ChatGPTs API und Web-Version nutzen laut Studie völlig verschiedene Quellen

Eine aktuelle Studie zeigt systematische Unterschiede bei ChatGPTs Nachrichtenempfehlungen. Während das Web-Interface Outlets mit Lizenzverträgen bevorzugt, neigt die API zu enzyklopädischen Quellen.
Forschende der Universität Hamburg und des Leibniz-Instituts für Medienforschung haben ChatGPT als Recommender-System für Nachrichten untersucht und dabei erhebliche Unterschiede zwischen verschiedenen Zugangsarten entdeckt. Über fünf Wochen analysierten die Wissenschaftler:innen 24.013 Antworten auf nachrichtenbezogene Anfragen im deutschen Sprachraum.
Die Studie verglich systematisch, welche Nachrichtenquellen ChatGPT bei aktuellen Ereignissen heranzieht. Dabei testeten die Forschenden sowohl normale Anfragen (Regular) als auch solche, die explizit nach einer breiten Quellenauswahl verlangten (Diverse).
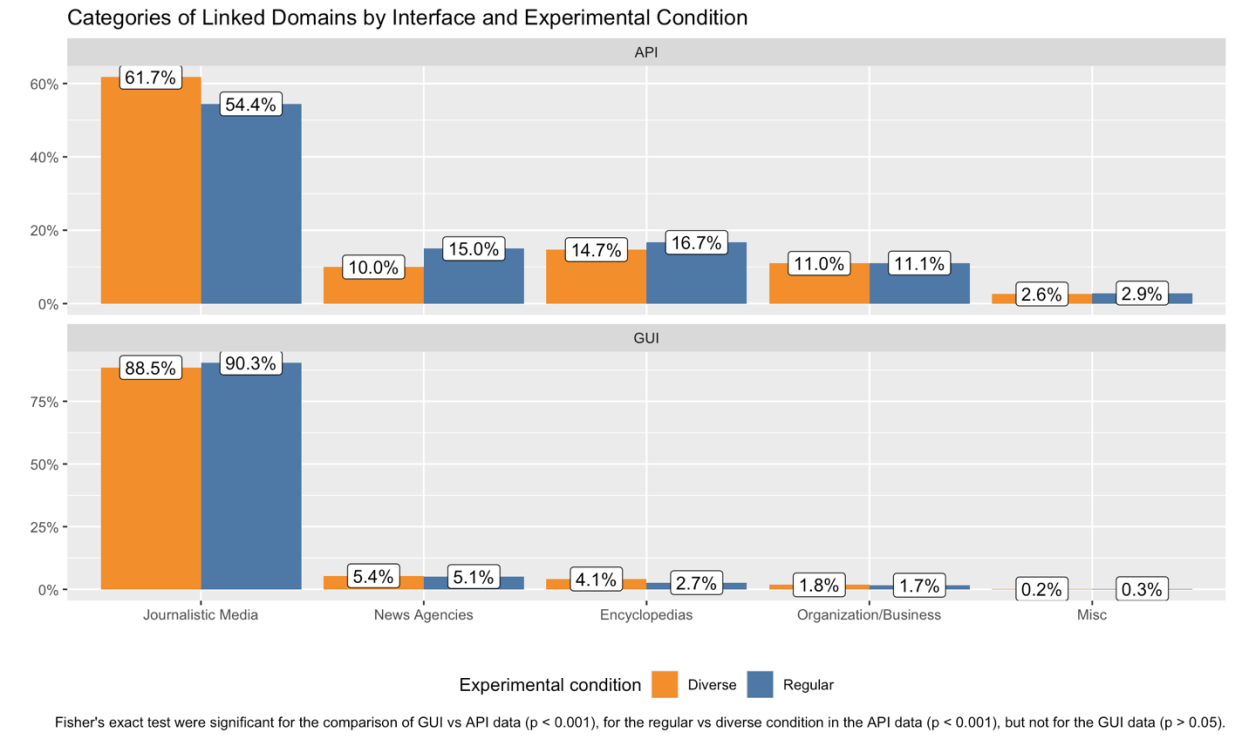
Springer-Outlets dominieren Web-Interface, API bevorzugt Wikipedia
Die Ergebnisse zeigen markante Unterschiede zwischen Web-Interface und API-Schnittstelle. Laut der Studie sind Outlets des OpenAI-Lizenzpartners Axel Springer im Web-Interface deutlich prominenter vertreten. Die Springer-Medien welt.de und bild.de machten dort etwa 13 Prozent aller Quellenverweise aus, während sie über die API nur rund 2 Prozent erreichten.
