen Form und Details erhalten bleiben. Ein Kleid im Schmetterlingsmuster oder Gummistiefel mit Blumenstruktur sind typische Anwendungsbeispiele.
Eine weitere Fähigkeit ist das "Real-World Reasoning": Das Modell kann einfache Kausalzusammenhänge erfassen und visuell darstellen. In einem Beispiel erzeugt es zunächst ein Bild eines Ballons, der auf einen Kaktus zufliegt und anschließend ein Folgebild, das die logische Konsequenz zeigt.

Diese semantischen Fähigkeiten basieren auf dem Weltwissen von Gemini 2.5. Google veranschaulicht das anhand einer Mal-App, die Text-Instruktionen umsetzen kann.
Für Endverbraucher und Entwickler verfügbar
Die neue Funktion ist ab sofort innerhalb der Gemini-App verfügbar. Dafür darf man allerdings nicht das Bildmodell "Imagen" in der Bildleiste aktivieren, sondern muss bei den KI-Bildmodellen oben links auf das "Flash"-Sprachmodell wechseln. Das ist zunächst etwas verwirrend, aber insofern logisch, als es sich hier um eine native Bild-Editier-Funktion des Sprachmodells handelt.
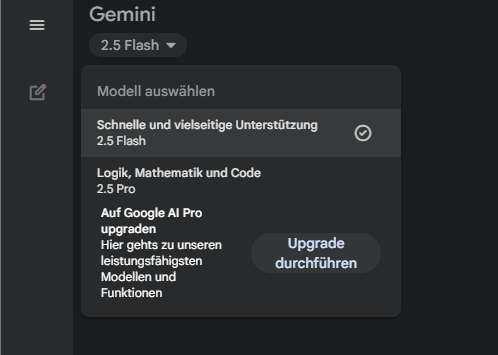
Hat man das Sprachmodell ausgewählt, kann man dem System ein Bild füttern und Anweisungen geben, es zu verändern. Alle in der Gemini-App bearbeiteten oder generierten Bilder enthalten ein sichtbares Wasserzeichen sowie das digitale Wasserzeichen SynthID, das unsichtbar im Bild verankert ist.
Gemini 2.5 Flash Image ist zudem als Vorschauversion über die Gemini API, Google AI Studio und Vertex AI verfügbar. Die Nutzung kostet 30 US-Dollar pro einer Million Output-Token. Ein Bild verbraucht im Schnitt 1.290 Token, was rund 0,039 US-Dollar pro Bild entspricht; derselbe Preis wie beim Vorgängermodell Gemini 2.0 Flash Image.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.