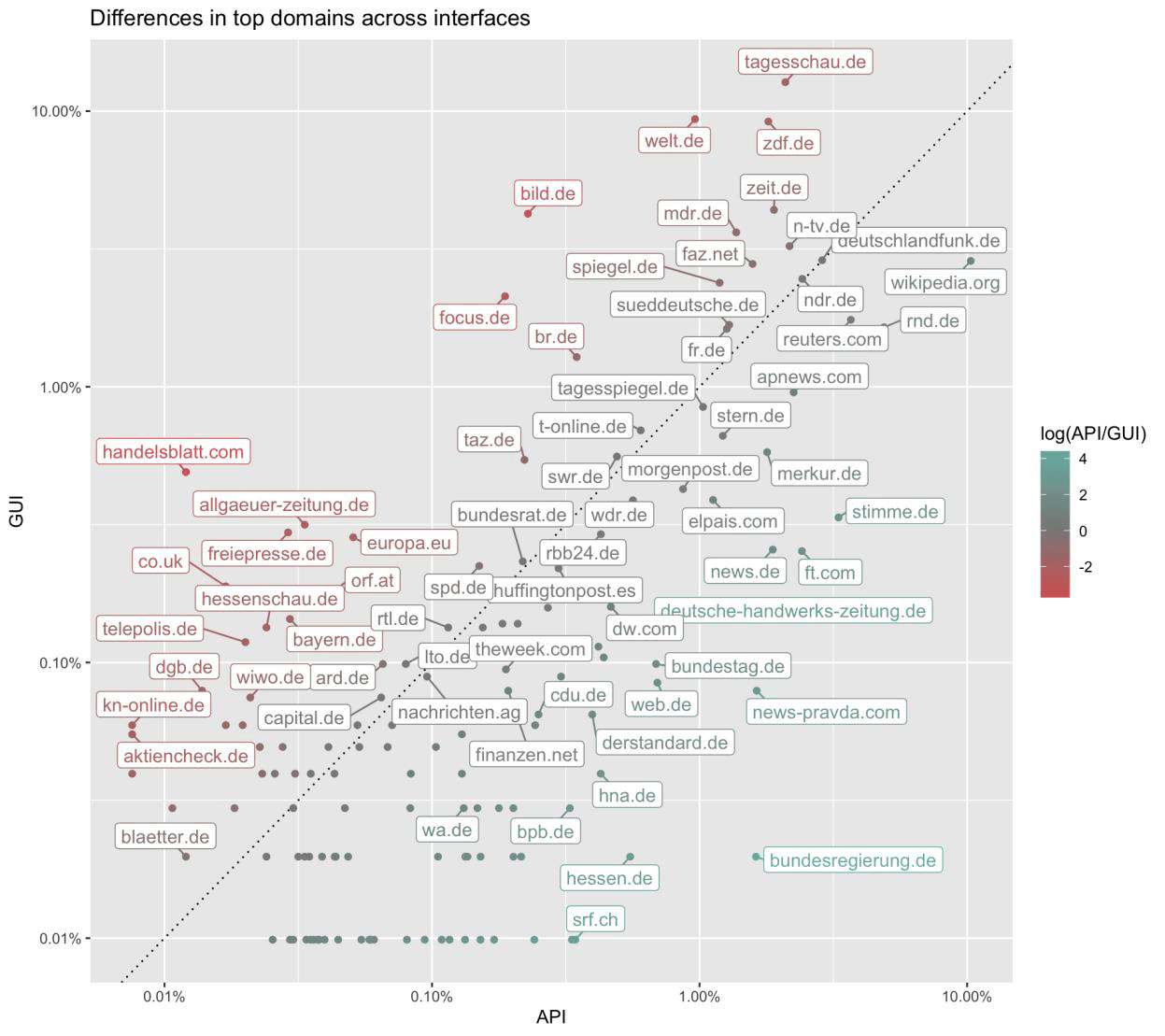
Im Web-Interface belegten welt.de Rang 1 und bild.de Rang 5 der am häufigsten zitierten Quellen. Über die API landeten dieselben Outlets nur auf den Rängen 61 und 158. Die Forschenden bestätigten diese Unterschiede als statistisch signifikant.
Die API zeigte hingegen eine Präferenz für enzyklopädische Quellen wie Wikipedia, die 14,79 Prozent aller Referenzen ausmachte, sowie für kleinere lokale Medien. Unbekannte Outlets wie die deutsche-handwerks-zeitung.de erreichten über die API überraschend hohe Platzierungen, obwohl sie im deutschen Nachrichtenmarkt kaum eine Rolle spielen.
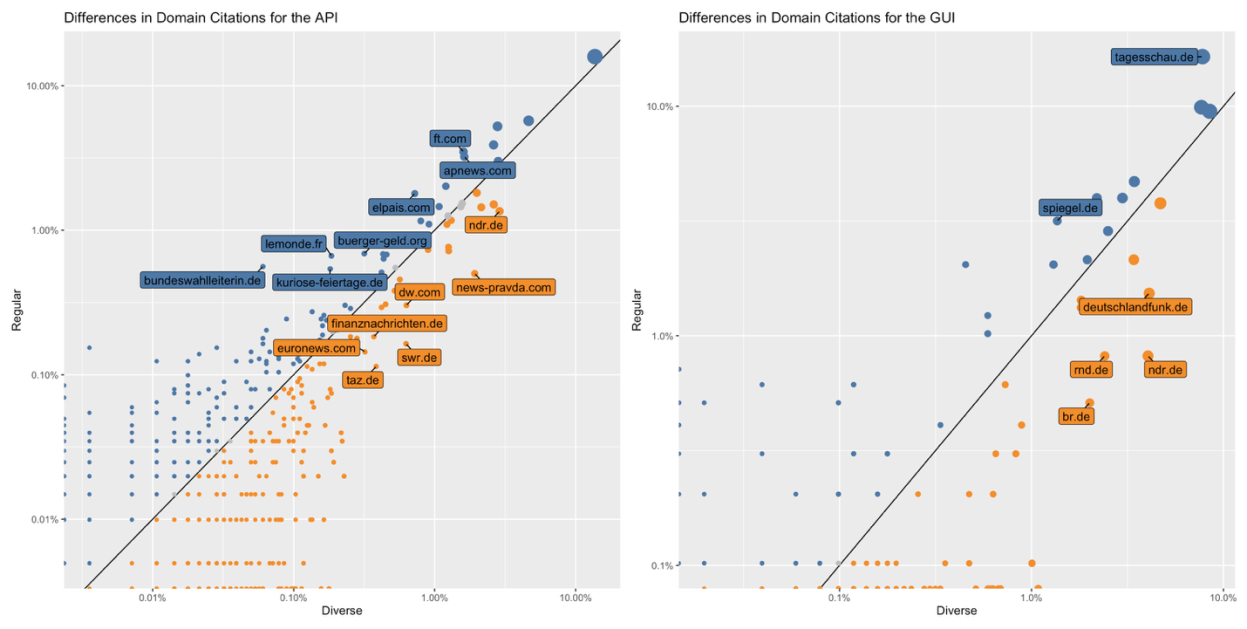
Das Web-Interface produzierte Ergebnisse, die stärker mit etablierten Popularitätsmessungen des deutschen Nachrichtenmarkts übereinstimmten. Die Überschneidung mit Medien aus dem Reuters Digital News Report 2025 betrug 45,5 Prozent gegenüber nur 27,3 Prozent bei der API.
Die Wissenschaftler:innen dokumentierten auch, dass öffentlich-rechtliche Sender im Web-Interface prominenter vertreten waren. Diese machten dort etwa 34,6 Prozent der Referenzen aus, während sie über die API nur 12,2 Prozent erreichten.
Anfragen nach Quellenvielfalt führen zu problematischen Ergebnissen
Besonders interessant fielen die Ergebnisse bei Suchanfragen aus, die ausdrücklich eine breite Quellenauswahl verlangten. In diesen Fällen verwies ChatGPT im Schnitt auf 1,4-mal so viele unterschiedliche Webseiten über die API und sogar auf 1,9-mal so viele über das Web-Interface wie sonst. Eine höhere Zahl an Quellen bedeutete jedoch nicht zwangsläufig auch eine bessere Informationsqualität.
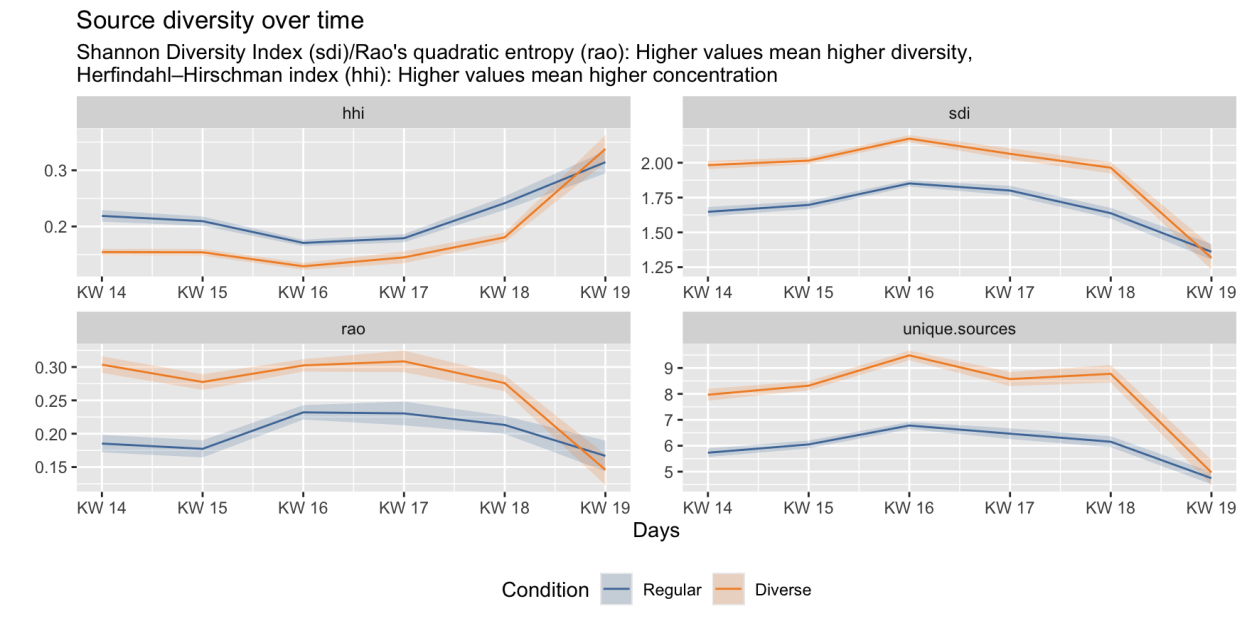
Die Untersuchung zeigt, dass derartige Anfragen häufiger zu Verweisen auf stark politisch gefärbte Nachrichtenseiten und teils propagandistische Medien führten. So wurden laut der Studie auch Portale wie news-pravda.com, das Verbindungen zur russischen Regierung haben soll, überdurchschnittlich oft genannt.
Zudem verlinkte ChatGPT auf nicht existierende Domains wie news-site1.com oder anderesbeispiel.de sowie auf Websites, die Newsseiten kopieren und KI-generierte "Nachrichten" bereitstellen.
Politische Ausgewogenheit trotz problematischer Quellen
Trotz der Einbindung polarisierender Quellen blieb die politische Ausrichtung der referenzierten Outlets laut der Studie ausgewogen. Die durchschnittliche politische Orientierung lag zwischen 3,89 und 3,98 auf einer 7-Punkte-Skala und unterschied sich nicht signifikant vom Bevölkerungsdurchschnitt.
Die Forschenden warnten jedoch davor, dass ChatGPTs Interpretation von "Vielfalt" nicht zwangsläufig informationelle Pluralität bedeute. Das System könne einfach Quellen bevorzugen, die sprachlich stärker vom Mainstream abweichen.
Die Studie verdeutlicht die Intransparenz von ChatGPTs Funktionsweise. OpenAI gibt keine Informationen zu den Unterschieden zwischen Web-Interface und API preis. Für Nutzer:innen bedeutet dies, dass sie kritisches Urteilsvermögen ausüben müssen – die versprochene Entlastung von Informationsüberflutung könne sich ins Gegenteil verkehren. Die Forschenden betonen zudem, dass ihre Ergebnisse nur eine Momentaufnahme darstellen, da OpenAI regelmäßig Änderungen vornimmt, ohne darüber zu informieren.
Die Hamburger Ergebnisse fügen sich in ein größeres Bild der Zersplitterung von KI-Suchen ein: Eine kürzlich veröffentlichte Studie zeigte, dass generative KI-Suchsysteme in vielen Fällen grundsätzlich andere Quellen nutzen als die klassische Google-Suche. Gleichzeitig verbreiten führende KI-Tools mittlerweile doppelt so oft Falschinformationen wie noch vor einem Jahr, da sie nun jede Anfrage beantworten, anstatt bei unsicheren Informationen zu verweigern.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.